Framework per lo sviluppo di applicazioni Web-Oriented, Component & XML Based
|
1 - Presentazione. Il sistema realizzato, successivamente descritto in tutte le fasi di sviluppo del software, consiste in un framework per la creazione di applicazioni web mediante collegamento e coordinamento di componenti software e realizzazione separata dell'interfaccia utente. I passi per realizzare un'applicazione per l'infrastruttura prodotta possono essere sinteticamente riassunti nei seguenti:
L'infrastruttura realizzata trae il massimo vantaggio dal linguaggio interpretato Java e dalle potenzialità del metalinguaggio XML. In particolare, grazie all'utilizzo dei meccanismi di Reflection di Java, l'infrastruttura è infatti in grado di realizzare un'applicazione qualsiasi non predeterminata a compiletime. Ciò ha consentito ai successivi sviluppi dell'infrastruttura di aggiungere la capacità di cambiare l'applicazione a runtime, nonché di realizzare più applicazioni diverse contemporaneamente che possono essere aggiunte, rimosse e modificate sempre a runtime. Questo secondo ciclo di sviluppo del software ha quindi testimoniato la bontà del progetto iniziale qui descritto. Per quanto riguarda invece l'utilizzo intensivo del metalinguaggio XML all'interno dell'infrastruttura, esso garantisce una flessibilità completa necessaria per potere trattare dati non noti a priori sui quali non sarebbe possibile fare alcuna ipotesi. Trattandosi poi di dati formalmente strutturati essi possono essere manipolati automaticamente col semplice utilizzo del linguaggio dichiarativo XSL. Più precisamente è possibile modificare in modo anche radicale il comportamento dell'intera applicazione semplicemente modificando un file XSL, poiché l'essenza della logica applicativa non è più cablata all'interno del codice ma è invece estratta e isolata in un documento XSL, lasciando al codice la sola realizzazione di compiti specifici. L'utilizzo di XSL non esaurisce qui i sui vantaggi, bensì li estende alla rappresentazione finale dei dati che può essere la più svariata: si tratterà tipicamente di HTML, ma potrebbe trattarsi di linguaggi diversi per interpreti specifici quali un browser WML, oppure un interprete SVG per la rappresentazione grafica delle immagini, o altre soluzioni ad hoc per contesti particolari. Dalle precedenti considerazioni si comprende che l'infrastruttura realizzata fornisce un framework di sviluppo che si colloca ad un livello superiore rispetto a soluzioni specifiche per la realizzazione di applicazioni web quale, ad esempio, la tecnologia delle Java Server Pages (JSP). Infatti, sebbene la tecnologia JSP consenta di richiamare JavaBean, instanziabili sia a livello di applicazione che di sessione utente, il controllo dell'applicazione è affidato alle pagine JSP stesse, comportando quindi un controllo distribuito e, soprattutto, mescolato con tutta la problematica di visualizzazione. La presente infrastruttura, invece, separa nettamente gli aspetti di controllo da quelli di visualizzazione consentendo un più razionale sviluppo dell'applicazione, maggiormente percepibile all'aumentare del grado di complessità del problema. Inoltre, in virtù dell'utilizzo di XML e XSL, si possono trattare dati molto più complessi da inserire all'interno dell'output senza dovere ricorrere all'introspezione delle singole proprietà di un JavaBean; sempre grazie a XML e XSL, è infine possibile una gestione decisamente più flessibile per la fase di visualizzazione dell'output aprendo la fruizione dell'applicazione al di là dei comuni browser di pagine HTML. In riferimento ai JavaBean va inoltre precisato che le richieste dell'infrastruttura si limitano unicamente alla presenza di un costruttore di default, quindi è molto semplice integrare una qualunque classe Java realizzata in precedenza.
La progettazione della soluzione è stata preceduta da una attenta fase di analisi attraverso la quale si è giunti a delineare l'architettura logica del sistema. Questa fase di analisi, come la successiva fase di progetto, è stata condotta con l'ausilio di diagrammi UML. Questi diagrammi hanno consentito di produrre delle viste standard del sistema che mettessero in chiara evidenza i componenti fondamentali e le loro relazioni e dipendenze. E' quindi possibile affermare che i diagrammi UML hanno costituito un valido e indispensabile strumento di analisi e progetto, motivo per il quale nella presente relazione si è dedicato la maggior parte dello spazio proprio a questi diagrammi che meglio sintetizzano la struttura e la dinamica del sistema. L'utilizzo di UML è stato coerente e continuativo in tutte le fasi di sviluppo e se ne può trovare una chiara traccia nel codice prodotto. Nell'analisi e progetto del sistema si è poi attinto ad alcuni pattern che hanno consentito di individuare una valida soluzione a problemi specifici. In particolare l'intera fase di analisi è stata ispirata al pattern MVC e ciò ha inciso in modo determinante sull'architettura scelta per questa infrastruttura. Successivamente sono stati adottati i pattern Singleton e Object Pool rispettivamente per centralizzare la configurazione del sistema e per introdurre parallelismo nella gestione degli utenti. In merito alle tecnologie adottate, esse riguardano il linguaggio Java con particolare riferimento ai JavaBean, alla Reflection e alla gestione degli eventi; XML e le specifiche JAXP per la manipolazione del DOM associato all'XML; XSL per la trasformazione dei documenti del sistema e per la realizzazione della presente relazione; le Servlet Java e l'ApplicationServer Tomcat per la realizzazione dell'interfaccia web e il deployment dell'applicazione; HTML, XHTML e CSS.
La presente documentazione è stata scritta secondo le specifiche XHTML Strict (http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd). Se da un lato è stato richiesto un maggiore controllo sul codice, questa scelta ha prodotto indubbi benefici. Infatti trattandosi di codice HTML esso è direttamente visualizzabile da un browser e formattabile con un CSS collegato. Tuttavia, trattandosi di codice XML esso è al contempo trasformabile con uno XSL. In particolare lo XHTML originale è stato trasformato con un XSL appositamente sviluppato (docBuilder.xsl) in grado di generare la barra laterale di navigazione nonché paginare l'intero testo suddividendolo nelle sue sezioni grazie al riconoscimento dei blocchi di testo (tag div). Vengono anche gestiti i riferimenti interni al documento paginato, nonché la numerazione dei paragrafi e delle figure nei riferimenti. Il codice prodotto è ancora conforme alle specifiche XHTML. Per quanto riguarda invece la rappresentazione dei documenti XML in HTML con l'evidenziazione degli elementi sintattici, si è sviluppato un altro XSL (xml2html.xsl) in grado di generare il codice HTML necessario. Ai tag di tale HTML vengono assegnate opportune classi in modo da poter formattare diversamente, ed in modo flessibile gli elementi significati dello XML originale.
Gli sviluppi per questa applicazione hanno già portato alla realizzazione di una versione evoluta capace di sfruttare la potenza elaborativa di più macchine collegate fra le quali ripartire il carico di utenti. Inoltre fra le novità più interessanti spicca la possibilità di eseguire contemporaneamente più applicazioni sull'infrastruttura e la capacità di modificare, aggiungere e rimuovere le applicazioni a tempo di esecuzione. 2 - Obiettivo.
Il progetto sviluppato, e che verrà successivamente descritto, fa parte di un progetto più ampio il cui obiettivo iniziale può essere sintetizzato nella realizzazione di un sistema software che consenta ad un'azienda di vendere prodotti on-line. A partire da questo obiettivo, che rappresenta la richiesta del committente, si è voluto sviluppare un progetto di più ampio respiro mirante alla costruzione di una piattaforma riutilizzabile per lo sviluppo di applicazioni web-oriented. Contestualmente si è voluto che anche la realizzazione della business logic per la specifica applicazione richiesta contenesse un elevato grado di modularità, tale da costituire una soluzione non solo per il caso in essere, ma piuttosto per una più ampia classe di problemi. Lo scopo del presente progetto consiste nella realizzazione del framework citato su cui verrà poi realizzata l'applicazione richiesta nonché altre future applicazioni, anche di natura assai diversa. Questo è quindi il contesto cui d'ora in avanti si farà riferimento, a partire dalla seguente descrizione dell'obiettivo. Viceversa in fase di analisi dei requisiti ci si riferirà marginalmente al contesto più ampio al fine di motivare la decisione, qui brevemente esposta, di dividere il progetto originario in due sotto-progetti.
Si richiede la realizzazione di una piattaforma software attraverso la quale potere realizzare facilmente applicazioni mediante semplice integrazione di componenti eventualmente già sviluppati in precedenza. L'infrastruttura da progettare deve inoltre realizzare un interfaccia web al fine di rendere accessibili le applicazioni agli utenti attraverso un collegamento remoto a internet 3 - Analisi dei Requisiti. Come già accennato, in questa sezione si farà brevemente riferimento al progetto complessivo che riguarda la realizzazione di un software per la vendita on-line di prodotti. A partire da questo contesto si possono evidenziare separatamente requisiti esterni e requisiti interni. I primi costituiscono l'analisi del comportamento desiderato del sistema in base ai desideri del committente; per la specifica applicazione si parlerà di listino prodotti, di ordini d'acquisto, di autenticazione dei clienti, ecc... Si tratta però di questioni che non riguardano l'infrastruttura software obiettivo di questo progetto; per questo si passa direttamente ad analizzare i requisiti interni, ispirati cioè da considerazioni di convenienza inerenti il processo interno di produzione del software. E' dall'analisi di questi requisiti che emergerà la motivazione per lo sviluppo della presente infrastruttura.
