
Luca Veraldi
veraldi@cli.di.unipi.it
luca.veraldi@katamail.com
Campobasso, 7 Settembre 2003
|
I Moderni Sistemi Operativi offrono allo sviluppatore software
una vasta gamma di meccanismi per il supporto
alle comunicazioni tra processi.
Nella prima parte del presente lavoro, metteremo sotto esame le primitive di comunicazione piů comuni, o piů largamente utilizzate, sui sistemi operativi cosiddetti Linux-like, cercando di approfondirne il funzionamento ed evidenziando, di conseguenza, i problemi di efficienza che esse comportano. Nella seconda parte, affronteremo il processo di ingegnerizzazione di un nuovo e piů efficiente set di primitive per l'IPC. |
|
|
Lo sviluppo di applicazioni parallele, ovvero di applicazioni costituite
da piů processi cooperanti, č un paradigma diffuso da tempo
nei piů diversi settori dell'informatica.
E' il solito vecchio trucco di dividere un problema in sottoproblemi
piů semplici da affrontare e da risolvere (top-down),
per poi comporre le soluzioni in qualche modo ed ottenere
la soluzione del problema originario (bottom-up).
Una applicazione costituita da piů processi fa esattamente questo:
ora, "comporre le soluzioni" significa far interagire i processi,
tipicamente, permettendo loro di scambiarsi messaggi.
Anche se non ci facciamo magari piů caso (o lo ignoriamo completamente, grazie ad un modello di programmazione ad alto livello), le nostre applicazioni, anche se non parallele, interagiscono comunque con una gran quantitŕ di altre entitŕ e processi, magari componenti del livello del Sistema Operativo. Il parallelismo č dunque la cosa piů naturale ed innata, nello sviluppo di software... solo i nuclei dei Moderni Sistemi Operativi continuano ad essere sviluppati seguendo lo schema monolitico... Di conseguenza, č importante per qualunque progettista software, alle prese con una applicazione di questo tipo, scegliere di volta in volta i meccanismi di comunicazione tra processi piů opportuni e piů efficienti per il progetto in esame. Ed č compito del Sistema Operativo implementare le politiche per il supporto a tali meccanismi. Nel loro insieme, le primitive di comunicazione tra processi messe a disposizione da un Sistema Operativo prendono il nome di meccanismi di Inter Process Communication (o IPC). In questa prima parte del lavoro, ci soffermeremo sui meccanismi di IPC disponibili su Linux e su alcuni Sistemi Operativi della stessa famiglia (o Linux-like). Analizzeremo in dettaglio le primitive ad alto livello che lo sviluppatore puň utilizzare ed il modello di programmazione indotto dall'uso di tali primitive. A questo punto, dalla struttura del supporto e dai test sperimentali effettuati, appariranno evidenti i problemi di efficienza attualmente esistenti nelle comunicazioni inter-process.
Alcuni dettagli sulla Macchina Target dei nostri esperimenti...
Prenderemo in considerazione il seguente scenario (alto livello): abbiamo 2 processi cooperanti che vogliono scambiarsi messaggi su un canale di comunicazione simmetrico (un sender, un receiver) asincrono (il canale č una coda di messaggi di lunghezza maggiore strettamente di 1).
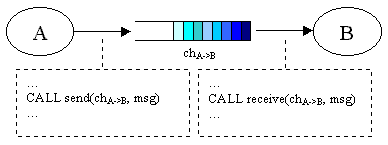
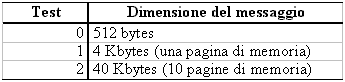
Ma le stesse considerazioni si applicano anche a canali asincroni asimmetrici in ingresso (piů processi sender) o in uscita (piů processi receiver). Le prove consisteranno in send e receive tra i due processi sul canale di comunicazione e con le primitive scelte di volta in volta. I messaggi spediti saranno porzioni dello spazio di indirizzamento logico di A. Effettueremo 3 prove per ogni set di IPC:
|
|
|
I meccanismi di IPC di gran lunga piů diffusi su Linux e tutti i suoi
cloni, varianti, imitazioni ecc. sono le pipe e le cosiddette primitive SYS V
per le code di messaggi ed i segmenti di memoria condivisi.
