| Marco Cimarosti - Dodici anni di Unicode |
[Home] |
| |
Un mio articolo su Unicode

| |
Marco Cimarosti
Dodici anni di Unicode
in Progetto grafico, numero 1, luglio 2003, pagine 84-97
Ripubblico qui il testo di un articolo
sullo standard Unicode che scrissi
anni or sono per Progetto grafico, la rivista dell’Aiap
(Associazione italiana progettazione comunicazione visiva).
La versione stampata (che si può ancora
ordinare
sul sito dell’Aiap: cliccare “Scegli”)
era decorata con esempi della parola “pace” in varie
lingue, tratti da una
pagina web
di protesta contro la guerra in Iraq che pubblicai insieme a Frank da Cruz,
della Columbia University (New York), e ad altri cittadini del mondo contrari
a quella follia.
Le traduzioni araba ed ebraica della parola “pace” campeggiano
anche sulla copertina, subito sotto il rettangolo rosso.
|
di Marco Cimarosti
Unicode è uno standard che permette di codificare sui
computer tutte le scritture del mondo. Gli standard di codifica precedenti sono
invece tutti progettati per una sola lingua o, al più, per un piccolo gruppo di
lingue. Prima di Unicode, la molteplicità dei sistemi di codifica rendeva
difficile la creazione di prodotti informatici internazionalizzati,
pronti cioè a essere localizzati in qualsiasi lingua. Inoltre, era
pressoché impossibile produrre documenti informatici che contenessero testo in
due o più lingue. Ad esempio, un sito web scritto contemporaneamente in arabo e
in russo è quasi improponibile senza Unicode; eppure, non è difficile
immaginare casi in cui una cosa del genere può essere necessaria: ad esempio
per un dizionario russo-arabo arabo-russo.
Il progetto che si sarebbe poi trasformato nello standard
Unicode iniziò verso la fine degli anni ’80, sulla base di una precedente
ricerca volta a unificare la codifica delle scritture cinese, giapponese e coreana.
Lo standard è stato sviluppato e viene portato avanti da un’apposita
organizzazione, il Consorzio Unicode, al quale partecipano aziende private,
enti pubblici e singole persone di tutto il mondo.
La versione 1.0 di Unicode è uscita fra il 1991 e il 1992,
sotto forma di un libro in due volumi. A questa prima versione sono seguite la
2.0 del 1996 e la 3.0 del 2000, sempre pubblicate a stampa, come anche lo sarà
la prossima 4.0, attualmente in lavorazione. Fra queste versioni principali
vengono pubblicate delle revisioni intermedie, sotto forma di documenti web sul
sito del Consorzio.
Un progetto analogo a Unicode era in corso da qualche tempo
anche alla ISO, l’organizzazione internazionale degli standard. Al momento
dell’uscita della versione 1.0 di Unicode, le due istituzioni decisero di combinare
i propri sforzi: il repertorio di caratteri elaborato per Unicode venne
adottato in blocco dallo standard ISO e, da quel momento in poi, i due standard
si impegnarono a mantenere lo stesso repertorio. Da questo momento, di fatto,
Unicode cessa di essere uno standard privato e inizia a essere una normativa
ufficiale, denominata ISO 10646.
I computer, come si sa, sono macchine capaci solo si
trattare con i numeri. Le immagini, i filmati, i suoni, o qualsiasi altro tipo
di informazione, per poter essere trattati, vengono trasformati in filze di
dati numerici, la cosiddetta codifica digitale. Il testo scritto non fa
eccezione: ogni segno della scrittura viene codificato, viene cioè
trasformato in un numero convenzionale.
Sui computer, il valore massimo di ogni dato numerico
dipende dalla dimensione dell’unità di memoria che lo contiene; tale dimensione
si misura in bit. La più piccola unità di memoria è il byte che,
su pressoché tutti i computer, equivale a otto bit. Otto bit permettono di
rappresentare 256 numeri diversi: da 0 a 255. Con un bit in più, il numero di
combinazioni raddoppia; con un bit in meno si dimezza; in generale, un’unità di
memoria lunga n bit consente 2n combinazioni
(due elevato alla n). Gli informatici esprimono i codici usando le cifre
esadecimali le quali, oltre alle consuete dieci cifre (0-9), comprendono le
sei cifre aggiuntive A, B, C, D, E ed F, che rappresentano i valori compresi
fra dieci e quindici. La comodità di questa notazione risiede dal fatto che
ogni cifra esadecimale corrisponde esattamente a quattro cifre binarie, cioè a
quattro bit; i numeri più frequenti nell’informatica diventano dunque “tondi”:
ad esempio, duecentocinquantasei, scritto in esadecimale, diventa “100”.