Dalle esperienze maturate e dalla prassi ormai consolidata nell’ambito dell’ingegneria del software, si richiede che il software prodotto sia costituito di componenti, ciascuno affidato alla soluzione di uno specifico problema. Questo approccio se portato a termine con coerenza consente:
I precedenti punti devono essere considerati requisiti fondamentali del sistema software da progettare, e devono guidare l’analisi e il progetto di tale sistema. Quindi, riferendosi alla realizzazione del sistema di vendita on-line di prodotti in quest'ottica, l’analisi conduce alla seguente logica suddivisione del problema:
Si noti come questa suddivisione possa costituire una valida base per una razionale pianificazione del lavoro che ripartisca il carico lavorativo fra due diversi team, valorizzando in questo modo le competenze specifiche degli sviluppatori e consentendo una realizzazione in parallelo del sistema complessivo (previa stesura della specifica di integrazione). Per ciò che riguarda lo sviluppo dei componenti citati, si richiede che essi siano focalizzati sui servizi da offrire, ossia che risultino il più possibile svincolati dal contesto nel quale si troveranno ad operare, si vuole cioè poter riutilizzare i componenti che saranno implementati in ambiti anche sensibilmente diversi da quello dell’applicazione che si sta sviluppando. Si dovrà quindi mirare alla soluzione non solo dello specifico problema ma piuttosto di una classe di problemi (ad esempio anziché focalizzarsi sull'effettuazione di un ordine d'acquisto, si cercherà di sviluppare un componente atto alla gestione di un più generico problema di prenotazione di una risorsa). Se è vero che dei componenti generici ben fatti consentono un buon riutilizzo del software, si desidera che anche il "collante", cioè l'infrastruttura che li collega e li fa cooperare, possa essere efficacemente riutilizzata. Per questa infrastruttura, obiettivo specifico di questo progetto, si delineano quindi i seguenti requisiti:
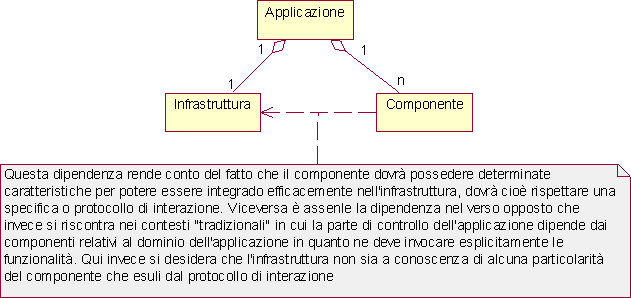
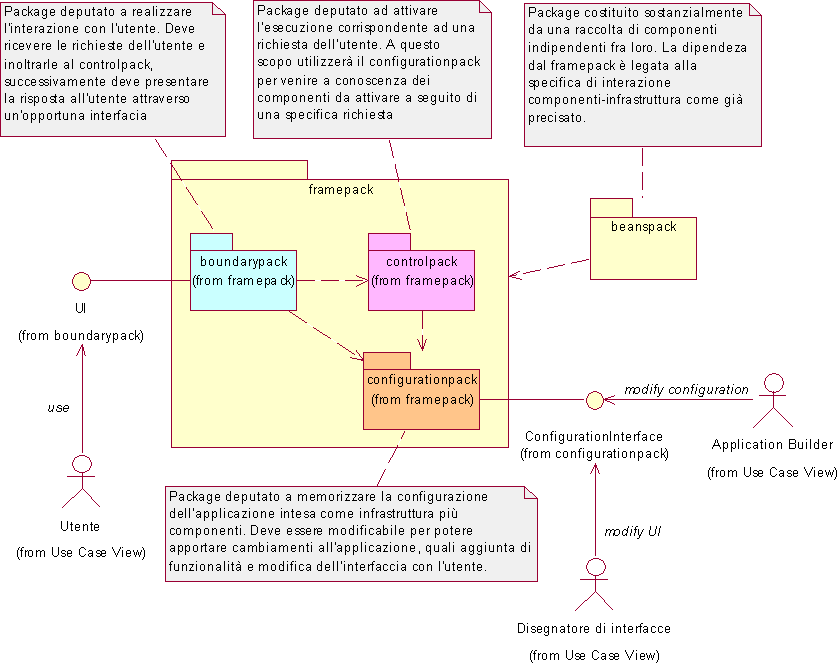
Particolare enfasi è posta sul requisito R2 in cui ci si riferisce all’infrastruttura come un’invariante nella realizzazione di applicazioni. A questo proposito si dovrà sviluppare un’opportuna specifica (o protocollo di interazione) fra l’infrastruttura e i componenti in modo tale che in futuro sia possibile scrivere altre applicazioni semplicemente realizzando componenti conformi a detta specifica e integrando tali componenti in modo opportuno. Si richiede cioè (R8) che l’infrastruttura non dipenda dai componenti, ma che possa essere utilizzata con componenti diversi senza necessità di disporre dei suoi sorgenti per ricompilare il codice. In questo modo, l'infrastruttura, che sarà utilizzata nelle realizzazione della presente applicazione, costituirà anche un prodotto software a sé stante, quindi oggetto di vendita a terzi. Alla luce delle precedenti considerazioni, è possibile dare una rappresentazione della struttura dell’applicazione richiesta attraverso il seguente diagramma UML.
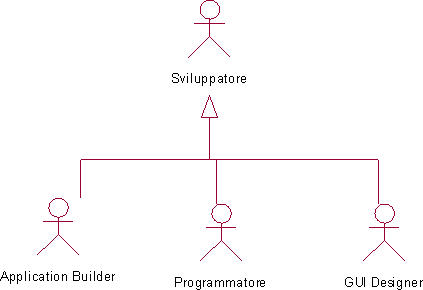
In relazione all'applicazione di vendita on-line di prodotti l'analisi dei casi d'uso deve specificare la gerarchia di attori Utente che si troveranno ad utilizzare l'applicazione come descritto dal seguente semplice diagramma UML.
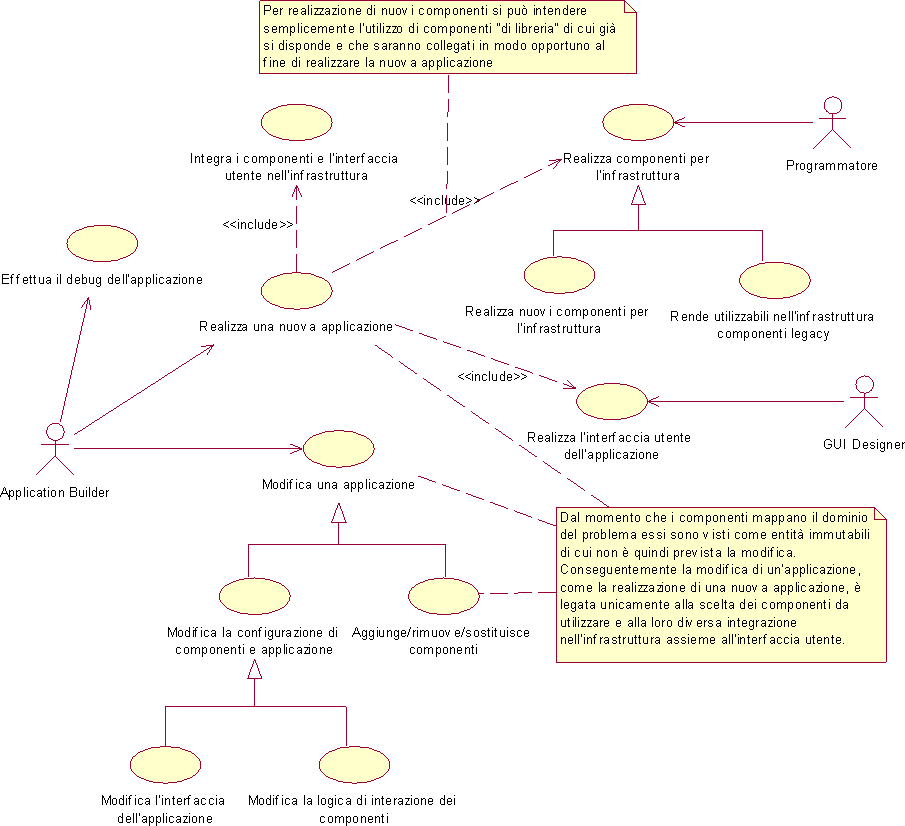
Un'analisi più approfondita di questi casi d'uso non è però compito del presente progetto che deve invece occuparsi dello studio dei casi d'uso relativi alla gerarchia di attori Sviluppatore, ossia di coloro che svilupperanno l'applicazione sull'infrastruttura software da realizzare. Coerentemente col requisito R5, e nell'ottica di una separazione e valorizzazione delle competenze specifiche, si evidenziano due distinte sottocategorie dell'attore Sviluppatore: gli attori Programmatore e gli attori GUI Designer. I primi sono deputati allo sviluppo dei componenti software che realizzano la business logic dell'applicazione, ai secondi invece è richiesta la creazione di un interfaccia grafica che costituirà il front-end presentato all'utente dell'applicazione.
Nel precedente diagramma è stato inoltre evidenziato un terzo attore, l'Application Builder, cui si affida il compito di integrazione delle precedenti parti di interfaccia e logica di esecuzione per produrre il sistema finale. Si può ragionevolmente ipotizzare che questo attore si costituito da un team misto di programmatori e disegnatori di interfacce. Il seguente diagramma chiarisce meglio i vari casi d'uso relativi all'infrastruttura da sviluppare.
4 - Analisi del sistema
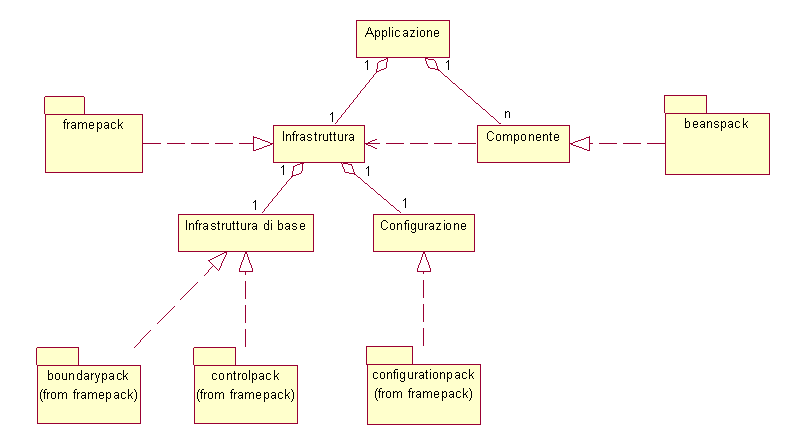
In fase di analisi dei requisiti interni è stata posta una struttura di massima
dell'applicazione, rappresentata nel diagramma UML di figura 4.1,
che sarà qui oggetto di analisi per potere essere specificata in una completa architettura logica
del sistema software che dovrà essere prodotto. Per quanto concerne l'infrastruttura, risulta
opportuno evidenziarne due sottoparti: una, invariante, che verrà indicata come 'Infrastruttura
di base', l'altra, detta 'Configurazione', che rappresenta
invece quella parte dell'infrastruttura che deve essere modificata al fine di realizzare applicazioni
diverse con gli stessi componenti, garantendo così quella flessibilità richiesta dai requisiti.
L'infrastruttura, a seguito della ricezione di una richiesta da parte di un utente deve gestire due aspetti fondamentali:
Entrambe le precedenti operazioni non possono essere cablate all'interno della logica dell'infrastruttura altrimenti per riutilizzare questa infrastruttura in una nuova applicazione sarebbe necessario ricompilarla. Ma quest'ultima ipotesi è in contrasto col requisito R8 che richiede la realizzazione dell'infrastruttura come prodotto software a sé stante. Conseguentemente si deve lasciare la possibilità di modifica sia della logica di attivazione dei componenti, che della logica della loro visualizzazione, allo sviluppatore. Questa logica sarà descritta attraverso un apposito linguaggio e sarà interpretata e gestita dal configurationpack. Questo linguaggio dovrà sostanzialmente esprimere un mapping 'richiesta utente - azioni da compiere' con cui potere determinare il cambiamento di stato dell'applicazione a seguito di una richiesta dell'utente. Il controlpack e il boundarypack utilizzeranno il configurationpack per determinare le azioni da compiere, quindi le porteranno a termine. In questo modo il configurationpack realizza il disaccoppiamento fra infrastruttura di base e componenti.