Una pipe č una canale di comunicazione a grado di asincronia fisso (!!!). Il suo strepitoso successo tra le comunitŕ di linuxiani sta nel fatto che per inizializzare, chiudere, spedire o ricevere dati in presenza di una pipe si utilizzano esattamente le stesse primitivi necessarie per aprire, chiudere, scrivere e leggere dati da un file su disco. Il fatto che tutto il mondo si riduca ad un file (i file sono file, le pipe sono file, i socket sono file, le periferiche sono file ecc.) č una delle caratteristiche carine di Linux. E in effetti, spedire un messaggio da A a B su una pipe equivale ad una scrittura del messaggio sul file (fase di send) e ad una successiva lettura del messaggio dal file (fase di receive). Piů qualche altro accorgimento per la sincronizzazione tra A e B, che si riduce a semplici sleep e wake up (condizioni di canale pieno/vuoto). L'essenza della comunicazione su pipe č catturata dal seguente schema:
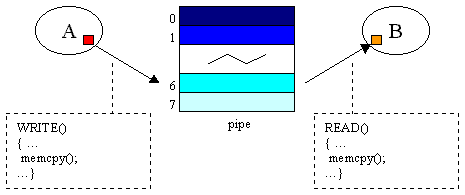
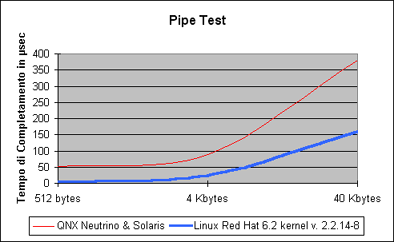
Il fulcro di tutto sono le memcpy(). Trasferire 4096 bytes da A a B implica la copia fisica del doppio dell'informazione... non č esattamente quello che si dice comunicazione zero-copy... I risultati sperimentali sulla macchina di riferimento sono riportati nelle seguenti tabelle:
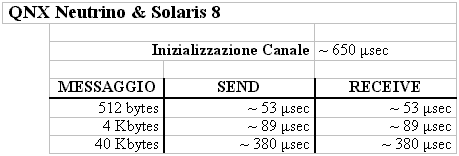
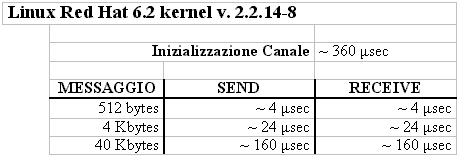
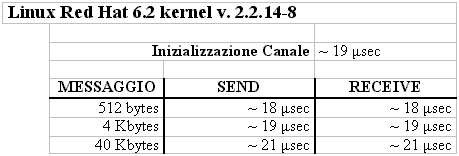
I valori indicati sono valori medi riportati con la chiamata gettimeofday() della libreria sys/time.h. Non hanno influito i ritardi indotti dalle sincronizzazioni (sleep e wake up), che aggiungono con frequenza 1/8 altri 40-60 µsec ai tempi indicati (cioč, nel caso di Linux, un ritardo dello stesso ordine di grandezza della copia fisica del messaggio, per messaggi di una pagina di memoria; un ritardo trascurabile, per messaggi di dimensione maggiore). A giustificazione del fatto che non si č tenuto conto degli overhead di sincronizzazione, c'č da dire che il nostro interesse č focalizzato su come ottimizzare la spedizione e la ricezione di messaggi: qualunque protocollo di comunicazione implica overhead per sincronizzazione su canali pieni/vuoti. Inoltre, lo sviluppatore puň (eheh... sempre ammesso che il modello di programmazione glielo permetta... :-)) fissare il grado di asincronia del canale in modo da rendere trascurabili le sleep e le wake up. Alcune considerazioni. Innanzitutto, appare evidente che QNX Neutrino e Solaris non reggono il confronto con Linux. C'č quasi un ordine di grandezza di differenza nei tempi di completamento delle primitive. In secondo luogo, in entrambi i casi, č chiara la dipendenza lineare tra la dimensione in byte del messaggio e i tempi necessari per completare send e receive.