Il capostipite delle codifiche moderne è l’ASCII (American
Standard Code for Information Interchange), introdotto nei primi anni ’60.
L’ASCII usa sette bit, per un totale di 128 codici. L’ottavo bit di ogni byte
era inizialmente riservato alla verifica della correttezza della trasmissione
delle informazioni. Sebbene questo standard sia ormai obsoleto, il suo nome è
talmente noto che ancor oggi capita di sentire espressioni come “codice ASCII”,
usate impropriamente nel senso generico di “codice numerico di un carattere”.
Alcuni codici ASCII sono riservati ai cosiddetti caratteri
di controllo; solo 94 codici rappresentano caratteri grafici veri e
propri: lettere maiuscole, minuscole, cifre, punteggiatura e segni vari. Questa
dotazione minima basta a malapena per l’inglese americano: non solo mancano
caratteri come “à”, “ç” o “ß”, necessari per le più diffuse lingue occidentali,
ma manca persino il carattere “£”, necessario per l’inglese britannico.
Per permettere la scrittura di altre lingue, si è dapprima
tentata la via di definire delle varianti nazionali dell’ASCII, sostituendo
alcuni caratteri poco usati con le lettere e i segni necessari per ogni lingua.
Questa pratica si scontrava però con il problema che tutti i caratteri ASCII,
compresi quelli più astrusi, erano ormai diventati indispensabili per vari
linguaggi e notazioni dell’informatica: ridefinire anche solo alcuni di questi
caratteri comportava più problemi che vantaggi. Ad esempio, se fosse ancora in
uso la variante italiana dell’ASCII (ISO 646-IT o UNI 0204-1970), oggi non
potremmo scrivere gli indirizzi di posta elettronica, perché il codice del
carattere “@” era stato riutilizzato per la “ù”.
Intorno agli anni ’80, con il migliorare dei protocolli di
trasmissione, anche l’ottavo bit di ogni byte si rendeva disponibile per la
codifica dei caratteri. Diventava così possibile, mantenendo inalterati i 128
vecchi codici dell’ASCII, aggiungere 128 “codici estesi”, per un totale di 256
caratteri. In questo periodo si assiste a una proliferazione incontrollata
delle codifiche a 8 bit, spesso inventate in modo frettoloso e approssimativo
dagli stessi produttori di computer e di programmi. Fra i tanti esemplari di
questo caravanserraglio si distinguono però anche dei buoni standard, come
l’ISO 8859, che contiene una dozzina di codifiche distinte per gli alfabeti
greco, cirillico, ebraico, arabo, tailandese e per diverse varianti locali
dell’alfabeto latino.
Un centinaio di numeri distinti non sono comunque
sufficienti per codificare la scrittura logografica cinese, giapponese e
coreana. Anche limitandosi ai soli caratteri di uso quotidiano, i codici
necessari per le scritture dell’Estremo Oriente sono diverse migliaia. Il
problema è stato affrontato codificando ogni carattere cinese con una serie di due
byte. Il primo dei due (detto lead byte) identifica, anziché un singolo
carattere, un’intera tabella secondaria di caratteri; il secondo (detto trail
byte) identifica il carattere preciso all’interno di questa tabella
secondaria.
Non tutti i 128 codici disponibili sono usati come lead byte
e trail bye: la maggior parte di queste codifiche nazionali si limita a 94
tabelle secondarie di 94 caratteri ognuna. Ci sono dunque a disposizione un
totale di 8 836 codici a doppio byte: un numero più che sufficiente
per rappresentare tutti i logogrammi di uso comune in ognuna delle lingue
moderne. I caratteri a doppio byte possono essere liberamente mischiati con i
soliti 128 codici ASCII a singolo byte; nelle codifiche dell’Estremo Oriente,
dunque, i codici di carattere hanno lunghezza variabile: uno o due byte.