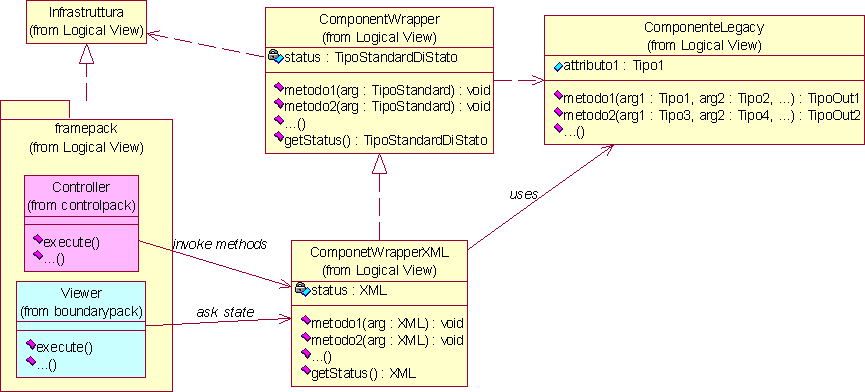
Delineata la macrostruttura dell'applicazione, si passa ad analizzare l'integrazione dei componenti nell'infrastruttura, dal momento che le scelte relative a questo aspetto risulteranno fondamentali per lo sviluppo dei componenti e per le caratteristiche stesse del sistema software da realizzare. Tale integrazione risulterà tanto più agevole quanto meno complessa è la specifica di interazione con l'infrastruttura. Un'interfaccia molto poco specificata e un protocollo di interazione molto semplice consentono infatti di realizzare componenti molto generici che possano essere riutilizzati anche in altri contesti dove non sia presente questa particolare infrastruttura. Inoltre risulta semplificato anche l'integrazione di componenti legacy all'interno dell'applicazione mediante wrapping. Per queste ragioni si vuole limitare il protocollo di interazione alla semplice definizione del passaggio dei parametri e dello stato del componente.
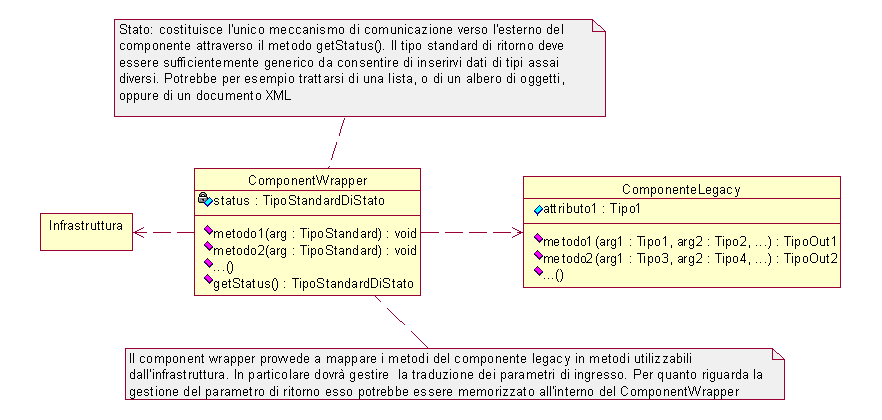
Dal momento che si è deciso di non fare alcuna particolare ipotesi su infrastruttura e componenti, è evidente che l'infrastruttura non potrà conoscere i tipi dei parametri richiesti dai componenti e parimenti non saprà trattare alcun valore di ritorno dal momento che non ne conosce la semantica. Quindi i metodi che dovrà esporre un componente dovranno essere del tipo void nomeMetodo(parametri: TipoStandard) Per le stesse ragioni non saranno utilizzabili eventuali attributi pubblici dei componenti. L'utilizzo di un componente legacy all'interno dell'infrastruttura dovrà quindi essere mediato da un ComponentWrapper che operi le necessarie traduzioni e realizzi il disaccoppiamento delle dipendenze fra infrastruttura e componente legacy, come illustrato in figura 4.3.
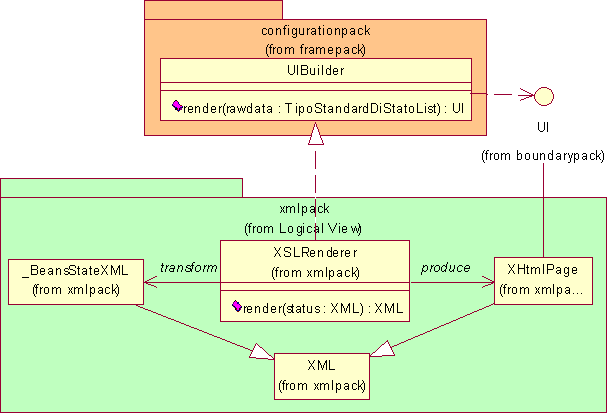
Dal momento che i metodi non ritornano alcun valore, è necessario sviluppare un meccanismo standard per ottenere lo stato del componente. A tale scopo è preposto il metodo getStatus() che restituisce un TipoStandardDiStato. Lo stato costituisce anche il punto di partenza per la visualizzazione dell'applicazione all'utente, dal momento che contiene i dati grezzi che dovranno essere rappresentati all'utente. In fase di progetto sarà necessario approfondire questo meccanismo e valutarne la fattibilità.
Per realizzare un'infrastruttura che possa risultare utile e conveniente per chi sviluppa applicazioni, è necessario fornire dei meccanismi di interazione fra i componenti. Al fine di garantire una buona flessibilità è opportuno realizzare due diversi meccanismi:
Si procede all'analisi del sistema per package individuando per ciascuno di essi i compiti da risolvere che saranno mappati in classi con competenze specifiche. Per prima cosa si analizza il boundarypack che deve farsi carico della gestione delle problematiche correlate all'interazione con l'utente e per il quale si prevede la seguente struttura di base.
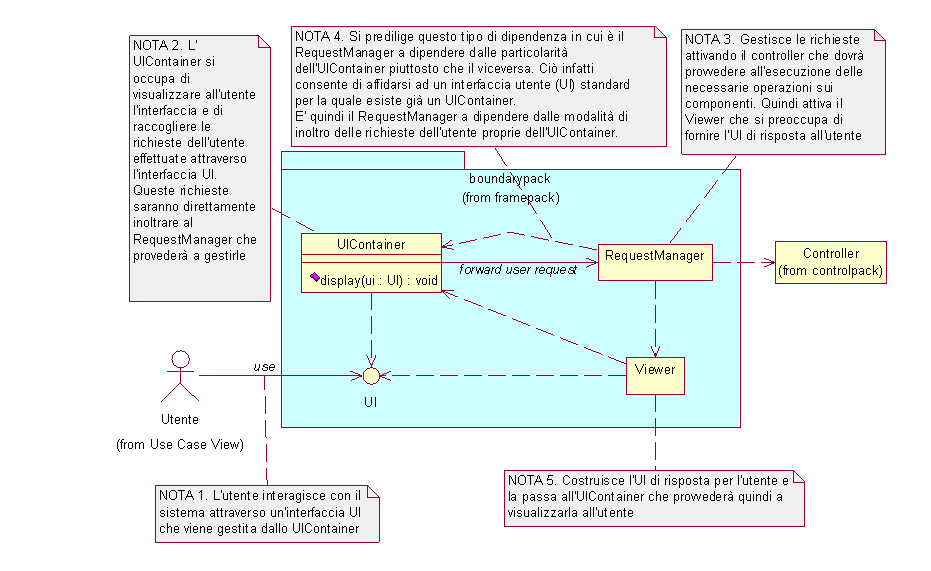
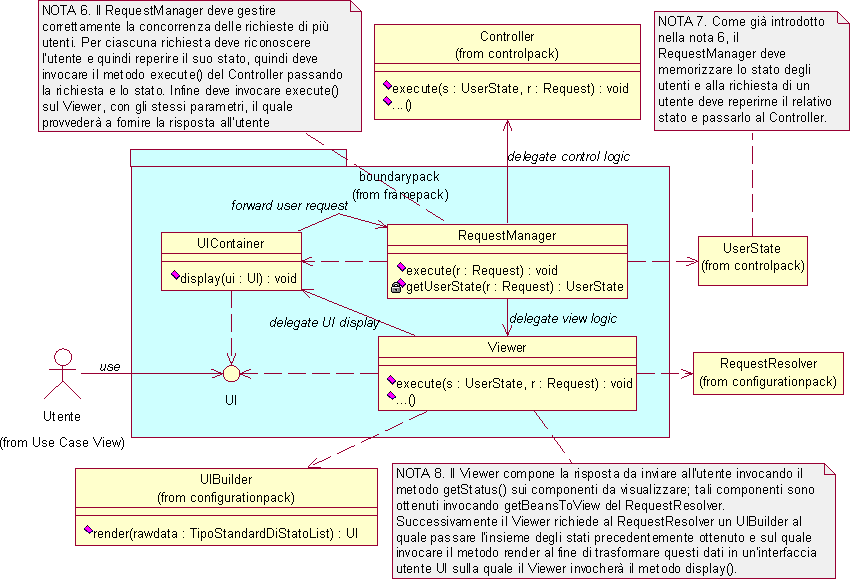
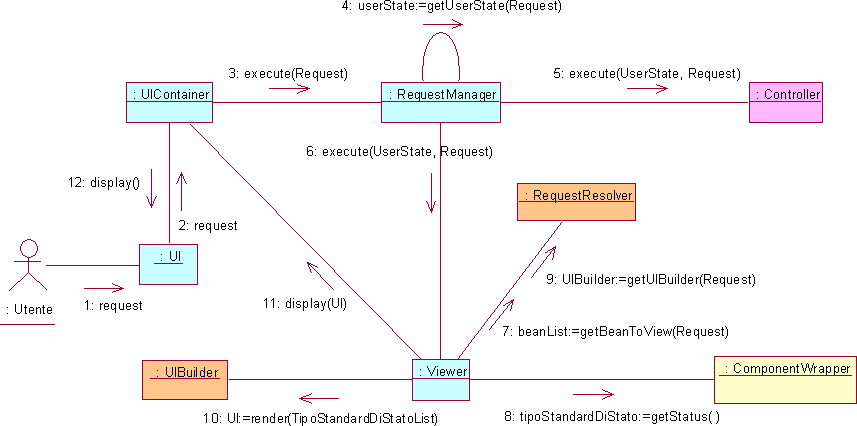
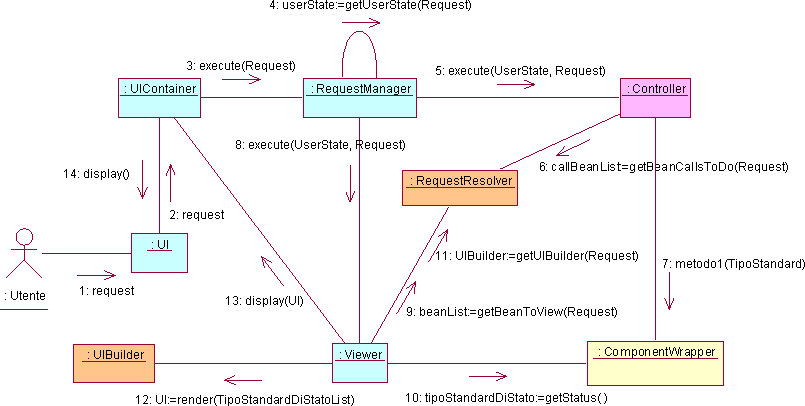
Visto il contesto di multiutenza posto in luce dall'analisi dei requisiti emerge immediatamente un ventaglio di problematiche relative alla gestione delle richieste che viene affidata alla classe RequestManager. Un primo aspetto da considerare riguarda la concorrenza delle richieste la cui trattazione viene rimandata alla fase di progetto dove si valuteranno i migliori strumenti atti a garantire la correttezza dell'esecuzione di richieste parallele (al limite si può ricorrere alla serializzazione delle richieste). Un'altra problematica legata alla multiutenza riguarda il riconoscimento dell'utente a cui appartiene la richiesta e la relativa gestione dello stato. In particolare se l'utente non è nuovo si dovrà provvedere, mediante il metodo getUserState(), a recuperare lo stato precedentemente collegato a quell'utente e a passarlo al Controller perché le operazioni da eseguire vengano effettuate su questo specifico stato. Dopo aver gestito questi aspetti, il RequestManager dovrà provvedere a invocare il metodo execute() del Controller per scatenare l'elaborazione, quindi, successivamente, il metodo execute() del Viewer che provvederà a restituire la nuova rappresentazione all'utente. Come ultima considerazione va detto che, anche se i compiti di questa classe sono di "controllo", si è deciso di inserire la classe nel boundarypack piuttosto che nel controlpack, dal momento che essa risulta dipendente dalla interfaccia scelta per l'applicazione, in particolare dall'UIContainer e dai suoi meccanismi di interazione per il passaggio delle richieste da eseguire. Per questo motivo è da considerarsi classe di "confine" (boundary) poiché maschera al nucleo del sistema (Controller) le particolarità dell'ambiente software legato all'interazione con l'utente.