Le SYS V IPC per la gestione delle code di messaggi sono un modo piů complicato, confuso ed inefficiente per fare la stessa cosa delle pipe. Si tratta sempre di copia fisica in spedizione e copia fisica in ricezione, ma espresso, in termini di codice C, attraverso un formalismo che č la vergogna della programmazione. Comunque, bando ai giudizi personali, ecco i numeri (numeri, numeri... altro che parole):
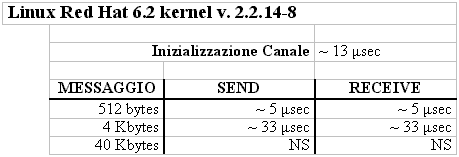
Allora, l'idea č di avere un canale con grado di asincronia fisso (maledetto Linus Torvalds) con 32 posizioni. L'NS riportato in corrispondenza di messaggi di 40 Kbytes č dovuto al fatto che, con le meravigliose primitive SYS V, potete spedire messaggi fino a 4056 bytes (ohohhhh!!!). Meraviglia :-O! In questo caso, l'esecuzione di primitive di sleep e wake up porta via un tempo secolare (eheh... aspetta quello che arriva dopo...): circa 200 µsec. Il guadagno rispetto alle pipe č solo per l'instanziazione della comunicazione. Tutto il resto ha performance scadenti. Complimenti agli ingegneri dei messaggi SYS V.
Vediamo se riusciamo a beccarne una che funzioni a dovere... (eheh... no che non ci riesci...) I segmenti condivisi servono per implementare comunicazioni tra processi, che novitŕ, questa volta perň a partire da un punto di vista sul problema totalmente differente. Anzicchč copiare il messaggio dallo spazio di A a quello di B, permettiamo a B di accedere direttamente alle locazioni dello spazio di A che corrispondo al messaggio da inviare. Per ulteriori dettagli su questa cosa, che si chiama passaggio dinamico di capability, vedi [VAN1] e [VAN2]. Il disegnuccio esplicativo:
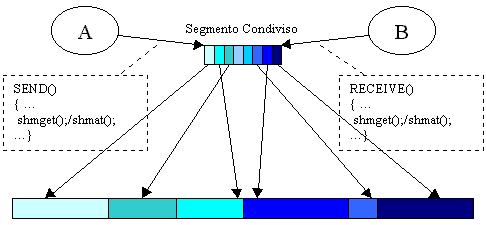
Cerchiamo di capire di che si tratta. Se A vuole spedire un messaggio a B, richiede innanzitutto al Sistema Operativo un nuovo segmento condiviso, con la chiamata shmget(). A questo punto, tipicamente, A vorrŕ scrivere le informazioni da spedire a B nel segmento. Per farlo, lo acquisisce nello spazio di indirizzamento logico, con la chiamata shmat(). shmat restituisce un indirizzo logico, analogamente alla malloc(). A puň modificare il segmento a proprio piacimento. Quando č completa la formattazione del messaggio, B acquisisce lo stesso segmento con la shmget() e lo attacca al proprio spazio di indirizzamento logico con la shmat(). A questo punto, puň leggere le informazioni che A gli ha spedito. Chiaramente, come per tutte le situazioni di comunicazione a memoria condivisa, ci vogliono semafori di sincronizzazione. Quando B sa che A ha terminato di scrivere nel segmento condiviso? Basta che B faccia una down su un semaforo e che A, al momento opportuno, lo sblocchi con una up sullo stesso semaforo. (Neppure a dirlo, le SYS V IPC mettono a disposizione anche i semafori). Il meccanismo funziona perché:
Le pagine corrispondenti a segmenti condivisi non sono soggette alla paginazione usuale, ovvero, per il resto del Sistema Operativo č come se fossero lockate in memoria. I numeri:
Detto sottovoce, abbiamo perso la linearitŕ con il numero di byte del messaggio. Si intuisce che ora la complessitŕ in tempo di una send o di una receive č lineare, ancora, sě, ma nel numero di modifiche da apportare alle tabelle di rilocazione, ovvero, nel numero di pagine del messaggio da ricevere/spedire. Il confronto con le pipe:
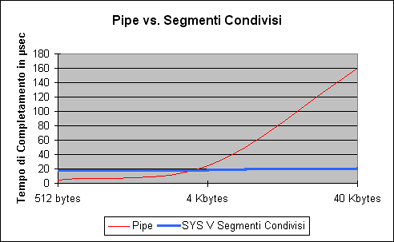
Perň, perň, perň. Niente male. Tuttavia, noi siamo informatici e possiamo fare meglio. Hey... cos'č quel tratto della curva rossa che cade sotto quella blu? Eh... possiamo ancora ridurre gli overhead. E poi? Il modello di programmazione? Non auguro a nessuno di dover mai avere a che fare con le primitive SYS V. Scandalose. Dobbiamo cambiare la situazione. Ma per farlo, bisogna sporcarsi le mani sul serio... |
|
|
Il problema č chiaro.
