Un interprete Scheme
Autore: Ricciarelli Stefano
Data: 31 Gennaio 2000
Obiettivo
Obiettivo finale è la realizzazione di un sistema software in grado di interpretare le frasi del linguaggio Scheme. Il raggiungimento di tale scopo avverrà attraverso una programmazione incrementale che muova da un semplice interprete di espressioni aritmetiche per giungere, attraverso molteplici estensioni del linguaggio, al raggiungimento dellobiettivo finale, ottenendo così un linguaggio computazionalmente completo. Lestendibilità di tale sistema software si configura come un requisito fondamentale di tutto il progetto diventando parte integrante dellobiettivo. Si intende inoltre sfruttare questo percorso per analizzare e approfondire gli aspetti fondamentali legati a questo linguaggio di programmazione. Si vuole in ultima analisi valutare il ruolo della programmazione ad oggetti nella realizzazione di questo sistema software.
Analisi
Cosè un interprete.
Un interprete di un linguaggio è un automa che riceve in ingresso una frase, stabilisce se tale frase appartiene al linguaggio da interpretare e, in caso affermativo, procede allesecuzione delle operazioni necessarie per valutare tale frase. Da questa definizione si evincono immediatamente alcune problematiche fondamentali da affrontare:
- la definizione rigorosa del linguaggio;
- la determinazione dellappartenenza di una frase al linguaggio;
- la definizione del concetto di valutazione.
Questi sono gli aspetti legati alla costruzione dellinterprete che verranno approfonditi in questa fase di analisi, dei quali si forniscono adesso alcuni aspetti legati alla teoria.
La definizione del linguaggio.
Come fase preliminare, è sicuramente necessario stendere una definizione rigorosa di quelle che sono le frasi ammissibili per questo linguaggio. Si deve cioè caratterizzare in modo non ambiguo la sintassi di Scheme. A tale scopo si utilizzerà un sistema formale denominato grammatica, denotato attraverso la notazione BNF, per descrivere le regole (produzioni) per la costruzione delle frasi del linguaggio.
Il riconoscimento delle frasi.
Definita la grammatica, bisogna risolvere il problema del riconoscimento della appartenenza di una frase al linguaggio. Dalla teoria è noto che la soluzione di tale problema è legata al tipo di grammatica; in particolare vi è la certezza del riconoscimento, assieme ad una buona efficienza, per le grammatiche di tipo 2 (libere da contesto) in quanto riconoscibili da un PDA (Push Down Automata). Sarà quindi opportuno descrivere il linguaggio con una grammatica di questo tipo. Vi è da considerare inoltre che se si giunge alla stesura di una grammatica non deterministica, questa richiederebbe la costruzione di un PDA non deterministico per il suo riconoscimento; problema di sicura non facile realizzazione ed efficienza. In tal caso risulta opportuno cercare di modificare tale grammatica al fine di ottenerne una equivalente (ossia che descriva le stesse frasi) nella quale il non determinismo possa essere risolto osservando il successivo simbolo di ingresso. Si parla in questo caso di grammatiche LL(1). Questa modifica consente di adottare per il problema del riconoscimento la tecnica dellanalisi ricorsiva discendente nella quale si introducono tante procedure quanti sono i non terminali, delegando ad ognuna di esse il riconoscimento del sotto-linguaggio descritto dal non-terminale. Detta tecnica risponde appieno allesigenza di estendibilità del linguaggio posta come obiettivo.
Il linguaggio Scheme.
Le espressioni e il modello valutativo.
Scheme è un dialetto del LISP e come esso è un linguaggio funzionale. Ciò significa che il concetto che sta alla base di tutto il linguaggio è lespressione simbolica, intesa nella sua accezione più generale. Questo quindi è lo spazio concettuale che viene offerto al programmatore LISP o Scheme.
Una espressione può essere atomica (un numero, un simbolo di variabile, un operatore predefinito ) oppure composta, ossia una lista di espressioni racchiuse fra parentesi (esp1, esp2, espn) dove ogni espressione può a sua volta essere atomica o composta dando origine in questo modo ad una struttura ricorsiva dellespressione. Appare immediatamente evidente che sia i dati che le funzioni verranno trattati nel medesimo modo, ossia come espressioni. Ciò è rilevante e costituisce una differenza notevole rispetto ai linguaggi di programmazione tradizionali in stile imperativo, aprendo la strada a nuove soluzioni, quali architetture client/server in cui il client possa richiedere al server non solo la manipolazione di un dato, ma anche il trasferimento di un particolare oggetto computazionale.
La semantica dellespressione composta:
( esp1, esp2, ... espn)
è la seguente:
- esp1 è una espressione che deve denotare un operatore;
- esp2 espn sono espressioni che costituiscono gli operandi del precedente operatore.