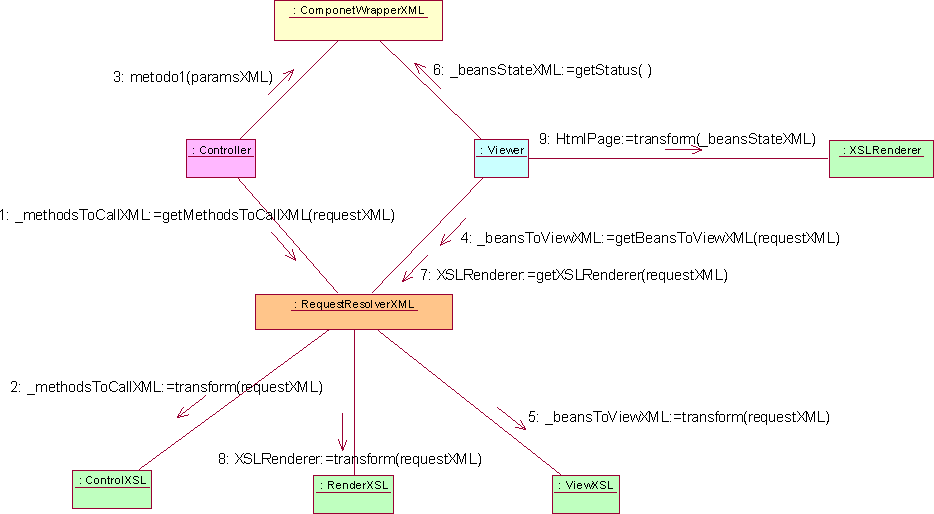
Le problematiche di visualizzazione all'utente sono affidate alla classe Viewer che deve anzitutto ottenere i dati elementari da visualizzare: tali dati sono contenuti nello stato dei componenti installati nel sistema che è reperibile attraverso il metodo getStatus() dei componenti secondo quanto discusso al paragrafo 4.2.2. Il passo successivo comporta la renderizzazione dei dati per ottenere la rappresentazione voluta da presentare all'utente. Questo disaccoppiamento fra dati elementari da rappresentare e renderizzazione degli stessi fornisce un'ulteriore grado di libertà all'attore Sviluppatore che può modificare la sola interfaccia utente dell'applicazione senza modificare la logica di visualizzazione dei componenti. Sia la determinazione dei componenti da visualizzare sia la loro particolare renderizzazione, non potranno essere parte integrante e immutabile della infrastruttura poiché altrimenti non si potrebbero realizzare con questa infrastruttura applicazioni diverse o modificare facilmente la rappresentazione di un'applicazione come invece richiesto esplicitamente dai requisiti. Per questo motivo il Viewer interroga la classe RequestResolver del configurationpack, per ottenere sia i componenti dei quali richiedere lo stato a seguito di una richiesta, sia per ottenere un UIBuilder col quale costruire l'interfaccia UI da presentare all'utente a seguito della sua richiesta. Prima di illustrare i diagrammi delle classi, si precisa che la classe UIBuilder è stata inserita nel configurationpack, anziché nel boundarypack come poteva sembrare opportuno visto che è inerente l'interfacciamento col mondo esterno, poiché è direttamente collegata alla costruzione dell'applicazione da parte dello sviluppatore. Questi aspetti saranno comunque approfonditi nell'analisi del configurationpack.
Il seguente diagramma chiarisce quanto descritto anticipando alcune classi che verranno successivamente descritte al fine di iniziare a delineare la dinamica di base del sistema.
Risulta evidente che, affinché l’architettura logica proposta funzioni correttamente,
lo UIBuilder deve produrre un’interfaccia UI attraverso la quale le richieste
dell’utente possano essere raccolte dallo UIContainer e quindi
inoltrate al RequestManager. Lo UIContainer deve però essere progettato senza alcuna dipendenza
dalla particolare interfaccia applicativa UI, poiché se così non fosse il boundarypack non farebbe
parte dell’infrastruttura di base in quanto conterrebbe al suo interno dipendenze dalla specifica
applicazione, quindi apparterrebbe alla parte di configurazione dell’infrastruttura. Perciò
la dipendenza fra UIContainer e UI si realizzerà secondo un protocollo
standard di più alto livello mentre sarà la UI stessa a contenere le particolarità applicative
delle richieste da eseguire a seguito di una azione dell’utente; lo UIContainer si occuperà
di conseguenza solo dell’inoltro della richiesta al RequestManager. Si noti come un simile modello
è quello che si riscontra con le pagine HTML e il browser
di tali pagine.
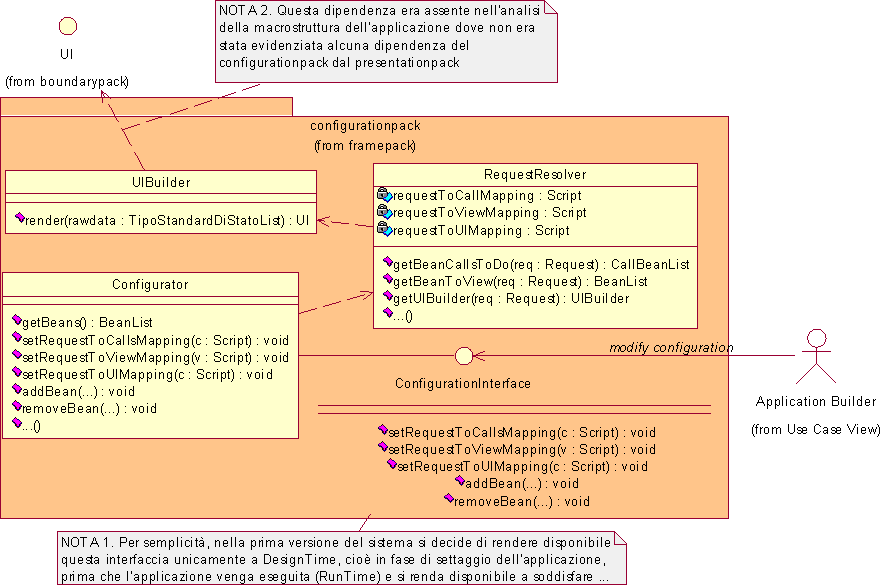
Il configurationpack svolge un ruolo cruciale nel sistema software da sviluppare. In esso infatti è contenuto il 'collante' che collega e coordina i componenti in modo opportuno al fine di realizzare, con l'infrastruttura, l'applicazione desiderata. Questo collante è costituito fondamentalmente da:
Il configurationpack deve da un lato memorizzare le precedenti proprietà dell'applicazione e consentire ad uno Sviluppatore di modificarle, dall'altro deve rendere disponibile dette proprietà agli altri package dell'infrastruttura affinché possano gestire le richieste dell'utente. Questo consente di disaccoppiare l'infrastruttura dalla particolare applicazione realizzata in accordo coi requisiti.
Il configurationpack deve essere in grado di indicare agli altri package dell'infrastruttura:
In particolare il punto 1) indica la funzionalità che sarà richiesta dal controlpack, mentre i punti 2) e 3) riguardano gli aspetti legati alla visualizzazione già discussi nell'ambito dell'analisi del boundarypack. Queste funzionalità vengono realizzate dalla classe RequestResolver.
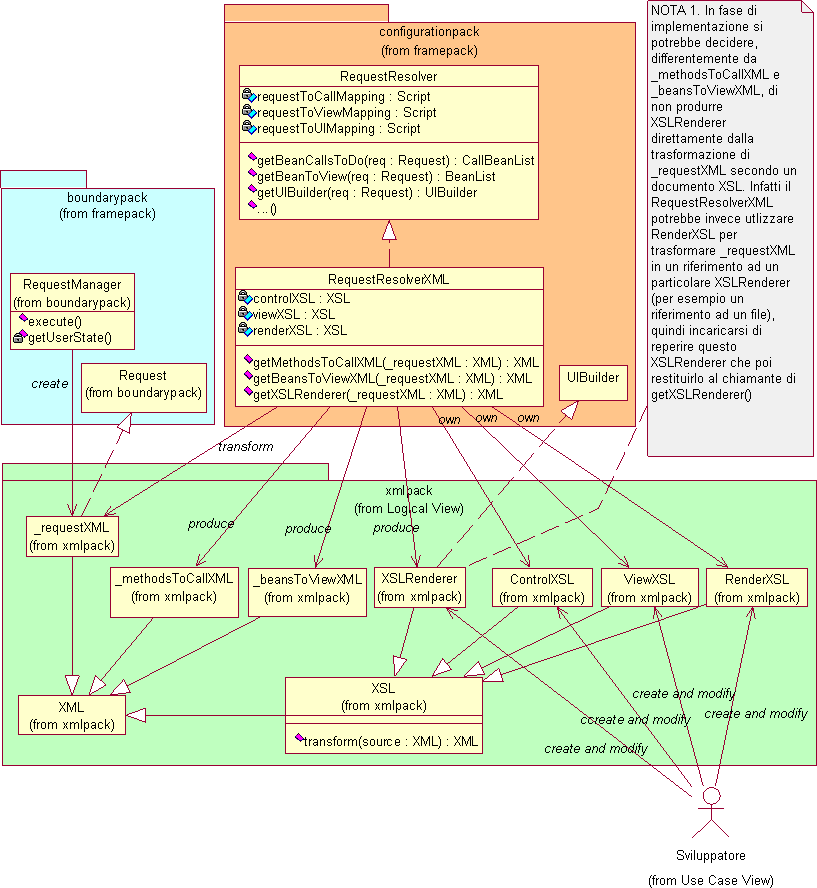
Per realizzare le precedenti funzionalità, il RequestResolver deve basarsi sui dati forniti dallo Sviluppatore in merito al funzionamento desiderato per l'applicazione. Come già introdotto al paragrafo 4.1.2, emerge la necessità di fornire allo Sviluppatore un linguaggio appropriato attraverso il quale egli possa esprimere la configurazione desiderata dei componenti e la logica di interazione degli stessi a seguito di una specifica richiesta dell'utente. Lo Sviluppatore dovrà quindi realizzare dei piccoli script per integrare i componenti nell'infrastruttura realizzando così l'applicazione voluta. Tali script saranno gestiti dal RequestResolver che li interpreterà ed esporrà i metodi getBeanCallsToDo(), getBeanToView() e getUIBuilder() per rendere disponibili le informazioni in essi contenute alla infrastruttura di base. Si rimanda alla fase di progetto la scelta del particolare linguaggio che potrà essere progettato allo scopo, oppure si potrà optare per l'utilizzo di un linguaggio standard già esistente.