L’esistenza di una molteplicità di codifiche eterogenee
rappresenta un duplice problema. Da un lato, come si è già detto, ognuna di
queste codifiche non supporta che un numero ristretto di lingue e, dunque, è
difficile o impossibile produrre documenti o applicazioni multilingue;
dall’altro lato, una stessa lingua è spesso rappresentabile con più codifiche
diverse, secondo la marca di computer o il sistema operativo in uso. Con la
seconda faccia del problema si è scontrato chiunque abbia provato a trasportare
documenti di testo da un sistema informatico a un altro: su un computer
scriviamo “caffè” ma, quando portiamo il documento su un altro computer,
leggiamo “caff«”; se però correggiamo la parola in “caffè”, tornando sul
computer di partenza, ci apparirà “caffÔ! Il problema è che lo stesso codice numerico
che il primo computer usa per “è”, il secondo lo usa per “«“; il carattere “è”
c’è anche sul secondo sistema, ma è rappresentato da un numero diverso, quello
che il primo computer usa per il carattere “Ô. Questo fastidioso problema è
noto col termine informatico giapponese mojibake (sostituzione di caratteri’).
Problemi del genere si verificano anche con le
codifiche dell’Estremo Oriente e sono aggravati dall’intrinseca fragilità dei
caratteri a doppio byte. In una sequenza di caratteri a doppio byte, un errore
in un solo byte può propagarsi a tutti i caratteri che seguono, con l’effetto
di trasformare una lunga porzione di testo in una serie di segni senza senso.
Questo avviene perché gli stessi codici numerici vengono usati sia come lead
byte sia come trail byte; la distinzione fra i due casi dipende solo dalla
posizione del byte nella sequenza e quindi, alterando accidentalmente questa
posizione, l’interpretazione dell’intero testo può risultarne menomata.
In tutto il mondo si usano attualmente oltre trenta sistemi
di scrittura distinti, un terzo dei quali è diffuso nella sola India. Molte di
queste scritture si utilizzano solo in una certa area geografica e, spesso, per
scrivere una sola lingua. Alcune, però, sono diffuse su interi continenti, e
servono ognuna per scrivere decine di lingue diverse; è il caso dell’alfabeto
cirillico, usato per molte lingue dell’Europa dell’est e dell’ex Unione
Sovietica, della scrittura araba, usata per le lingue di molti paesi islamici,
e, soprattutto, della nostra scrittura latina, che si adopera in tutti i
continenti e a tutte le latitudini. Lo scopo principale di Unicode è quello di
radunare in un unico codice tutti questi sistemi di scrittura, in modo tale che
tutte le lingue del mondo siano facilmente utilizzabili sui computer. Molto più
numerosi di quelli moderni sono i sistemi di scrittura antichi, quelli che non
si usano più nella pratica quotidiana. Per Unicode, queste scritture hanno ovviamente
una priorità minore, poiché scrivere in lingue antiche è utile solo per scopi
accademici o ludici. Inoltre, mentre delle scritture moderne si conosce tutto,
su quelle antiche esistono spesso zone d’ombra, che vengono chiarite poco a
poco solo col faticoso progredire della ricerca. Per queste ragioni, sono ancora
poche le scritture storiche attualmente comprese in Unicode; molte altre sono
allo studio e, prima o poi, faranno il loro ingresso nello standard.
La Tabella 1 elenca tutti i sistemi di
scrittura attualmente supportati da Unicode e, per ognuno di essi, mostra un
esempio e alcune informazioni di base.