Partiamo dallo studio di fattibilitŕ. Prima di implementare un set di primitive per l'IPC dobbiamo porci la domanda: esistono giŕ dei prodotti software che fanno questa cosa qui? Beh, se ne sono andate 7 pagine di Word, per parlare delle soluzioni alternative. Ma noi non siamo soddisfatti. Allora dobbiamo chiederci: si puň fare meglio? Per rispondere, cfr. [VAN1] e [VAN2]. Ok. Cominciamo. Chi si avvicina allo sviluppo di parti del nucleo di Linux, ha due opzioni: sviluppare le funzionalitŕ come un modulo che possa essere caricato nel nucleo dinamicamente; oppure compilare le nuove funzionalitŕ direttamente insieme ai sorgenti del nucleo stesso. La prima strada č impossibile da percorrere, perché dobbiamo modificare strutture dati come il PCB del processi e definire nuove chiamate di sistema. Quindi, si deve ricompilare tutto ab origine. La visione ad alto livello dei nuovi meccanismi di IPC č una struttura gerarchica a livelli (e cosa non č una struttura gerarchica a livelli, in informatica? Forse, giusto Linux :-)...). I livelli sono 3:
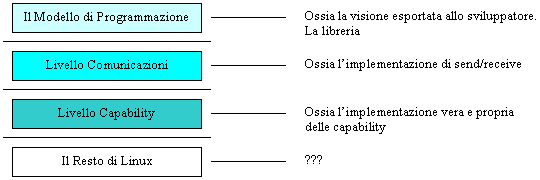
Noi li analizzeremo dal basso verso l'alto. L'idea č semplice. A ha un messaggio per B. Dove ce l'ha? Nel suo proprio personale privato spazio di indirizzamento logico. B lo vuole. Per implementare il trasferimento di questa informazione, A fa una send su un canale. Cosa scrive sul canale? La capability del messaggio secondo [VAN2]. Ovvero una struttura che č cosě definita:
#define physical_address_t unsigned long
#define logical_address_t unsigned long #define prot_t unsigned long
typedef struct
Cioč 16 bytes. Quanto ci vuole per copiarli? 0 µsec: sono 4 load e 4 store. 2 cicli di clock della macchina sono piů che sufficienti. 0 µsec.
addresses č un vettore di size posizioni. Conserva le righe della tabella di rilocazione
di A relative al messaggio da spedire. 1 riga = 1 pagina del messaggio.
Ok. B fa la receive. Legge la capability dal canale di comunicazione. Cosa ci fa? La acquisisce. Per ogni pagina (for (count=0; count<size; ++count)) inserisce addresses[count] nella propria tabella di rilocazione. Calcola dinamicamente l'indirizzo logico per accedere al messaggio e... il gioco č fatto. Ho ampliato dinamicamente lo spazio di indirizzamento logico di B per permettergli di acquisire il messaggio di A. E' come se avessi fatto una malloc che mi ha inizializzato le pagine con le informazioni del messaggio di A.. SALVO IL FATTO CHE IL MESSAGGIO NON E' STATO DUPLICATO NE' COPIATO. Come č fatto il canale? E' una banalissima coda FIFO:
typedef struct ch
{ int n; int filled; int insert; int extract; capability** cap; struct wait_queue* full; struct wait_queue* empty; } channel;
n č il grado di asincronia del canale, e non vedo perché il programmatore non debba avere
la possibilitŕ di stabilirlo per i propri scopi...
Gli algoritmi di send e receive non sto a riportarli, tanto li conosciamo a memoria. Per chi avesse dubbi, [VAN1]. Se il messaggio sta nello spazio di indirizzamento logico di A (e dopo la receive, anche di B), dove sta il canale? Il canale č allocato dal nucleo. In stato supervisore. Insomma, sta nello spazio di indirizzamento dell'(n+1) processo del sistema. E' indirizzato con indirizzi fisici (chiedo venia :-)...). Ogni volta che un processo richiede un canale di comunicazione, il nucleo alloca lo spazio necessario ed inserisce la struttura in una lista doppiamente linkata di canali.