Lo Sviluppatore utilizza l’interfaccia ConfigurationInterface per modificare i precedenti script, per aggiungere e rimuovere i componenti, per modificare i meccanismi di interazione di un componente con gli altri. Si pone il problema di stabilire in quali condizioni è opportuno consentire la modifica dell’applicazione. In merito a questa problematica non era stato definito alcun requisito esplicito, tuttavia i requisiti di modificabilità erano stati posti al fine del riutilizzo del codice in altre applicazioni piuttosto che per la modifica a runtime dell’applicazione. D’altra parte è verosimile che in alcuni contesti, si pensi ad esempio al web, potrebbe risultare utile la modifica di parte dell’applicazione, e in particolar modo dell’interfaccia, contestualmente alla continuazione del servizio offerto agli utenti. Tuttavia, per semplicità, si decide di demandare la gestione di questi aspetti ad una versione successiva del sistema (vedi sviluppi futuri).
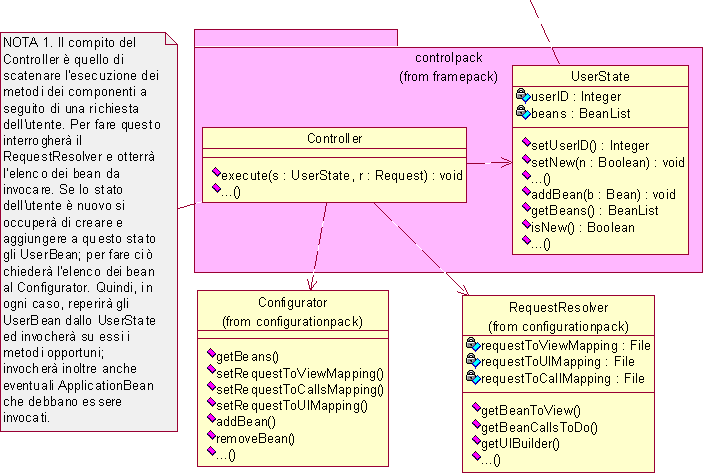
Il Controller è la classe fondamentale del controlpack, deputata ad invocare i metodi dei componenti. La logica che determina quali metodi di quali componenti devono essere invocati a seconda della richiesta risiede nel RequestResolver, del quale il Controller invoca il metodo getBeanCallsToDo(Request) ottenendo un insieme di riferimenti a bean con relativi metodi che provvederà ad invocare.
Il concetto di stato associato ad un utente impone delle considerazioni. Dal momento che l'infrastruttura è una pura struttura atta a semplificare la realizzazione dell'applicazione, ad essa non è collegato alcuno stato interessante per l'utente. Lo stato dell'utente è invece collegato allo stato degli oggetti del dominio dell'applicazione. Nello specifico del sistema software che si sta analizzando gli oggetti del dominio dell'applicazione sono i componenti e quindi lo stato dell'utente è dato dall'insieme degli stati dei componenti. Tuttavia possono essere presenti alcuni componenti che svolgono funzioni importanti per l’applicazione del suo insieme e che possono non contenere alcuno stato direttamente riconducibile ad uno specifico utente. Si chiameranno questi ultimi componenti ApplicationBean, mentre quelli collegati ad un utente saranno detti UserBean. Va precisato che questa distinzione non è legata tanto al componente in sé, quanto all'uso che ne viene fatto: uno stesso componente (per esempio un contatore) può essere istanziato in due differenti oggetti: uno UserBean e un ApplicationBean. Dal momento che l'infrastruttura deve gestire la multiutenza si pone il problema di definire delle regole di visibilità in modo che le operazioni effettuate da un utente non si riflettano sugli altri utenti. Per questo motivo si introduce la classe UserState deputata al mantenimento dello stato dell'utente, la cui gestione è affidata al RequestManager che si preoccupa di mantenere e reperire lo stato di ciascun utente mediante un identificativo unico. Reperito il corretto oggetto UserState, costituito dall'insieme di UserBean dello specifico utente, il RequestManager lo inoltra al Controller; nel caso venga passato uno UserState vuoto significa che si tratta di un nuovo utente, quindi il Controller dovrà provvedere ad interrogare il configurationpack per ottenere un corretto stato iniziale.
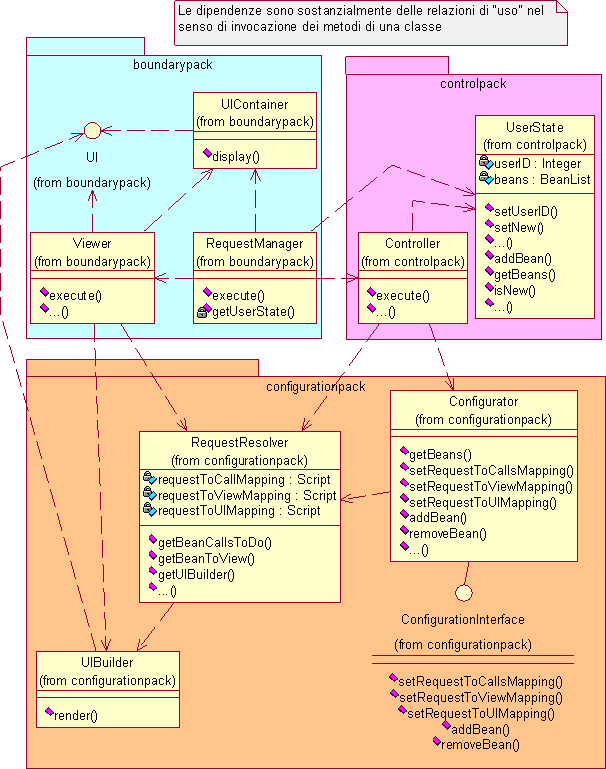
I seguenti diagrammi UML sintetizzano quanto analizzato nel dettaglio e forniscono una visione globale della modellazione statica e dinamica del sistema software. Si noti come si sia cercato accuratamente di limitare le dipendenze fra i package in modo tale che eventuali future modifiche da apportare ad un package comportino il minor numero possibile di cambiamenti sugli altri pacchetti. Rispetto alle dipendenze già individuate in figura 4.2 si è aggiunta quella fra configurationpack e boundarypack emersa fra lo UIBuilder e l'interfaccia UI.
Il sistema evidenziato finora fornisce unicamente delle funzionalità di base necessarie per consentire lo sviluppo di applicazioni. Tuttavia sarebbe opportuno introdurre alcune funzionalità aggiuntive di carattere generale, quindi riutilizzabili in svariati contesti, al fine di meglio supportare gli sviluppatori. Fra le funzionalità desiderabili possono certamente essere annoverate:
Si noti come le funzionalità elencate siano necessarie anche per lo sviluppo dell'applicazione richiesta come evidenziato in fase di analisi dei requisiti interni. Alla luce di questa considerazione, e per testare la validità del modello proposto per la realizzazione di applicazioni basate su questa infrastruttura, si decide di sviluppare queste funzionalità aggiuntive come componenti qualsiasi, ossia normali ApplicationBean. Per quanto riguarda invece il debug degli sviluppatori, in ottemperanza al requisito R7, bisognerà provvedere a dei meccanismi di logging al fine di rendere visibile il flusso esecutivo eseguito dal Controller e dal Viewer sui componenti, nonché per riportare eventuali eccezioni generate. 5 - Progetto. In questa sezione si ripercorrono gli aspetti illustrati in fase di analisi, rapportandoli alle tecnologie attualmente disponibili, al fine di determinare le giuste scelte che conducono ad una buona realizzazione progettuale dell'architettura logica finora delineata.
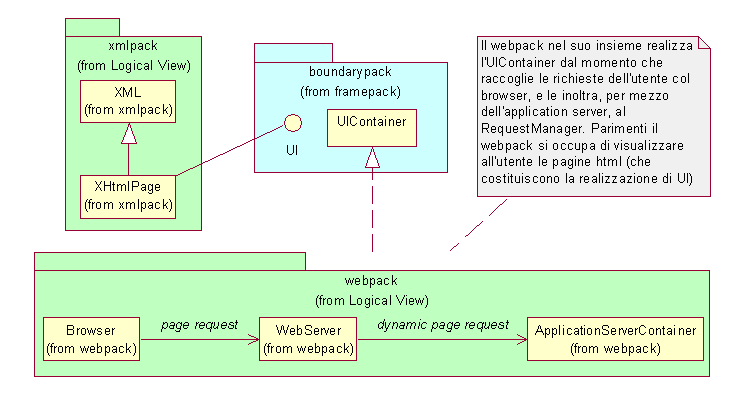
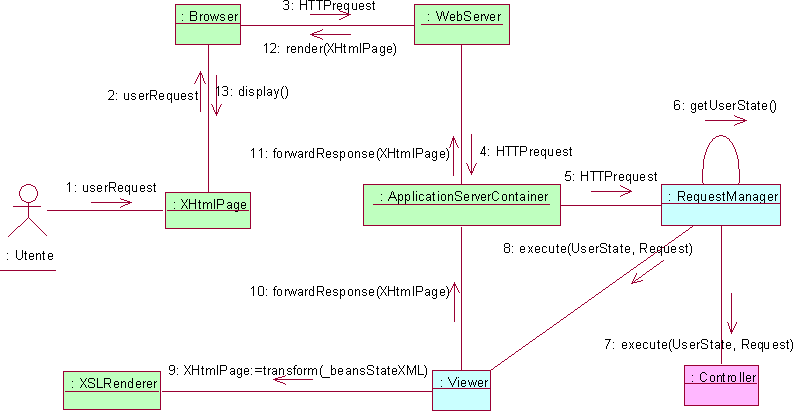
La realizzazione dell’interazione con l’utente può essere efficacemente svolta appoggiandosi alle tecnologie web che supportano bene il modello di interazione proposto in fase di analisi. La UI sarà quindi costituita da una pagina XHTML e lo UIContainer dall’insieme di Browser, WebServer, ApplicationServer, come illustrato nel seguente diagramma.