|
|
Sistema di scrittura
(e versione di Unicode in cui fu aggiunta) |
Area geografica
(e note sull’uso) |
Numero di caratteri
(e quanti non scomponibili) |
Codici dei caratteri |
Difficoltà tecniche |
| 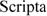
|
latino o romano |
ovunque |
838 (244) |
0000-02AF (ecc.) |
D |
| 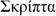
|
greco |
Grecia, Cipro |
326 (73) |
0370-03FF (ecc.) |
D |
| 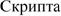
|
cirillico |
Europa, Asia |
235 (183) |
0400-052F (ecc.) |
D |
| 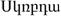
|
armeno |
Armenia |
83 (77) |
0530-058F |
- |
| 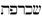
|
ebraico |
Israele |
74 (30) |
0590-05FF |
B D |
| 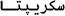
|
arabo |
Africa, Asia |
871 (129) |
0600-06FF (ecc.) |
B C D L |
| 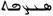
|
siriaco (3.0) |
Asia (desueta) |
56 |
0700-074F |
B C D L |
| 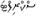
|
thâna o divehi (3.0) |
Maldive |
49 |
0780-07BF |
B D |
| 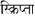
|
devanagari o nagri |
India, Nepal |
101 (90) |
0900-097F |
C D L R |
| 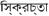
|
bengalese |
India, Bangladesh |
80 (75) |
0980-09FF |
C D L R |
| 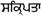
|
gurmukhi o pañjabi |
India |
75 (69) |
0A00-0A7F |
C D L R |
| 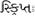
|
gujarati |
India |
78 |
0A80-0AFF |
C D L R |
| 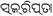
|
oriya |
India |
78 (73) |
0B00-0B7F |
C D L R |
| 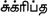
|
tamil |
India, Sri Lanka |
61 (57) |
0B80-0BFF |
C D L R |
| 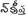
|
telugu |
India |
80 (79) |
0C00-0C7F |
C D L R |
| 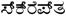
|
kannada o canarese |
India |
80 (75) |
0C80-0CFF |
C D L R |
| 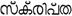
|
malayalam |
India |
78 (75) |
0D00-0D7F |
C D L R |
| 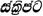
|
cingalese (3.0) |
Sri Lanka |
79 (75) |
0D80-0DFF |
C D L R |
| 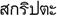
|
tailandese |
Tailandia |
83 (82) |
0E00-0E7F |
D |
| 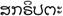
|
laotiano |
Laos |
65 (62) |
0E80-0EFF |
D |
| 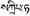
|
tibetano (2.0) |
Tibet, Bhutan |
139 (120) |
0F00-0FFF |
C D L |
| 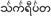
|
myanmar (3.0) |
Birmania |
72 (71) |
1000-109F |
C D L R |
| 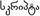
|
georgiano |
Georgia |
77 |
10A0-10FF |
- |
| 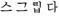
|
hangul |
Corea |
11 558 (240) |
1100-11FF (ecc.) |
L V |
| 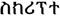
|
etiopico (3.0) |
Etiopia, Eritrea |
337 |
1200-137F |
- |
| 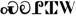
|
cherokee (3.0) |
Stati Uniti |
85 |
13A0-13FF |
- |
| 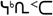
|
cree o canadese (3.0) |
Canada settentrionale |
628 |
1400-167F |
- |
| 
|
ogham (3.0) |
Irlanda (estinta) |
26 |
1680-169F |
V |
| 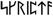
|
runico o futhark (3.0) |
Europa (estinta) |
78 |
16A0-16FF |
- |
| 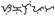
|
tagalog (3.2) |
Filippine (estinta) |
19 |
1700-171F |
D V |
| 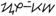
|
hanunóo (3.2) |
Filippine (estinta) |
20 |
1720-173F |
D V |
| 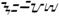
|
buhid (3.2) |
Filippine (estinta) |
20 |
1740-175F |
D V |
| 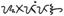
|
tagbanwa (3.2) |
Filippine (estinta) |
18 |
1760-177F |
D V |
| 
|
khmer (3.0) |
Cambogia |
94 |
1780-17FF |
C D L R |
| 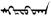
|
mongolo (3.0) |
Mongolia Interna |
140 |
1800-18AF |
C L V |
| 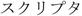
|
kana |
Giappone |
231 (120) |
3040-30FF,
31F0-31FF |
D V |
| 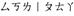
|
bopomofo |
Cina (desueta) |
64 |
3100-312F |
D V |
| 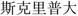
|
han |
Cina, Giappone, Corea |
71 382
(70 331) |
3400-9FFF,
20000-2A6DF (ecc.) |
V |
| 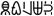
|
yi o lolo (3.0) |
Cina |
1 215 |
A000-A4CF |
V |
| 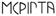
|
paleoitalico (3.1) |
Italia (estinta) |
31 |
10300-1032F |
- |
| 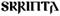
|
gotico (3.1) |
Europa (estinta) |
27 |
10330-1034F |
- |
| 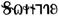
|
deseret (3.1) |
Stati Uniti (desueta) |
76 |
10400-1034F |
- |
Tabella 1 • Le scritture di Unicode. Per la
colonna Difficoltà tecniche: C - le lettere hanno glifi contestuali; D -
usa diacritici combinanti; B - ha orientamento bidirezionale; L - le lettere
formano legature dinamiche; R - richiede il riordino dei glifi; V - può avere
andamento verticale.