Per quanto riguarda la valutazione dellespressione composta, essa può avvenire attraverso una sostituzione testuale delle espressioni operando allinterno dellespressione operatore; si parla in tal caso di modello di valutazione Normal Order o di valutazione by-need in quanto la valutazione degli operandi è rimandata a quando necessaria, eventualmente mai. Alternativamente si può optare per un modello di valutazione applicativo, il quale consta dei seguenti passi:
- valutazione di esp1 (operatore) nellenviroment corrente;
- valutazione di esp2 espn (operandi) nellenviroment corrente;
- applicazione delloperatore agli operandi.
In seguito si chiarirà cosè e che ruolo gioca lenviroment. Qui invece interessa notare subito un aspetto che emerge dal modello applicativo: la valutazione degli operandi non segue un preciso ordine, in sostanza non si stabilisce se verrà valutata prima esp2 o espn. Ciò implica che, affinché sia univocamente determinato il valore della seguente espressione:
( f, (g x), (g y) )
la valutazione di (g x) non deve dipendere dalla valutazione di (g y) e viceversa. Ossia non vi devono essere effetti collaterali nella valutazione di una espressione. Quindi, in altri termini, le funzioni devono garantire trasparenza referenziale, cioè non devono modificare lenviroment condiviso con le altre funzioni.
Per quanto riguarda lespressione operatore, essa può essere un simbolo che identifica una primitiva (cioè una funzione built-in del linguaggio) oppure una funzione definita dellutente. Infatti Scheme, attraverso le espressioni lambda, fornisce quel meccanismo di astrazione che permette di estendere il linguaggio attraverso nuove funzionalità definite dallutente. Una funzione è un oggetto computazionale, che verrà chiamata chiusura lessicale, costituita da:
- una lista di argomenti;
- il corpo della funzione;
- un enviroment.
Si analizza adesso questultima entità.
Lenviroment.
Il linguaggio necessita di una struttura associativa in grado di risolvere la corrispondenza simbolo-valore. In questo modo si consente la denotazione attraverso simboli delle espressioni, siano esse atomiche come i numeri, o composte come le chiusure. Ma questo non basta, è necessario introdurre anche il concetto di scope, ossia di visibilità di tali simboli, in modo da garantire information hiding per le funzioni. Lenviroment costituisce quella struttura che bisogna realizzare per assolvere questo duplice compito. Essa sarà costituita da frames, che realizzano lo scope, ciascuno dei quali conterrà dei bindings, ossia le coppie simbolo-valore valide in quello scope.
Diverse sono le politiche con cui è possibile gestire un enviroment. In particolare, tornando alle chiusure precedentemente analizzate, bisogna stabilire se lenviroment ad esse collegato è quello presente allatto della definizione della funzione (binding lessicale) oppure quello presente allatto dellesecuzione (binding dinamico). Poiché in questultimo caso il risultato della valutazione dipende da quando essa ha luogo, e in generale valutazioni successive possono originare risultati diversi, si preferisce adottare un binding lessicale, garantendo così maggiore chiarezza.
I dati: le liste.
Come precedentemente accennato, i dati sono trattati allo stesso modo delle funzioni, ossia come espressioni. La struttura base fornita dal LISP e da Scheme per i dati sono le liste. Esse sono presentate allutilizzatore del linguaggio come ADT (Abstract Data Type) ossia come dato astratto sul quale operare attraverso le primitive fornite:
sexp cons (sexp, sexp) fornisce unespressione composta contenente le due espressioni passate come parametro; sexp car (sexp) fornisce la prima espressione dellespressione composta passata come parametro; sexp cdr (sexp) fornisce la seconda espressione dellespressione composta passata come parametro; sexp null (sexp) fornisce lespressione True se è vuota la sexp passata come parametro, lespressione Nil altrimenti.
Le forme speciali.