Questo tipo di soluzione garantisce inoltre un valido supporto per l’accesso remoto alla applicazione, oltre a potere essere sfruttato anche in ambito locale. Inoltre vengono soddisfatti in questo modo anche i requisiti legati alla specifica applicazione per la quale era richiesto esplicitamente di consentire l’accesso degli utente attraverso internet. L’utilizzo di una tale architettura standard e ampiamente consolidata consente inoltre di sgravare dallo sviluppo di questo sistema software tutte quelle problematiche legate alle connessioni remote, fra le quali è di particolare importanza la sicurezza delle transazioni, visto che l’infrastruttura dovrà essere utilizzata per realizzare un’applicazione in cui avvengono delle vendite.
In fase di analisi al paragrafo 4.3.3 si era specificato che la classe UIContainer non doveva conoscere alcuna logica di interpretazione delle azioni dell’utente e generazione delle relative richieste. Tale logica deve invece risiedere direttamente all’interno della interfaccia UI, poiché si era evidenziato che solo in questo modo era possibile isolare unicamente all’interno del configurationpack la parte variabile dell’infrastruttura da applicazione a applicazione. L’utilizzo delle tecnologie web e delle pagine XHTML come interfaccia UI, soddisfa perfettamente questo requisito dal momento che le richieste da effettuare a seguito di un’azione dell’utente sono contenute all’interno della pagina XHTML mentre l’UIContainer, costituito dalla serie di Browser, WebServer e ApplicationServerContainer, è assolutamente standard e indipendente da qualunque pagina.
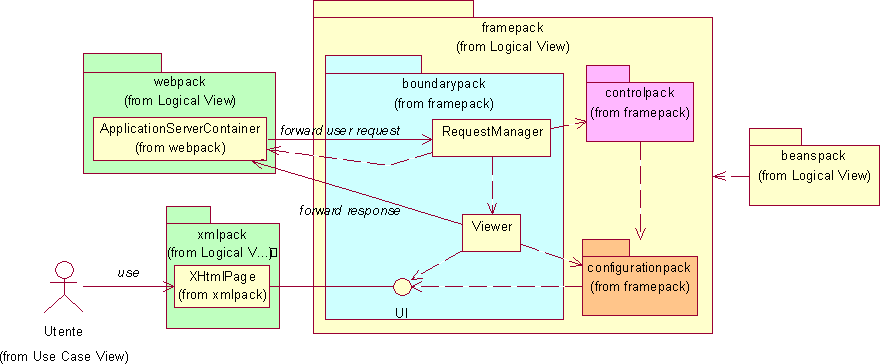
Pur avendo scelto un’interfacciamento con l’utente basato sugli standard web, si vuole mantenere indipendente il resto dell’infrastruttura, quindi il controlpack e il configurationpack. In sostanza sarebbe auspicabile che la sostituzione del boundarypack, necessaria qualora si volesse modificare il contesto o le modalità di interazione dell’infrastruttura col mondo esterno, non necessiti alcuna modifica agli altri package. Questo aspetto era stato evidenziato in fase di analisi nel primo schema della struttura dell’applicazione come illustrato in figura 4.2; tuttavia, nella stessa fase di analisi era emersa la dipendenza del configurationpack dall’interfaccia UI del boundarypack. Ciò si era reso necessario a causa del voluto incapsulamento della logica di visualizzazione all’interno del configurationpack, così da renderne possibile la modifica da parte di un attore Sviluppatore. La situazione è chiarita dal seguente diagramma.
L’indipendenza sopra citata può essere però recuperata. Infatti, ricordando che lo UIBuilder deve creare una UI a partire da dati elementari TipoStandardDiStato, nel momento in cui si realizza UI con XHTMLPage, è logico pensare di utilizzare XML come TipoStandardDiStato e un programma XSL come UIBuilder. Questo tipo di soluzione ha il considerevole pregio di rendere nuovamente indipendente il configurationpack dalla particolare UI utilizzata; infatti il programma XSL è scritto dallo Sviluppatore che crea l’applicazione quindi, nel caso si utilizzi in futuro un’interfaccia utente diversa da XHTMLPage, sarà sufficiente modificare i programmi XSL per ottenere un diverso rendering conforme alla nuova interfaccia UI. Questo scenario è realistico: nei requisiti si parla infatti di vendita on-line di prodotti, ma se oggi per vendita on-line si intende attraverso internet, in futuro questo potrà avvenire attraverso un terminale wireless e l’interfaccia utente WML. Il seguente diagramma illustra quanto discusso.
L’interazione fra utente e infrastruttura, che emerge dall’utilizzo delle tecnologie web a partire dall’architettura logica delineata in fase di analisi, è schematizzata nel seguente diagramma che illustra la dinamica di questa interazione.
La soluzione precedentemente proposta richiede l’utilizzo di XML come TipoStandardDiStato per lo stato dei componenti. Si tratta certamente di un’ottima scelta visto che consente massima flessibilità nella rappresentazione dello stato e difficilmente si potrebbero trovare altre soluzioni in grado di essere utilizzate efficacemente per rappresentare lo stato di componenti anche assai diversi. Per lo stesso motivo è conveniente utilizzare XML anche per rappresentare i parametri di input dei metodi dei componenti. Si sottolinea infine che nessuna ipotesi è stata fatta sul ComponenteLegacy come imposto dai requisiti, quindi risulta utilizzabile qualunque componente, anche già compilato, scritto precedentemente alla realizzazione di questa infrastruttura.
Nei confronti dell’attore Sviluppatore che deve costruire la propria applicazione a partire da questa infrastruttura si è finora deciso di adottare XSL come linguaggio che egli dovrà utilizzare per realizzare gli UIBuilder con cui renderizzare i dati dei suoi componenti. Visto ciò, risulta opportuno adottare lo stesso linguaggio anche per la stesura degli script con cui lo Sviluppatore indica, in corrispondenza di ogni richiesta dell’utente, quali metodi di quali componenti invocare, quali componenti visualizzare, quale XSL utilizzare per il rendering. Questo tipo di soluzione implica che la richiesta dell’utente venga espressa in formato XML in modo da potere essere trasformata con un programma XSL; la traduzione in XML della richiesta è affidata al RequestManager. Infine è necessario redigere una specifica sul formato dei vari documenti XML: _requestXML, _methodsToCallXML, _beansToViewXML. Questa specifica dovrà essere seguita dagli sviluppatori al fine di garantire il corretto funzionamento dei componenti con l’infrastruttura. I seguenti diagrammi illustrano più dettagliatamente come si concretizza il sistema a seguito dell’adozione di XML e XSL, rispettivamente in relazione all’aspetto statico e a quello dinamico.
Come precedentemente accennato devono essere definiti i formati dei diversi documenti XML utilizzati per la programmazione dell’infrastruttura. Anzitutto lo Sviluppatore dovrà manipolare una _requestXML, per la quale si adotta la seguente specifica: <?xml
version="1.0"
encoding="UTF-8"?>
Nel tag requestProperties possono essere inserite dall’infrastruttura delle proprietà della richiesta (per esempio se si tratta della prima richiesta di un nuovo utente, l'URL richiesto, ... ) che i documenti XSL scritti dallo sviluppatore possono testare per stabilire quali componenti invocare e visualizzare. I documenti XML che lo sviluppatore dovrà produrre attraverso i documenti XSL sono _methodsToCallXML e _beansToViewXML per i quali si forniscono rispettivamente le seguenti specifiche, seguite da quella della struttura di base del _beansStateXML che l'infrastruttura si occupa di generare aggregando i risultati dell'invocazione di getStatus() sui vari bean da visualizzare. <?xml
version="1.0"
encoding="UTF-8"?>
<?xml
version="1.0"
encoding="UTF-8"?>
<?xml
version="1.0"
encoding="UTF-8"?>
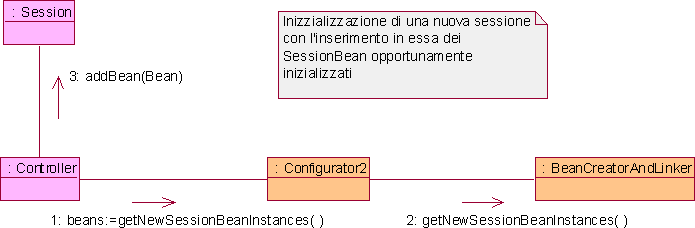
In fase di analisi al paragrafo 4.5.2 erano stati distinti due tipi di componenti, UserBean e ApplicationBean, a seconda che l’istanziazione del componente fosse legata ad uno specifico utente oppure all’applicazione. Si era inoltre specificato che gli UserBean sarebbero stati memorizzati nello stato dell’utente. Nell’ambito delle tecnologie web introdotte in fase di progetto, l’interazione di base con l’utente è stateless e il riconoscimento dell’appartenenza di una richiesta ad un particolare utente è effettuato mediante il concetto di sessione: quando un nuovo utente effettua una richiesta l’ApplicationServerContainer provvede a creare per lui una sessione, quindi, attraverso opportuni meccanismi, riconosce le richieste successive dello stesso utente come appartenenti a questa sessione. Conseguentemente lo stato dell’utente sarà costituito dalla sessione e all’interno di essa saranno memorizzati i componenti dell’utente che si preferisce indicare d'ora in poi con il termine SessionBean piuttosto che UserBean. Il tempo di vita di questi componenti è legato al tempo di vita della sessione, quindi nel momento in cui una sessione scade i SessionBean vengono distrutti. Si pone allora il problema della permanenza dello stato di questi componenti, poiché potrebbe essere necessario recuperare il precedente stato nel momento in cui un utente si ricollega all’applicazione (collegato alla persistenza vi è quindi l’aspetto dell’autenticazione). Seguendo le indicazioni enunciate nell’analisi al paragrafo 4.7, si decide di non sviluppare per l’infrastruttura un meccanismo automatico che provveda alla gestione di questi aspetti, piuttosto si procederà allo sviluppo di ApplicationBean che realizzeranno queste funzionalità. Ciò costituisce un’ulteriore grado di flessibilità poiché l’infrastruttura può così essere utilizzata con meccanismi diversi che gestiscono la permanenza dello stato.
In sede di analisi erano stati individuati due meccanismi per l’interazione dei componenti: la delega e gli eventi. Alla luce della suddivisione dei componenti in SessionBean e ApplicationBean è opportuno analizzare meglio queste modalità di interazione.
Per entrambi i meccanismi di interazione è necessario che il sistema in fase di inizializzazione dei componenti provveda ai necessari collegamenti. In particolare per quanto riguarda gli eventi deve essere eseguita l’operazione "sorgente_eventi.addxxxListener(listener_degli_eventi)" che collega ad un componente un altro componente come listener di un certo tipo di eventi. Per quanto concerne la delega invece è necessario fornire al cliente un riferimento al servitore mediante un’operazione "client.setServer(server)", per cui il cliente deve mettere a disposizione un metodo setServer() che accetta come parametro un oggetto della stessa classe del server, oppure di una superclasse, oppure di un’interfaccia implementata dal server.