La maggior parte delle scritture sono di tipo fonetico
(o cenemico, vuoto di significato’), cioè sono basate prevalentemente
sulla corrispondenza fra segni della scrittura e suoni della lingua parlata; in
queste scritture, i fatti ortografici non legati alla pronuncia (come la “h”
dell’italiano “hanno”) sono abbastanza eccezionali. Esiste un secondo tipo di
scrittura, detto logografico (o pleremico, pieno di
significato’), nel quale l’informazione semantica ha importanza pari a quella
fonetica; l’unica scrittura pleremica moderna è quella cinese, che è usata
anche per la lingua giapponese e, in misura minore, per quella coreana.
Le scritture fonetiche comprendono generalmente poche decine
di lettere, tante quanti sono i suoni (fonemi o sillabe) di una lingua; le
scritture logografiche, invece, comprendono molte migliaia di segni, tante
quante solo le unità lessicali (parole, morfemi). La scrittura cinese è sempre
stata un problema per l’informatica a causa del gran numero di caratteri
necessari. Per altre scritture, è sempre possibile elencare tutti i caratteri
in una breve lista che segue un ordine canonico: a, bi, ci,
di
zeta. Per la scrittura cinese, una cosa del genere non è e non
sarà mai possibile, e questo ha sempre costituito un grave ostacolo per la
costruzione di una codifica unica del testo per i computer. Si sa solo che di
questi caratteri ne esistono decine di migliaia e che ogni persona non ne usa
che poche migliaia.
Uno dei compiti più complessi che si trovarono di fronte i
progettisti di Unicode fu quello della Han Unification, cioè il compito
di definire un unico repertorio di caratteri han (cinesi’) che coprisse
completamente l’ortografia moderna delle lingue cinese, giapponese e coreana.
Il punto di partenza della Han Unification furono i set di caratteri per
computer che erano già in uso nei paesi dove si parlano queste lingue. Ognuno
di questi set di caratteri non conteneva che poche migliaia di caratteri,
quelli strettamente necessari alla scrittura di ognuna di queste lingue.
Sebbene questi set nazionali contenessero in larga parte gli stessi caratteri,
il codice assegnato a ognuno di essi era completamente diverso, poiché
prevaleva la pratica di elencare i caratteri in ordine di pronuncia, e la
pronuncia di ogni carattere cambia ovviamente da lingua a lingua. La scelta di
Unicode fu quella di elencare i caratteri in ordine di radicali,
rubricandoli sotto i 214 radicali (o chiavi) del dizionario
settecentesco cinese Kang Xi. Dal momento che l’ordinamento per radicali
fa affidamento solo sulla forma dei logogrammi, prescindendo completamente
dalla loro pronuncia, questo sistema si presta meglio alla vocazione
internazionale di Unicode, evitando di privilegiare una o l’altra lingua.
Ma riportare tutti i logogrammi già utilizzabili sui
computer non era che un primo passo. Uno dei difetti più sentiti dei set di
caratteri dell’Estremo Oriente è che essi contengono troppo pochi caratteri.
Sebbene ogni persona, anche di cultura abbastanza elevata, non arrivi mai a
conoscere tutti gli otto o novemila logogrammi contenuti nei set di caratteri
nazionali (ai cinesi bastano circa quattromila caratteri, che si riducono a un
migliaio per i giapponesi), è vero anche che ogni persona conosce e usa occasionalmente
alcuni caratteri non compresi in questo repertorio minimo. Si tratti di caratteri
usati solo nei nomi propri, o di parole antiche che sporadicamente arricchiscono
ancora la prosa dei contemporanei, o di termini tecnici, settoriali,
dialettali: sta di fatto che spesso e volentieri i cinesi e i loro vicini si
arrabbiano perché il computer non gli permette di digitare un carattere che pur
esiste sul dizionario. La versione 1.0 di Unicode uscì con quasi 21 000
logogrammi cinesi, più di quanti se ne fossero mai visti in una codifica per
computer. Oltre che dai set nazionali, questi caratteri provengono da molti
vocabolari cinesi, giapponesi, coreani e vietnamiti, sia moderni che antichi.