Le forme speciali sono quelle forme che costituiscono uneccezione al modello valutativo precedentemente illustrato. Si può dire che ogni forma speciale costituisce una funzionalità in più del linguaggio; è attraverso laggiunta di queste forme che si giungerà alla realizzazione di un linguaggio di programmazione computazionalmente completo, a partire da un più semplice linguaggio di espressioni aritmetiche e manipolazione di liste. E in particolare su queste forme speciali che si vuole misurare lestendibilità dellinterprete che si è in procinto di realizzare. Quindi sarà compito della fase di progetto prevedere unadeguata strutturazione del sistema software in grado da garantire una facile espandibilità in questa direzione, sia per quanto riguarda il riconoscimento delle nuove forme, sia per la loro valutazione. Di alcune primitive si è già parlato, ecco lelenco di tutte quelle che dovranno essere supportate:
primitive di manipolazione dei numeri reali e interi +, -, *, /, =, <, > primitiva di manipolazione dei numeri interi @ (resto della divisione intera) primitive di manipolazione per le espressioni in generale car, cdr, cons, eq, neq, null costanti nil, true Per quanto riguarda invece le forme speciali, si tratta delle seguenti:
Cond Contiene una lista di coppie di espressioni. La prima espressione di ogni coppia viene interpretata come una espressione booleana, vera se uguale a true, falsa altrimenti. A seguito della verità della prima espressione della coppia, la Cond restituisce la seconda; altrimenti procede alla valutazione della coppia successive e in assenza di una espressione vera restituisce la costante nil. Si noti come questa forma sia sostanzialmente diversa dallanaloga forma if-then-else dei linguaggio imperativi, infatti la Cond non esegue nessuna azione, semplicemente si limita a restituire una espressione in relazione alla verità o meno di unaltra. Lambda Si tratta di una forma essenziale, essa costituisce il meccanismo di astrazione del linguaggio e permette di definire nuove funzioni a partire da quelle di base realizzando le chiusure lessicali di cui si è precedentemente parlato. Per chiarire limportanza di questa forma, basti considerare che insieme alla precedente e sufficiente a creare un linguaggio computazionalmente completo. Tutto questo è possibile grazie alla ricorsione, ossia alla possibilità di una funzione di richiamare sé stessa. Quote Consente di bypassare la valutazione di un' espressione. La valutazione di (quote sexp) restituisce infatti la sexp stessa. Define Si tratta di una forma speciale particolare. Essa infatti non costituisce una espressione da potere essere usata in ogni contesto come le precedenti forme speciali, le quali risultano essere espressioni simboliche alla stregua di unespressione aritmetica. Infatti la define consente di modificare lenviroment globale aggiungendovi un nuovo binding ed estendendo così le funzionalità del linguaggio di base. Per questo motivo, generando degli effetti collaterali, essa può essere scritta solo al primo livello, ossia non può comparire come argomento di nessunaltra espressione altrimenti si perde la trasparenza referenziale. Per convincersi delle problematiche enunciate per la define, basta osservare cosa succederebbe nel seguente esempio:
(+ (define x 2) (+ x 5) )
E opportuno notare che la define non aggiunge niente in termini di classi di funzioni computabili - il linguaggio è già computazionalmente completo - tuttavia risulta essere notevolmente comoda. E importante osservare come essa non sia unistruzione di assegnamento, bensì fornisce unicamente la possibilità di unestensione monotona dellenviroment globale e quindi del linguaggio.
La modifica dellenviroment globale inficia la realizzazione di un binding lessicale?
Con la define si introduce quindi il concetto di enviroment globale sul quale è conveniente fare alcune riflessioni. Esso è detto globale proprio perché viene visto da tutte le funzioni, ed ogni sua estensione è retroattiva; ciò significa che chiusure definite in precedenza in cui era presente un determinato lenviroment globale, vedono anche le funzioni che sono state definite dopo. Questa può sembrare uneccezione al binding lessicale, in realtà, dal momento che ogni esecuzione si esaurisce completamente in un solo enviroment globale, questo non mina il concetto di binding lessicale, semplicemente costituisce una comoda opportunità per caricare nellambiente globale funzioni precedentemente definite che possano fra loro richiamarsi come segue:
(define funz1 (lambda (x) (g (funz2 x) ) )
(define funz2 (lambda (x) (h (funz1 x) ) )
Appare evidente come in uno schema di questo tipo la modifica retroattiva dellenviroment globale sia necessaria; viceversa sarebbe infatti impossibile per la chiusura funz1 risolvere il simbolo funz2 nellenviroment presente al momento della definizione, inoltre lo scambio dellordine di esecuzione delle espressioni provocherebbe il caso duale.
Introdurre lassegnamento?
Visto e considerato quanto esposto nel precedente paragrafo è lecito chiedersi se sia opportuno introdurre unistruzione di assegnamento, dal momento che è stato chiarito essere non necessario. Un motivo che potrebbe portare allintroduzione di questa funzionalità è la volontà di creare oggetti con stato. Di seguito si realizza come esempio un piccolo programma Scheme che permette di costruire, attraverso le chiusure lessicali e lassegnamento, un oggetto contatore inizializzabile ad un certo valore e che risponde ai metodi + e = coi quali può essere incrementato o visualizzato.