Ogni canale ha un identificatore unico (a 32 bit!!! Quindi, circa 4 miliardi di canali, al massimo...) E la lista č ordinata per identificatore. Se la lista diventa piů grande di ECBM_COMM_RES_MAX viene costruito un albero binario di ricerca con indice l'identificatore. L'albero č un AVL, ovvero un albero binario di ricerca autoribilanciante: insomma, ha altezza pari al logaritmo a base 2 del numero di canali in esso contenuti. (La ricerca dei canali nelle strutture č frequente. L'albero binario di ricerca bilanciato č l'ottimo, quanto a struttura dati). A e B dovranno acquisire il canale con lo stesso identificatore. Esattamente come con le SYS V IPC dovevano chiamare la shmget con lo stesso parametro. I canali aperti e le capability acquisite (e non ancora rilasciate) da ogni processo sono conservate in una struttura simile alla tabella dei file aperti. Gli indirizzi (fisici!!!) base della tabella dei canali e delle capability sono contenuti nel PCB del processo. L'ultima annotazione č che le pagine che costituiscono i messaggi da spedire sul canale sono lockate in memoria finchč il processo B non rilascia esplicitamente la capability corrispondente. Notiamo sin d'ora che avere le pagine lockate in memoria non č condizione necessaria per l'applicabilitŕ dei meccanismi di comunicazione basati su capability. Semplicemente, semplifica il mio lavoro e non mi fa impazzire con lo swapping di linux. Ultimo passo. Il modello di programmazione ad alto livello. Voglio che i sorgenti di A e B siano fatti cosě:
A::
#include <stdio.h>
int main(int argc, char* argv[])
/*
/* Formatta il messaggio da spedire a B */
/*
#include <stdio.h>
int main(int argc, char* argv[])
/*
/*
/* Lavora sul messaggio di A */
/* Rilascia il segmento logico acquisito
Notiamo che B non alloca spazio per buffer. Se ne occupa la zc_receive(). Il file my_channel.h sarŕ una cosa del tipo:
my_channel.h::
#define MY_CH
Credo, quanto meno, che sia pulito e semplice. Chiaramente, A e B possono essere compilati separatamente (cosa non possibile se utilizzo quella bella invenzione delle pipe senza nome). Perché questo modello sia quello realmente utilizzabile, dobbiamo definire 5 nuove chiamate di sistema. Una chiamata di sistema č un frammento di codice caricato staticamente in memoria, eseguito in stato supervisore (chiedo venia :-)...), cioč a indirizzi fisici (IC, il program counter, č caricato con indirizzi fisici delle istruzioni; tutti i riferimenti ai dati sono attraverso indirizzi fisici; no controllo di protezione a Firmware ecc.). Per eseguire una chiamata di sistema, č necessario eseguire una trap al kernel (oops...). Tutte le funzioni della libreria standard C che eseguono chiamate di sistema in realtŕ sono wrapper (involucri) per le system call e il loro unico scopo č formattare i parametri della system call ed eseguire la trap al kernel. Come si fa la trap al kernel? Per ragioni storiche, eseguendo in modo utente l'istruzione assembler INT 0x80. Nel file linux/arch/i386/kernel/traps.c si legge:
984 set_trap_gate(18,&machine_check);
985 set_trap_gate(19,&simd_coprocessor_error); 987 set_system_gate(SYSCALL_VECTOR,&system_call); dove SYSCALL_VECTOR vale 0x80. Chiamando INT 0x80, la macchina passa in stato supervisore e viene eseguito il codice il cui entry point č &system_call. Cos'č system_call? In linux/arch/i386/kernel/entry.S (codice assembler, ohohhhh!!!. Meraviglia :-O!), si legge:
202 ENTRY(system_call)
203 pushl %eax # save orig_eax 204 SAVE_ALL 205 GET_CURRENT(%ebx) 206 testb $0x02,tsk_ptrace(%ebx) # PT_TRACESYS 207 jne tracesys 208 cmpl $(NR_syscalls),%eax 209 jae badsys 210 call *SYMBOL_NAME(sys_call_table)(,%eax,4) 211 movl %eax,EAX(%esp) # save the return value Che detto in informatichese č nient'altro che un salto forzato, o goto calcolato. Cosa??? E' il risultato della compilazione di un enorme case:
case(sys_call_num) of
La normale funzione di libreria (user-space) non fa altro che mettere nel posto giusto il numerino magico della chiamata di sistema ed eseguire INT 0x80. Da questo punto in poi, eseguiamo codice a indirizzi fisici, nello spazio del kernel. I numerini magici sono scritti nel file linux/include/linux/asm/unistd.h.