La cosiddetta Estensione A, aggiunta nella versione 2.0, portò altri
6 000 logogrammi circa, e quasi 43 000
ne arrivarono con l’Estensione B, aggiunta nella versione 3.0.
Nonostante gli oltre 70 000 logogrammi cinesi attuali,
pare che ancora Unicode non sia completo, non comprendendo ancora tutti
i caratteri cinesi di cui si conosce l’esistenza; contemporaneamente, però,
comincia a farsi sentire l’obiezione opposta: ci si chiede a chi possano mai
servire realmente tutti quei caratteri; chi mai li può conoscere e usare;
quante speranze ci sono che qualcuno metterà realmente in commercio font e
altri strumenti informatici che li comprendano tutti. I caratteri
dell’Estensione B sono spesso parole antiche di uso rarissimo, quando non
addirittura hapax legomena: caratteri usati una sola volta nella
storia della letteratura.
Molti si chiedono se, contrariamente all’uso consolidato
nell’informatica, non sarebbe stato più opportuno sfruttare il fatto che la grandissima
maggioranza dei caratteri cinesi è composta di due elementi più semplici
combinati fra loro: sarebbe dunque stato teoricamente possibile codificare i
singoli componenti (che, a quanto pare, sono poche centinaia). Il
problema è che, per far questo, bisognerebbe passare in rassegna tutte le
decine di miglia di logogrammi esistenti per estrapolare la lista di componenti
elementari che li compone tutti; bisognerebbe poi elencare tutte le
combinazioni possibili di questi elementi, in modo da poter convertire i logogrammi
così composti da e per le codifiche tradizionali; infine, bisognerebbe
progettare dei font talmente “intelligenti” da saper spostare e deformare i
glifi dei componenti nel modo necessario a comporre dinamicamente ogni logogramma.
Unicode comprende inoltre un’ampia scelta di segni non
lessicali: numerali, segni di punteggiatura, simboli commerciali e tecnici,
operatori matematici, simboli musicali, eccetera. Sono presenti anche molti
simboli che niente hanno a che fare con la scrittura: forme geometriche,
frecce, segmenti di linea e icone di vario tipo (come ad esempio, i pezzi degli
scacchi, i semi delle carte da gioco, fregi, fiorellini, stelline, nuvolette, pupazzi
di neve, telefoni, forbici, simboli di varie religioni e ideologie, eccetera).
Questi simboli, totalmente ridondanti, fanno parte di Unicode solo per ragioni
di compatibilità, per permettere cioè di convertire in Unicode testi
scritti con altre codifiche che prevedono questi simboli.
Infine, un grosso numero di codici è riservato per l’uso
privato. Unicode non definisce il significato di questi caratteri e lascia che
ognuno li usi come meglio crede. Esistono tre PUA (Private Use Areas),
per un totale di 133 376 caratteri. Le PUA sono il paradiso di chi si
occupa di studiare le scritture antiche o di “inventare” scritture fantastiche.
Fin dall’inizio, la scelta progettuale più importante di
Unicode fu che ogni carattere doveva occupare 16 bit. Un byte da 8 bit, con le
sue 256 combinazioni, non poteva certo bastare ma, d’altra parte, i progettisti
di Unicode volevano evitare l’architettura complicata e fragile delle codifiche
dell’Estremo Oriente, dove il codice dei caratteri è formato da un numero
variabile di byte. Un’unità di memoria da 16 bit (chiamata word o short
integer) permette di avere 65 536 combinazioni diverse che, espresse
in cifre esadecimali, vanno da 0 a FFFF. Questo numero pareva perfettamente
adeguato agli scopi di Unicode: la versione 1.0 dello standard utilizzava poco
meno della metà delle combinazioni, ma già comprendeva quasi tutte le scritture
moderne, inclusi più di 21 000 caratteri cinesi. Le poche scritture ancora
mancanti erano tutte fonetiche e non richiedevano, dunque, che qualche decina
di caratteri ognuna. Rimaneva ancora tantissimo spazio, dove si riteneva che
potessero trovare posto le principali scritture antiche, dalle rune ai geroglifici
egizi.