(define CreaCont (lambda (s ) (lambda (msg ) (cond ((eq msg (quote +)) (setq s (+ s 1 ))) ((quote =) s ) ) ) ) );
(define contatore (CreaCont 0));
Comandi (in sequenza) (contatore =) (contatore +) (contatore =) Il seguente grafico illustra il meccanismo con cui tutto questo viene realizzato, in particolare evidenzia il ruolo della chiusura (cerchio giallo) nella memorizzazione dello stato.
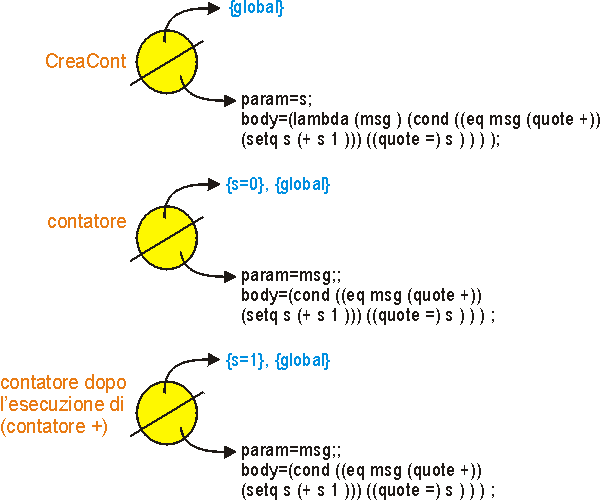
Leventuale introduzione dellassegnamento è da considerare attentamente poiché ha importanti risvolti sul progetto e sullimplementazione dellenviroment. Infatti la modifica del valore di un simbolo dellenviroment di una funzione non deve ripercuotersi né sullenviroment globale, né su tutti gli altri frame che non siano quello locale della funzione. Quindi, in fase di implementazione, bisognerà valutare attentamente le tecniche di gestione della memoria facendo particolare attenzione qualora si decida di utilizzare tecniche di structure sharing.
Una grammatica per Scheme.
Terminata la precedente analisi e stabilite quali sono le funzionalità che il linguaggio deve supportare si passa alla stesura della sintassi.
SEXP2::= ATOMICA | COMPLESSA2 COMPLESSA2::= ( define DEFINEARG ) | COMPLESSA DEFINEARG::= IDENT SEXP SEXP::= ATOMICA | COMPLESSA ATOMICA::= IDENT | NUMERO | PRIMITIVE | COSTANTE COMPLESSA::= ( lambda LAMBDAARG ) | ( cond CONDARG ) | ( setq SETQARG ) | ( quote SEXP ) | ( LISTASEXP ) LAMBDAARG::= ( LISTAIDENT ) SEXP LISTAIDENT::= IDENT | LISTA IDENT CONDARG::= ( SEXP SEXP ) | ( SEXP SEXP ) CONDARG SETQARG::= IDENT SEXP LISTASEXP::= SEXP | SEXP LISTASEXP
Le categorie lessicali di questa grammatica, ossia le entità elementari che si considerano facenti parti dellalfabeto (token), sono le seguenti:
PRIMITIVE::= car | cdr | null | cons | eq | neq | = | < | > | + | - | * | / | @ KEYWORD::= define | cond | setq | lambda | quote CONSTANTE::= nil | true | t LPAR::= ( RPAR::= ) NUMERO::= i numeri interi o reali secondo la consueta rappresentazione EOF::= fine caratteri di ingresso IDENT::= sequenze di caratteri alfabetici diverse dalle precedenti Anzitutto una riflessione: la correttezza di una frase è legata sia ad aspetti sintattici (descritti appunto dalla grammatica) sia ad aspetti semantici. La separazione fra questi due aspetti non è ben delineata, infatti la grammatica precedentemente mostrata riconosce come valide frasi del tipo:
(/ 2 3 4)
nonostante loperatore / sia un operatore binario; quindi il controllo degli argomenti è lasciato sul piano semantico. Viceversa si sarebbe potuto portarle sul piano sintattico modificando/aggiungendo le seguenti produzioni
SEXP::= ATOMICA | ( COMPLESSA ) | ( PRIM1 SEXP ) | ( PRIM2 SEXP SEXP ) ATOMICA::= IDENT | NUMERO | COSTANTE PRIM1::= car | cdr | null PRIM2::= cons | eq | neq | = | < | > | + | - | * | / | @ Naturalmente questo è solo un esempio, quindi si capisce come la stesura della grammatica del linguaggio goda di un notevole grado di libertà. In merito a questo progetto, si è preferito non appesantire troppo la grammatica lasciando al valutatore il compito di generare degli errori qualora le frasi in ingresso non rispettino la corretta semantica. Si riprende quindi in analisi la grammatica inizialmente scritta. Come chiarito in precedenza, questa grammatica deve essere modificata dal momento che risulta non deterministica; infatti per alcuni non terminali non è possibile determinare a priori quale produzione applicare per la loro riscrittura. Per superare questo indeterminismo, si modifica la grammatica ottonendone una equivalente LL(1), ossia per la quale si può stabilire la produzione da dovere applicare osservando un solo token.