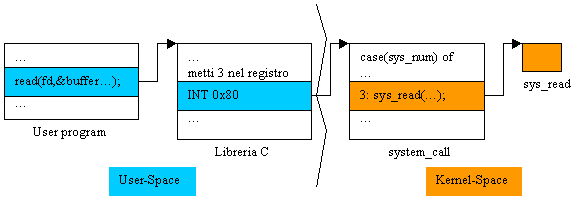
Noi abbiamo il programma utente, l'implementazione delle chiamate di sistema (send, receive ecc) e chiaramente la system_call. Ci manca la funzione di libreria che esegua l'INT 0x80 con i giusti parametri. Ah... ci mancano anche nuovi numerini magici per le nostre chiamate... I numerini magici li aggiungiano in linux/arch/i386/kernel/entry.S (codice assembler, ohohhhh!!!. Meraviglia :-O!): basta dire:
/*
* System Calls for ECBM */
/*
/*
E anche in linux/include/linux/asm/unistd.h:
/*
* System Call Numbers for ECBM */
/*
/*
/*
Le funzioni che richiamino opportunamente la system_call con l'INT 0x80 sono definite in linux/include/linux/ecbm/ecbm.h, in modo che siano disponibili ogni volta che, nei sorgenti dei nostri programmi, scriviamo #include <linux/ecbm/ecbm.h>. Ecco le definizioni:
/*
* Functions to install and acquire * a new communication channel * and to transfer messages among different * process's logical address spaces */ static inline _syscall0(id_t,get_magic_number) static inline _syscall2(id_t,install,magic_number_t,magic,int,asynchrony) static inline _syscall1(id_t,acquire,magic_number_t,magic)
static inline _syscall4(int,zc_send,id_t,id,void*,buffer,int,size,prot_t,rights)
Ah. I meccanismi implementati prendono il nome di ECBM, ovvero Efficient Capability-Based Messaging. :-) I numeri:
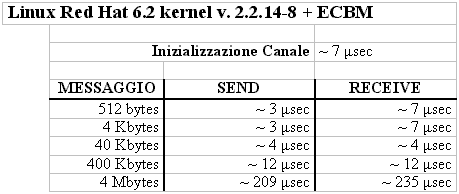
Il confronto con tutto il resto:
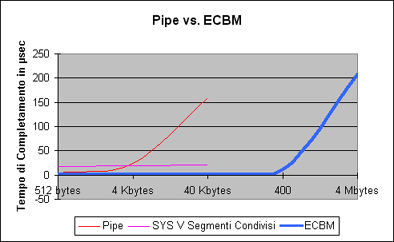
Devo spedire 4 Mbyte di dati per ottenere i tempi che una send sulla pipe impiega su un argomento di 40 Kbytes. |
|
|
Cosa abbiamo visto oggi? Abbiamo dimostrato un teorema ed il suo corollario.
Teorema: I meccanismi basati sul passaggio dinamico di capability costituiscono una soluzione efficiente e pulita, oltre che sicura, al problema dell'IPC. Corollario: I meccanismi di IPC offerti da Linux e derivati sono strutturalmente inefficienti. A parte gli scherzi, ci sono quattro considerazioni da fare, a conclusione di questo lavoro:
|
|
|
Per chi voglia saperne di piů, una guida inesauribile č senz'altro
[ORLL] Understanding the Linux Kernel, Daniel P. Bovet, Marco Cesati - O'REILLY In particolare:
Per approfondire le capability, senza che ve lo dico
[VAN1] Appunti di Architettura degli Elaboratori I, Marco Vanneschi - SEU
Fortemente sconsigliato, perché altamente fuorviante, per quanto riguarda l'IPC (e non ridete, perché č la veritŕ) [---] Modern Operating Systems, Andrew S. Tanenbaum - Prentice Hall |
![]()
Luca Veraldi
veraldi@cli.di.unipi.it
luca.veraldi@katamail.com
![]()
Campobasso, 7 Settembre 2003