I calcoli, però, dovevano rivelarsi errati. Lo spazio
rimanente non era sufficiente per tutte le scritture antiche e, soprattutto, il
numero dei caratteri cinesi rari e antichi era di molto superiore alle
aspettative. Quando gli istituti di standardizzazione di Cina, Giappone e Corea
estrassero dal cappello 50 000 nuovi caratteri, fu evidente che
l’architettura a 16 bit non era più adeguata. Per mantenere l’idea di partenza
che ogni carattere dovesse occupare un numero fisso di bit, la successiva unità
di memoria utile sarebbe stata quella da 32 bit (detta doppia word o long
integer), che permette oltre quattro miliardi di caratteri. Se questa
soluzione era interessante da certi punti di vista, era assolutamente eccessiva
da altri: caratteri di 32 bit (cioè di quattro byte) avrebbero comportato di
raddoppiare la dimensione di tutti i documenti scritti nelle lingue
dell’Estremo Oriente, e addirittura di quadruplicare la dimensione di quelli
del resto del mondo. Inoltre, a metà degli anni ’90, Unicode era ormai già
usato in molti prodotti software: un cambiamento simile avrebbe comportato di
buttare via tutto questo software e di riscriverlo da capo.
La soluzione proposta da Unicode si chiama UTF-16 (16
bit Unicode transformation format) ed è il classico tentativo di salvare
capra e cavoli. Vennero riservati 1 024 codici, detti surrogati alti
(high surrogates) e altrettanti detti surrogati bassi (low
surrogates). Ogni possibile sequenza formata da un surrogato alto seguito
da uno basso codificava un cosiddetto carattere surrogato: diventava
dunque possibile codificare 1 024 × 1 024 nuovi caratteri, cioè
1 048 576. Questo milione abbondante di nuovi codici è suddiviso in
16 piani da 65 536 codici ognuno. I 65 536 caratteri
dell’Unicode a 16 bit si chiamano ora piano zero o BMP (Basic
Multilingual Plane); i rimanenti 16 piani sono numerati da 1 a 16 e si chiamano
piani estesi o piani surrogati. I codici dei piani estesi, in
cifre esadecimali, vanno da 10000 a 10FFFF. Il sistema dei codici surrogati
implica però che i caratteri Unicode non sono più di dimensione fissa: alcuni
caratteri richiedono una word da 16 bit e altri ne richiedono due. Com’è
facile immaginare, questa soluzione ha attirato feroci critiche, in quanto tradisce
l’originario principio dei caratteri a lunghezza fissa e, in un certo senso, fa
rientrare dalla finestra le codifiche a doppio byte, che erano appena state cacciate
dalla porta.
A questo punto, qualcuno pensò che, se proprio bisognava
tornare alle codifiche a lunghezza variabile, tanto valeva recuperare come
unità fondamentale il vecchio byte da 8 bit. Nel 1996, François Yergeau, un
progettista della Alis Technologies, presentò una request for comments
destinata a fare strada: RFC 2044 UTF-8, a transformation standard for ISO
10646 (le RFC sono i documenti con i quali si propone formalmente
l’adozione di un nuovo standard per Internet). L’UTF-8 è un codice multibyte
che permette di rappresentare tutti i caratteri di Unicode in un formato compatibile
con l’ASCII e, dunque, con molti dei vecchi programmi non abilitati ai
caratteri da 16 bit. L’UTF-8 rappresenta i 128 caratteri compresi nel vecchio
codice ASCII con un singolo byte; tutti gli altri valori sono rappresentati con
sequenze lunghe da due a sei byte, per un totale di oltre due miliardi di
codici diversi: ben più di quanto necessario a Unicode. Questa grande cardinalità
non è l’unico vantaggio rispetto alle vecchie codifiche a doppio byte
dell’Estremo Oriente: l’UTF-8 è progettato in modo tale da essere stateless,
cioè un eventuale errore su un byte interessa solo il carattere codificato con
quel byte: non è possibile che l’errore si propaghi ai caratteri che seguono,
rendendo così inutilizzabile l’intero testo. L’idea dell’UTF-8 era talmente
buona che ben presto fu adottato come secondo UTF ufficiale. Oggi l’UTF-8 si
avvia a diventare la forma più comune di Unicode: le e-mail e le pagine web in
Unicode, ad esempio, utilizzano prevalentemente l’UTF-8.