SEXP2::= ATOMICA | ( COMPLESSA2 COMPLESSA2::= define DEFINEARG ) | COMPLESSA DEFINEARG::= IDENT SEXP SEXP::= ATOMICA | ( COMPLESSA ATOMICA::= IDENT | NUMERO | PRIMITIVE | COSTANTE COMPLESSA::= lambda LAMBDAARG ) | cond CONDARG | setq SETQARG ) | quote SEXP ) | SEXP LISTASEXP LAMBDAARG::= ( LISTAIDENT SEXP LISTAIDENT::= ) | IDENT RESTOIDENT RESTOIDENT::= ) | IDENT RESTOIDENT CONDARG::= ( SEXP SEXP ) RESTOCOND RESTOCOND::= ) | CONDARG SETQARG::= IDENT SEXP LISTASEXP::= ) | SEXP LISTASEXP
Architettura logica del sistema.
Finita lanalisi dello spazio concettuale del problema, inizia a delinearsi una precisa architettura logica del sistema software da realizzare. In particolare, si dovranno preventivamente riconoscere i simboli chiave del linguaggio (token), quindi bisognerà processarlie esaminando la correttezza della frase, infine passare alla valutazione. Queste tre azioni vengono rispettivamente portate a termine da tre componenti software: il lexer, il parser, il valutatore. Tali componenti operano in cascata secondo un modello client/server, dove il valutatore chiede la frase al parser, il quale richiede i token al lexer.

Nella precedente figura si noti che in uscita al parser vi è una rappresentazione interna della frase. Infatti il parser, oltre a dovere controllare la correttezza sintattica della frase, provvede a generare un'opportuna rappresentazione strutturata della frase in ingresso sulla quale poi il valutatore andrà ad operare. Questa struttura costituisce un primo passo per rispondere agli obiettivi enunciati, favorendo la modularità del sistema. Infatti si procede per livelli di astrazione successivi, a partire dai singoli caratteri, generando i token, e costruendo infine una rappresentazione interna astratta della frase di ingresso.
Il lexer.
Questo componente provvede a raggruppare i singoli caratteri presenti sul dispositivo di ingresso in token. Ogni token rappresenta una categoria lessicale del linguaggio, alcuni esempi:
)
rparToken
pippo
identToken
23
intToken
Il lessico di un linguaggio è generalmente molto semplice e quindi esprimibile con grammatiche regolari (tipo 3). Questo consente, in accordo con la teoria delle grammatiche, di realizzare questo componente attraverso un automa a stati finiti garantendo in questo modo prestazioni elevate.
Il parser.
Differentemente dal lexer, il parser deve riconoscere frasi generate da una grammatica di tipo 2. Tale problema e risolvibile dalla classe di macchine PDA, ossia da un automa a stati finiti dotato di una memoria a stack. Come precedentemente evidenziato, in uscita vi è la rappresentazione interna della frase. Detta rappresentazione deve riflettere la struttura profonda della frase di ingresso. Si tratta di un punto critico nel progetto dell'interprete. Infatti a seconda della struttura scelta diverse saranno le prestazioni complessive del sistema e la stesura del codice del valutatore. Modifiche importanti a questa rappresentazione comporterebbero la necessità di apportare cambiamenti anche radicali nel valutatore minando così l'estendibilità del sistema. Una struttura ad albero, che rispecchi la sintassi espressa dalla grammatica del linguaggio, risulta essere un'ottima scelta in quanto consente di esprimere la struttura intima della frase. Si evita una rappresentazione come albero di derivazione della frase, in quanto risulta ridondante, e si omettono i simboli non terminali. In questo modo si ottiene quello che viene chiamato abstract parse tree (APT).
Il valutatore.
Da quanto analizzato precedentemente, risulta chiaro che linterprete per valutare le frasi (espressioni) di ingresso deve realizzare due funzionalità fondamentali:
- la valutazione;
- lapplicazione.
Tali funzionalità devono potere operare su tutti i tipi di espressioni che si andranno via via implementando (chiaramente lapplicazione riguarda unicamente le espressioni composte). Queste due operazioni devono necessariamente essere ricorsive, in quanto la valutazione di unespressione composta richiede precedentemente la valutazione delle sue componenti, le quali al loro volta possono essere composte ecc
Progetto
Modellazione del dominio del problema.