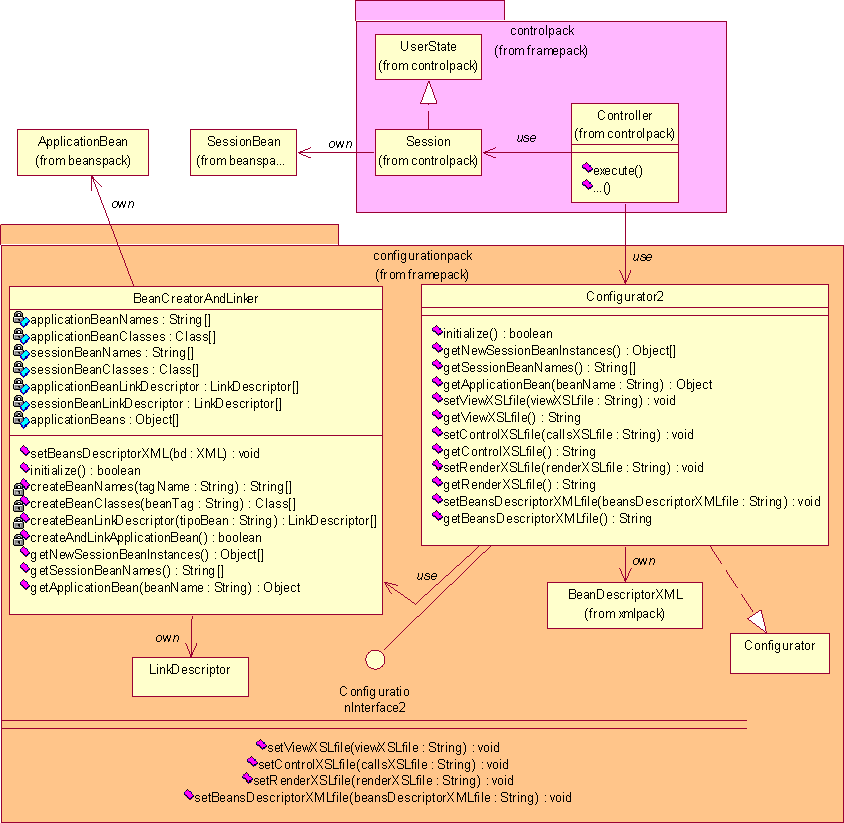
Anche per quanto riguarda la descrizione dei bean installati si utilizza un documento XML. Il documento BeansDescriptorXML deve contenere le indicazioni circa i componenti che devono essere istanziati all’interno dell’applicazione, sia SessionBean che ApplicationBean. Per ogni bean devono poi essere indicati:
Si fornisce quindi la seguente specifica del documento BeansDescriptorXML che deve essere redatto dall’attore Sviluppatore per inserire correttamente i componenti all’interno dell’infrastruttura. <?xml
version="1.0"
encoding="UTF-8"?>
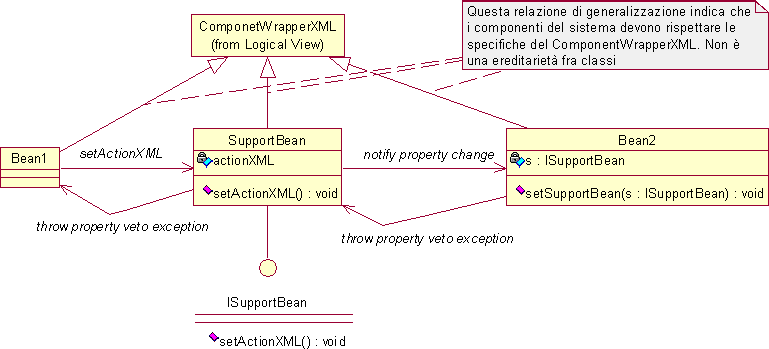
Il limite dell’interazione tramite eventi fra componenti è dovuto al mancato sollevamento degli stessi in corrispondenza di azioni delle quali un nuovo componente che si vuole sviluppare vorrebbe essere informato. Per garantire invece una buona estendibilità dell’applicazione e riutilizzabilità dei componenti scritti è opportuno lanciare eventi dettagliati prima di intraprendere un’azione significativa. Per supportare questa pratica si decide di provvedere ad una standardizzazione realizzando un componente, chiamato SupportBean, che contenga un documento XML indicante l’azione che si intende eseguire. Ogni bean è quindi "invitato" a settare opportunamente questo documento XML prima di effettuare le proprie operazioni, il SupportBean si occuperà quindi di inviare un evento di notifica di cambiamento dell’azione in corso di esecuzione nel sistema agli altri componenti precedentemente registrati presso di sé. Inoltre si consente ai bean che ricevono l’evento di modifica di porre un veto sull’azione lanciando un’eccezione che sarà consegnata dal SupportBean al bean che vuole eseguire l’operazione; sarà cura di quest’ultimo rinunciare all’esecuzione a seguito del veto ricevuto. In fase di implementazione si potrà decidere di aggiungere al SupportBean altre funzionalità che possano essere utili per chi sviluppa componenti. Questo meccanismo potrebbe ad esempio essere efficacemente utilizzato all’atto dell’autenticazione di un utente: un AuthenticationBean setterebbe l’azione a "autenticato, IdUtente=123" quindi tutti i SessionBean che memorizzano in modo permanente il loro stato dovrebbero provvedere a recuperare detto stato, per esempio richiedendolo ad uno StoreBean. Nelle seguenti figure si illustrano il diagramma delle classi, la specifica del documento XML dell’azione (_actionXML), il BeansDescriptorXML relativo all’applicazione costituita dai componenti di questo diagramma delle classi.
<?xml
version="1.0"
encoding="UTF-8"?>
<?xml
version="1.0"
encoding="UTF-8"?>
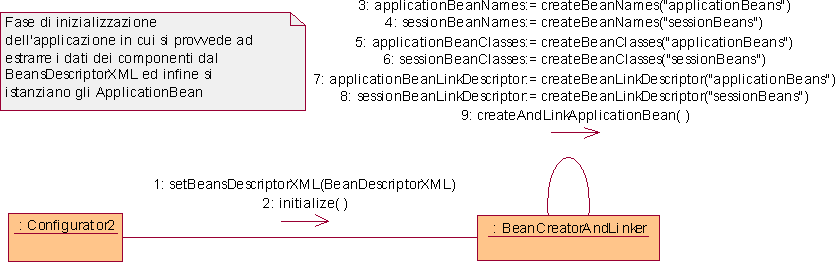
L’inizializzazione dei componenti avviene in due tempi. Per quanto riguarda gli ApplicationBean, essi sono inizializzati all’avvio dell’applicazione, viceversa i SessionBean vengono inizializzati all’atto della creazione di ogni nuova sessione. Al fine di rendere meno onerosa possibile quest’ultima operazione, poiché essa incide sui tempi di attesa dell’utente, risulterà opportuno provvedere in fase di implementazione alla creazione, all’avvio, di una struttura dati ausiliaria (LinkDescriptor) a partire dal BeansDescriptorXML che faciliti le successive inizializzazioni dei SessionBean. Gli ApplicationBean non presentano invece questo problema, inoltre, per quanto discusso in merito ai meccanismi di interazione fra i componenti, non vengono mai modificati dalla costruzione/distruzione di nuovi e vecchi SessionBean.
IL sistema finora sintetizzato supporta bene i requisiti posti in essere al paragrafo 3.1 realizzando quell'infrastruttura come prodotto software a sé stante che era esplicitamente richiesta dal requisito R8. I vincoli in termini di integrazione di componenti qualsiasi non noti a priori, comunicazione fra detti componenti, separazione della logica di controllo da quella di visualizzazione sono stati ampiamente soddisfatti. I casi d'uso previsti per l'infrastruttura possono essere meglio specificati, al termine di questa fase di progetto, nello schema seguente in cui vengono concretizzati i ruoli già delineati nel diagramma di figura 3.4 e vengono chiarite le competenze specifiche richieste a ciascun attore del sistema.
6 - Implementazione
Per lo sviluppo dell’applicazione si decide di adottare, in fase di codifica, la piattaforma Java in virtù delle caratteristiche che la rendono un’ottima scelta per lo sviluppo di applicazioni lato server nel mondo web. Fra queste si ricorda la portabilità su diverse piattaforme hardware/software e la gestione delle richieste a pagine web dinamiche offerta dalle Servlet e dalle pagine JSP. Inoltre il linguaggio Java offre un ottimo supporto alle problematiche specifiche del progetto di questa applicazione, in particolare: la gestione degli eventi, l’utilizzo di oggetti noti soltanto a tempo di esecuzione, la manipolazione di documenti XML. Relativamente ai primi due aspetti citati, la specifica dei JavaBean, comprendente Reflection e gestione delle proprietà dei bean tramite eventi, risulta particolarmente utile per l’implementazione dell’interazione fra infrastruttura e componenti discussa in questo progetto.
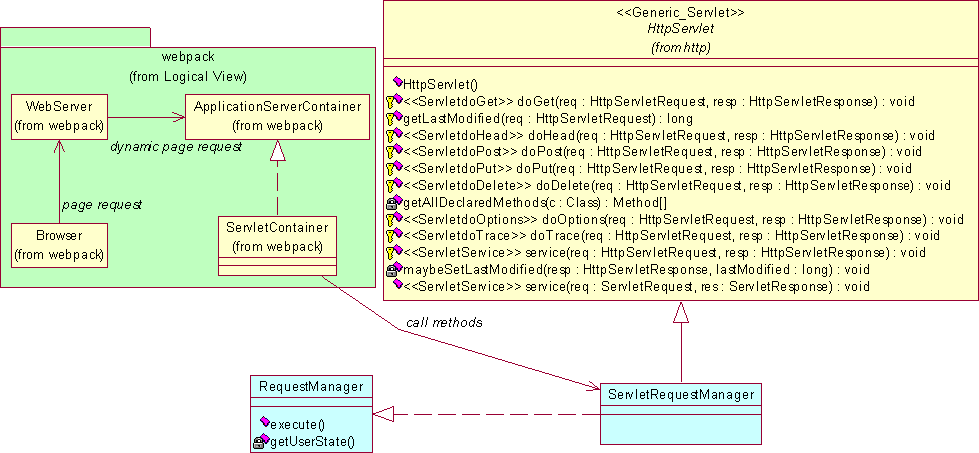
Per realizzare l’interazione fra un client web e un’applicazione lato server, la piattaforma Java 2 Enterprise Edition fornisce come strumento le Servlet. Non ci si addentra nella descrizione della specifica delle servlet in quanto complessa e articolata, ma si illustrano più semplicemente il modello proposto e le caratteristiche interessanti per lo sviluppo di questa infrastruttura. Riprendendo lo schema dell’interazione tramite interfaccia web sviluppato in fase di progetto, e specializzandolo a seguito dell’utilizzo delle servlet, si osserva come, affiancato al WebServer, lavora un ServletContainer a cui vengono demandate le richieste relative a pagine dinamiche, quest’ultimo provvede poi a inoltrare la richiesta Http alla servlet corretta invocandone il metodo opportuno, tipicamente doGet() trattandosi di una richiesta Http di una nuova pagina. Per ciò che concerne la presente applicazione, si illustra nel seguente diagramma la realizzazione implementativa, a seguito dell’adozione delle servlet, dell’interazione fra applicazione e mondo esterno: il RequestManager è realizzato da una classe, il ServletRequestManager, che eredita, in ottemperanza delle specifiche delle servlet, dalla classe javax.servlet.http.HttpServlet; il ServletContainer realizza invece la classe che in fase di progetto era stata indicata come ApplicationServletContainer.