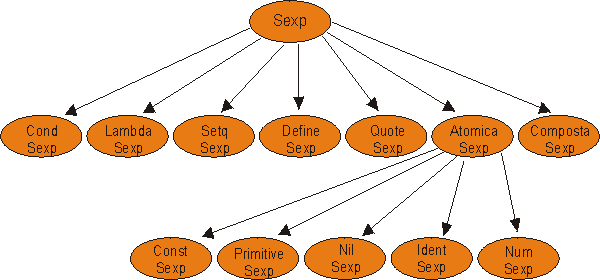
Dalla precedente analisi, si è in grado di individuare una precisa struttura delle espressioni che viene riflessa, in questa fase di progetto, in una tassonomia di classi. La possibilità, quanto meno di pensare, in uno spazio concettuale ad oggetti favorisce notevolmente lapproccio al problema e quindi la sua soluzione. Infatti i concetti propri della OOP, ossia ereditarietà e polimorfismo, consentono di catturare in modo veramente efficace lessenza del dominio cui ci si trova di fronte. Poiché tutto è espressione, viene naturale realizzare tanti tipi di espressione quanti sono quelli analizzati in precedenza, legandoli fra loro attraverso la relazione di sotto-tipo rispetto allespressione generica. E evidente che questa modellazione delle entità del problema conduce alla realizzazione di un sistema aperto, facilmente estendibile: dovendo introdurre un nuovo tipo di espressione, non bisogna fare altro che aggiungere una classe alla tassonomia.
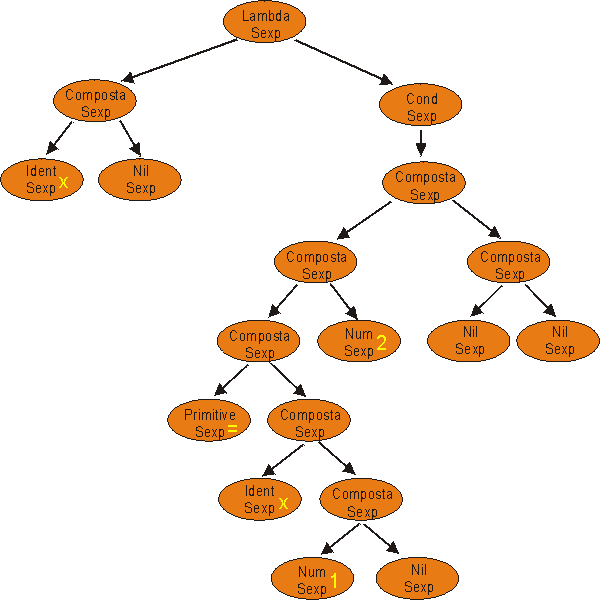
Poiché tale tassonomia rappresenta lintero dominio delle espressioni in ingresso al sistema, è logico devolvere al parser che riconosce le frasi, il compito di fornire la rappresentazione della frase di ingresso (espressione) sotto forma di una classe di questa tassonomia. La struttura sarà chiaramente ricorsiva poiché espressioni composte contengono al loro interno altre espressioni, quindi ciò che giungerà in ingresso al valutatore sarà un albero (la cui precisa struttura dipende ovviamente da come verranno memorizzate le espressioni allinterno delle classi). Si riporta un esempio di rappresentazione interna.
Frase di ingresso
( lambda (x) (cond (= x 1) 2 ) )
Rappresentazione interna della frase fornita del parser
La valutazione: architettura dellinterprete.
Per quanto riguarda la valutazione delle espressioni si aprono due alternative: o si procede alla realizzazione di una funzione di valutazione a sé stante che provvede a tale scopo, oppure si realizza per ogni classe un metodo valutatore. La prima alternativa consente unestendibilità rivolta allintroduzione di nuove forme di valutazione; viceversa, la seconda opzione mira a garantire una facile aggiunta di nuove funzionalità del linguaggio. Visto e considerato il percorso evolutivo che segue questo progetto - si vuole costruire per gradi linterprete - lultima alternativa risulta sicuramente più opportuna e atta a soddisfare le esigenze di crescita verso questa direzione, coerentemente con lobiettivo prefissato. Quindi si introduce un metodo eval per ogni classe; esso riceverà in ingresso lenviroment nel quale la valutazione dovrà avere luogo. Si noti il ruolo fondamentale che gioca il polimorfismo in questo scenario: è grazie alla possibilità di una variabile di denotare istanze di più tipi diversi, legati da relazioni di ereditarietà, che è possibile valutare correttamente una sexp, di qualunque tipo essa sia, semplicemente invocandone il metodo eval.