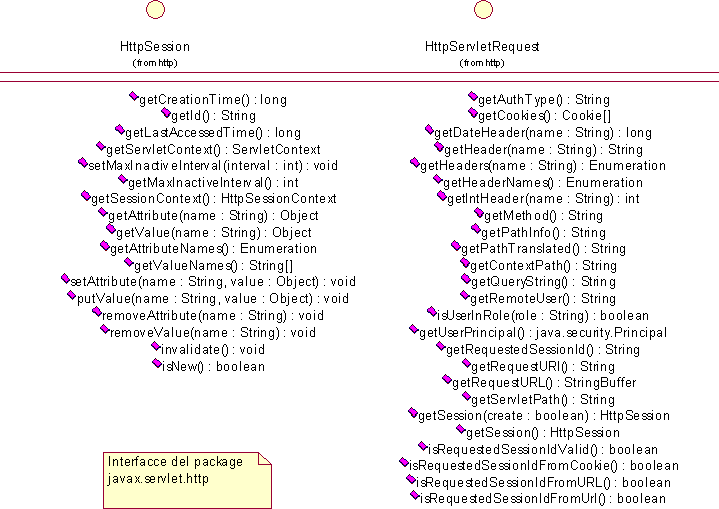
Una servlet gestisce le richieste dei clienti web attraverso l’interfaccia HttpServletRequest. Per quanto riguarda invece la gestione della sessione collegata alla richiesta viene fornita l’interfaccia HttpSession.
Queste interfacce contengono tutte le caratteristiche della richiesta effettuata da un web browser a partire dall’URL che può essere per esempio: http://localhost:8080/WebApplicationIS/progettois?action=azione1&key1=value1&key2=value2 Da questo URL vengono estratte le informazioni principali che andranno a costituire il documento _requestXML, al quale verranno aggiunte altre proprietà della richiesta all’interno del tag <requestProperties> in modo da consentirne la conoscenza ai componenti installati nell’infrastruttura. Relativamente al precedente esempio viene generato il seguente documento _ requestXML: <?xml
version="1.0"
encoding="UTF-8"?>
La piattaforma Java 2 Enterprise Edition offre anche con le pagine JSP un meccanismo assai comodo per la costruzione di pagine dinamiche in risposta alle richieste dei client web. Senza addentrarsi nella descrizione del modello di funzionamento dalle pagine JSP si constata come esse non siano in grado di supportare il modello delineato in fase di analisi e progetto di questa infrastruttura in quanto fondono al loro interno gli aspetti di controllo e visualizzazione.
Integrate all'interno della piattaforma Java 2 Enterprise Edition, e adesso anche la piattaforma Java 2 SDK1.4, sono presenti una serie di interfacce per la creazione, manipolazione e trasformazione di documenti XML. Si tratta unicamente di interfacce alle quali devono essere collegate delle librerie che le implementino. L’utilizzo di Java 2 in versione SDK1.4 fornisce già le librerie Xalan e Xerces per cui tutta la gestione dell’XML all’interno dell’applicazione non richiede la stesura di alcun blocco di codice al di là dell’invocazione dei metodi delle interfacce dei seguenti package:
La specifica delle servlet offre una valida gestione della concorrenza, infatti, ogni volta che un utente richiede una pagina, il ServletContainer si occupa di invocare il metodo opportuno della richiesta http (tipicamente doGet()) effettuando un copia di qualsiasi variabile locale interna al metodo. Ciò fa sì che non vi sia concorrenza nella gestione di diverse richieste contemporanee di più utenti.
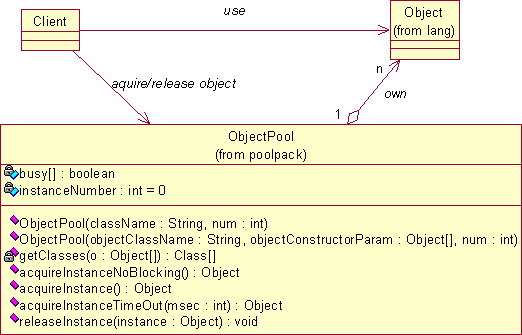
Se la gestione della concorrenza per la classe ServletRequestManager è automaticamente fornita dalla piattaforma Java come discusso precedentemente, per quanto riguarda le altre classi dell’infrastruttura si deve provvedere ad opportuni meccanismi di gestione. Anzitutto è opportuno evidenziare quali sono le classi che rappresentano delle entità univoche all’interno del sistema e quali invece sono collegate e servono una specifica richiesta. Fra le prime si annoverano le classi del configurationpack, ed in particolare il RequestResolverXML e il Configurator; fra le seconde invece rientrano il Controller ed il Viewer. Le classi che rappresentano entità univoche sono realizzati seguendo il pattern Singleton che impedisce l’accesso al costruttore della classe univoca (Singleton) da parte di altre classi che devono invece usare un metodo statico per ottenere un riferimento alla classe Singleton. Per questo tipo di classi la gestione della concorrenza può essere semplicemente ottenuta rendendo synchronized tutti i metodi, sempre che non si tratti di operazioni piuttosto onerose che potrebbero comportare una forte riduzione del parallelismo di esecuzione delle richieste. In ultima analisi va precisato che le interfacce per la gestione dei documenti XML non garantiscono alcuna correttezza di funzionamento in concorrenza, è quindi necessario serializzare le richieste di trasformazione di documenti XML a un trasformatore XSL. La realizzazione del RequestResolverXML come classe Singleton, va quindi in questa direzione. Per quanto riguarda invece le classi Controller e Viewer è opportuno crearne un oggetto per ogni richiesta in modo da risolvere ogni problema di concorrenza e garantire contemporaneamente correttezza e parallelismo. Per eliminare il tempo di creazione di questi oggetti, e per evitare che un notevole numero di richieste comporti la creazione di un eccessivo numero di oggetti, con conseguente elevata occupazione di memoria e degrado delle prestazioni legato al troppo elevato parallelismo, si utilizza il pattern ObjectPool. Questo pattern prevede un gruppo di oggetti uguali gestiti da un manager. Un cliente non può utilizzare direttamente uno di questi oggetti, bensì deve prima richiederne l’acquisizione al manager ed infine, terminato l’uso, rilasciarlo. La realizzazione del manager di oggetti è affidata alla classe ObjectPool che può essere istanziata come pool di oggetti di una particolare classe. Unica condizione sugli oggetti del pool è che siano senza stato, ossia che l’esecuzione dei loro metodi non dipenda dalle precedente esecuzioni, infatti, se così fosse, i cicli di acquisizione e rilascio degli oggetti determinerebbero dei mutamenti indesiderati nella risposta degli oggetti stessi alle richieste del Client.
La gestione della concorrenza a carico dei componenti installati dipende dal tipo di componente. Per i SessionBean non si pone il problema dal momento che essi appartengono ad una specifica sessione di un particolare utente e quindi non vi sarà concorrenza con le richieste di altri utenti che saranno necessariamente inoltrate ai SessionBean delle rispettive sessioni. Per quanto riguarda gli ApplicationBean invece il problema sussiste e sarà compito degli sviluppatori di questi componenti trattarlo opportunamente, eventualmente ricorrendo alla soluzione banale della serializzazione delle richieste. Dove invece è richiesto un certo grado di parallelismo, si pensi per esempio all’ApplicationBean deputato alla memorizzazione permanente dei dati, cui più volte si è fatto riferimento come funzionalità "accessoria" di questa infrastruttura, sarà necessario adottare soluzioni più sofisticate.
Per quanto riguarda la produzione dell’output si effettuano alcune modifiche rispetto a quanto era stato delineato in fase di progetto. Anzitutto si decide di non utilizzare il documento RenderXSL per trasformare una _requestXML ed ottenere un XSLRenderer da utilizzare per il rendering del _beansStateXML. A questo scopo si preferisce inglobare questa logica direttamente nel documento ViewXSL. Inoltre si introduce la possibilità di:
Per quanto riguarda il punto 1) si noti che non si tratta di una richiesta di una pagina statica da parte dell’utente, che sarebbe gestita direttamente dal WebServer, bensì di una richiesta che comporti un’elaborazione lato server la cui risposta è però già precompilata in un file HTML e non generata a partire dal _beansStateXML. In merito alla trasformazione lato server o lato client, va detto che la prima soluzione garantisce maggiore riservatezza poiché non viene restituito all’utente tutto lo stato dei bean, tuttavia la seconda soluzione sgrava dal server un onere computazionale, sempre che il browser del cliente supporti la renderizzazione dello XML. Probabilmente la soluzione migliore prevede entrambe le trasformazioni: sul server si seleziona dal _beansStateXML le sole informazioni da fornire all’utente mentre sul lato client si provvede a formattare opportunamente tali informazioni. Si riporta di seguito la nuova specifica del documento _beansToViewXML. <?xml
version="1.0"
encoding="UTF-8"?>
<?xml
version="1.0"
encoding="UTF-8"?>
Seguendo la specifica delle servlet, il deployment del sistema si basa sulla costituzione di un’unica unità di deployment in un file .WAR, analogo ad un file .JAR ma con una predeterminata struttura di directory, all’interno del quale vengono inserite le classi java ed eventualmente altre risorse come i file XML, XSL e HTML facenti parte dell’applicazione. All’interno del .WAR vi è il file web.xml che dovrà contenere le impostazioni relative alla applicazione web come l’elenco delle servlet (in questo caso una sola), l’URL in corrispondenza dei quali deve essere richiamata ciascuna servlet, i parametri di inizializzazione. Per quanto riguarda questi ultimi essi riguardano:
<?xml
version="1.0"
encoding="UTF-8"?>
7 - Codifica e Testing.
Il codice è stato organizzato seguendo la suddivisione in package e la nomenclatura usate nelle precedenti fasi di analisi e progetto ed è articolato nei file sorgenti che seguono.
Per quanto riguarda la documentazione del codice, essa è stata generata automaticamente a partire dai sorgenti ed è disponibile al link: Documentazione JavaDoc
Per testare l'infrastruttura bisogna anzitutto installare un WebServer e un ApplicationServer con ServletContainer, quindi copiare nell'apposita directory di deployment il file WebApplicationIS.WAR contenente, oltre all'intera infrastruttura, una piccola applicazione di testing che mantiene un contatore globale del numero di visitatori e consente a ciascuno di essi di modificare un proprio contatore privato. Vi è inoltre un bean che interagisce col precedente contatore mediante eventi impedendo che si setti un valore superiore ad una soglia assegnata. I seguenti link puntano ai descrittori e alle risorse di visualizzazione dell'applicazione descritta.
Se sulla macchina locale è stata installata correttamente la precedente unità di deployment, ed è stato correttamente configurato il file web.xml secondo quanto descritto al paragrafo 6.8, l'applicazione di prova sarà accessibile all'URL: http://localhost:8080/WebApplicationIS/progettois
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||