Lenviroment come componente software.
La fase di analisi ha visto unampia discussione sul ruolo dellenviroment nella valutazione delle espressioni; in quella sede si è inoltre delineata una struttura di base costituita da frames e bindings. Inoltre - questo probabilmente è laspetto più importane - si è visto come lintroduzione di alcune forme speciali richieda nuove funzionalità da parte dellenviroment. In particolare tanto la define, quanto la setq devono produrre modifiche permanenti su di esso. Appare evidente che permettendo alle varie classi di manipolare direttamente la struttura dellenviroment, si incorre in gravi problemi proprio nel momento in cui si richiederà lintroduzione della define e della setq. Con queste istruzioni infatti viene meno la trasparenza referenziale, e lintroduzione di effetti collaterali può provocare la perdita del binding lessicale dal momento che, in caso di structure sharing, le modifiche di un enviroment locale possono ripercuotersi sugli altri enviroment locali memorizzati allinterno delle chiusure. Ecco quindi che lestendibilità del sistema risulta limitata e comunque soggetta a sforzi notevoli. Si pensi poi allintroduzione futura di specifiche di particolare efficienza dellenviroment che comportino la riprogettazione della sua struttura interna: bisogna modificare tutte le classi delle espressioni! Per questi motivi si opta per la realizzazione dellenviroment come un componente software, al cui interno potranno essere memorizzate non solo espressioni ma oggetti in generale, aprendo in questo modo la strada della riutilizzabilità di tale componente software anche in altri ambiti. Lenviroment che ci si propone di realizzare sarà quindi un ADT al quale si potrà accedere attraverso funzionalità di base. Segue lelenco delle primitive:
boolean addBindingInCurrentFrame (Object var, Object val) Aggiunge un nuovo binding al frame corrente dellenviroment restituendo true; restituisce false in caso il binding sia già presente e non effettua alcuna modifica. void addFrameS (Enviroment oldEnv) Aggiunge in coda allenviroment attuale i frame di un altro enviroment, passato come parametro. Object find (Object id) Restituisce loggetto corrispondente alloggetto identificatore passato come parametro; se non presente nellenviroment restituisce loggetto Nil. A queste primitive, con le quali si riesce ad implementare tutte le funzionalità di Scheme illustrate, si aggiunge in seguito unaltra primitiva che consenta di implementare listruzione setq
boolean replaceInEnvWithSideEffect ( Object id, Object newVal ) Ricerca, a partire dal frame corrente, lidentificatore id nellenviroment e, qualora lo trovi, ne sostituisce il valore con newVal e restituisce true; se non trovato lo si aggiunge nel frame corrente restituendo sempre true. Se si tenta di applicare questa primitiva ad un enviroment globale, ossia se è presente un unico frame, non si effettua alcuna modifica e si restituisce false.
Implementazione
Limplementazione muove le mosse dalla consapevolezza di avere a disposizione una piattaforma di sviluppo software evoluta, in grado di fornire tanto i meccanismi di base della computazione - quali le funzioni e la ricorsione - quanto quelle funzionalità di ulteriore astrazione legate a tutto quellinformation space relativo agli oggetti, allereditarietà e al polimorfismo. In particolare si intende utilizzare in fase di codifica la piattaforma Java dal momento che essa mette a disposizione tutte queste funzionalità unite ad una semplice gestione della memoria dinamica e, non per ultimo, fornisce un ampio supporto per la veloce realizzazione di interfacce grafiche e la immediata predisposizione allambiente di rete attraverso la creazione di Applet direttamente fruibili sul Web mediante pagine HTML. Le scelte implementative durante la stesura del progetto sono state innumerevoli; in questa sede non si intende fornirne un elenco dettagliato, bensì mostrare un esempio di tali scelte. A questo proposito si illustra limplementazione dellenviroment e la gestione degli errori.
Implementazione dellenviroment.
Stabilite in fase di progetto le primitive, sospendendo per il momento il discorso relativo allassegnamento, si decide di realizzare lenviroment con tecniche di structure sharing dal momento che esse garantiscono unottima efficienza in termini di memoria. Rimandando ad eventuali future specifiche lottimizzazione in ricerca dei bindings, si preferisce in questa sede optare per una più rapida implementazione a lista di cui si fornisce una rappresentazione grafica:
ENV rappresenta l'enviroment iniziale sul quale si opera poi con le primitive fornite per l'estensione dell'enviroment. In particolare:
- col colore verde si evidenziano i cambiamenti a seguito dell'esecuzione della primitiva ENV.addBindingInCurrentFrame;
- col colore rosso si mostramo i cambiamenti dovuti all'esecuzione della primitiva ENV2.addFrameS(ENV1).
Per quanto riguarda l'implementazione dell'assegnamento, che richiede l'aggiunta del metodo:
boolean replaceInEnvWithSideEffect ( Object id, Object newVal )
descritto in fase di progetto, bisogna tenere presente che, qualora si trovi il binding da modificare in un frame precedente, bisogna provvedere ad una copia della struttura fin qui percorsa. Non si è voluto addentrarsi nello specifico di questa implementazione, limitandosi ad effettuare le modifiche dei binding senza copia, pur con la consapevolezza di cosa questo comporta. Da qui la scelta del nome di questa primitiva.
In fase di verifica della correttezza del programma si cercherà di evidenziare questo aspetto.
La gestione degli errori.
Un altro aspetto implementativo interessante che si vuole mettere in luce è la gestione degli errori. Come evidenziato in fase di analisi, il fatto che una frase sia sintatticamente corretta non garantisce che lo sia anche sul piano semantico, ragione per la quale bisogna prevedere lopportunità di generare e gestire gli errori, possibilmente informando lutente su dove e cosa li ha causati. La piattaforma Java fornisce un valido strumento per il trattamento degli errori attraverso le parole chiave try-catch; tuttavia si è deciso di non avvalersi di questi strumenti in questo caso poiché avrebbero portato alla stesura di un codice troppo pesante dal momento che ogni invocazione di valutazione di una espressione sarebbe dovuta essere racchiusa da dette parole chiave. Si è invece preferito realizzare una classe ErroreSexp, da restituire in caso di errore, contenente una stringa che ne fornisce la descrizione. Tale classe, ereditando da Sexp, risulta essere sempre gestibile come una qualunque espressione. A questo punto, dopo ogni invocazione di valutazione, basta effettuare un controllo sulla Sexp di ritorno e in caso di errore ritornarla direttamente al chiamante, in modo da propagare allindietro tale errore. Il risultato finale della valutazione sarà quindi un errore contente la descrizione di dove e quando esso si è verificato.

Codifica
Il codice, scritto in Java per i motivi illustrati nella sezione precedente, si articola nei seguenti file sorgente:
Testing
L'applet finale è la seguente. Si tenga presente che l'applet non può accedere ai file locali; per fare ciò è necessario scaricare il codice dell'applicazione e eseguirlo sulla macchina locale richiamando la classe MainGraph.
Nella sotto-directory \test sono presenti alcuni file con i quali si è testato l'interprete. I più interessanti sono i seguenti:
Stream.txt Contiene le primitive per la realizzazione dell'astrazione stream e un piccolo esempio di uno stream che genera numeri interi. E' utile per verificare la correttezza del meccanismo delle chiusure. Counter.txt Contiene il codice del contatore visto nella sezione di analisi. Serve come verifica del funzionamento della Setq. SideEffect.txt Mette in evidenza, come già chiarito nella fase di implementazione, i problemi legati agli effetti collaterali della Setq se l'enviroment è implementato con tecniche di strucure sharing. Di quest'ultimo test si riporta il risultato:
- Input Exp > (define creacont1 (lambda (s) (lambda (b) (lambda (msg) (cond ((eq msg (quote +)) (setq s (+ s 1 ))) (true s ) ) ) )))
- Output Exp > creacont1 aggiunto nell'enviroment.
- Input Exp > (define creacont2 (creacont1 7) )
- Output Exp > creacont2 aggiunto nell'enviroment.
- Input Exp > (define cont (creacont2 5) ) Output Exp > cont aggiunto nell'enviroment.
- Input Exp > creacont2
- Output Exp > (Closure: [b ] ; (lambda [msg ] (cond [ [eq msg (quote + ) ] (setq s [+ s 1 ] ) ] [ true s ] [] )) ; (Env: { [ s 7 ] } {global} .) .)
- Input Exp > cont
- Output Exp > (Closure: [msg ] ; (cond [ [eq msg (quote + ) ] (setq s [+ s 1 ] ) ] [ true s ] [] ); (Env: { [ b 5 ] } { [ s 7 ] } {global} .) .)
- Input Exp > (cont (quote +))
- Output Exp > s
- Input Exp > cont
- Output Exp > (Closure: [msg ] ; (cond [ [eq msg (quote + ) ] (setq s [+ s 1 ] ) ] [ true s ] [] ); (Env: { [ b 5 ] } { [ s 8 ] } {global} .) .)
- Input Exp > creacont2
- Output Exp > (Closure: [b ] ; (lambda [msg ] (cond [ [eq msg (quote + ) ] (setq s [+ s 1 ] ) ] [ true s ] [] )) ; (Env: { [ s 8 ] } {global} .) .)