All’UTF-8 e all’UTF-16 si è aggiunto recentemente l’UTF-32
il quale, utilizzando doppie word da 32 bit, recupera l’antica
semplicità dei caratteri a dimensione fissa. Come già detto, usare unità da 32
bit costituisce però un enorme spreco di spazio. Ma l’UTF-32 si usa quasi
esclusivamente come formato interno dei programmi; in questo caso, lo spreco è
tollerabile in quanto riguarda solo quel poco testo che il programma sta
elaborando in un certo momento. Ad esempio, mentre ho questo articolo aperto
nella finestra del mio word processor, è probabile che il testo che vedo sia
codificato in UTF-32. Non appena salverò il documento, il testo verrà scritto
sul disco in un UTF più compatto.
Per mostrarci un testo sullo schermo o stamparlo su carta,
il computer ha bisogno di codificare due tipi di informazioni ben diverse:
1. il puro e semplice contenuto del testo, l’equivalente di un originale
dattilografato;
2. la forma o layout del testo, cioè una serie di codici che ne
definiscono il formato (numero di colonne, larghezza dei margini, eccetera) e
che indicano i punti dove iniziano e terminano determinati attribuiti grafici
(il tipo di font, la dimensione del testo, il suo colore, eccetera).
Chi pratica la professione di grafico utilizzando un
computer si occupa, sostanzialmente, di decidere e di impostare tutti i parametri
necessari al punto 2, cioè di definire la forma grafica del testo. È bene
precisare che Unicode (e qualsiasi altro standard per la codifica del testo) si
occupa invece solo e unicamente del punto 1. Un testo digitale che contenga
solo la codifica del contenuto si definisce testo semplice (plain
text); se invece contiene anche informazioni sul formato tipografico si
definisce testo ricco (rich text). Unicode si occupa di
codificare il plain text. Le informazioni aggiuntive necessarie al rich
text vengono definite da Unicode protocollo di livello superiore (higher
level protocol), e la loro codifica viene ignorata in quanto considerata
materia di pertinenza di altri standard.
Proprio a causa della loro indeterminatezza grafica, i
caratteri di Unicode si definiscono caratteri astratti. I caratteri
visibili sullo schermo si definiscono invece glifi e l’esatta
definizione della loro forma dipende dal font utilizzato e dalle scelte estetiche
fatte da chi l’ha progettato.
Con le codifiche e i font attualmente in uso, siamo abituati
al fatto che a ogni carattere corrisponda un solo glifo, sempre lo stesso.
Siamo anche abituati al fatto che i glifi che vediamo sullo schermo abbiano la
stessa posizione dei corrispondenti caratteri nella memoria del computer. In
Unicode le cose non stanno sempre così: i caratteri astratti hanno un rapporto
complesso con i glifi. A ogni carattere possono corrispondere due o più glifi;
la scelta di quale glifo usare dipende dal contesto, cioè dalla
posizione in cui il carattere si trova e dai caratteri che lo circondano. Sequenze
di due o più caratteri sono in alcuni casi visualizzate con un unico glifo
congiunto, detto legatura. La posizione dei glifi sullo schermo non è
sempre uguale alla posizione del corrispondente carattere in memoria: due
caratteri contigui possono trovarsi a essere visualizzati ai lati opposti dello
schermo, mentre i glifi di caratteri lontanissimi possono trovarsi a essere
adiacenti. In Unicode questa complessa corrispondenza è definita da una
specifica chiamata modello carattere/glifo. La messa in pratica di questo
modello teorico è compito di un modulo software, che ogni computer che supporta
Unicode deve contenere, che si chiama motore di rendering (rendering
engine) e che fa da ponte fra il testo astratto e i font. Lo standard
definisce solo le linee essenziali del modello carattere/glifo in quanto, come
vedremo, molti dettagli dipendono dalle scelte del progettisti dell’interfaccia
utente e, soprattutto, dalle scelte del type designer che ha progettato
il font in uso.
La ragione principale delle differenze fra la posizione
“logica” dei caratteri e la posizione “visiva” dei rispettivi glifi è la bidirezionalità.
In alcune scritture, come quella araba e quella ebraica, le lettere si
susseguono da destra a sinistra, anziché da sinistra a destra come nella nostra
scrittura. Ad esempio, se la parola “kilo” in italiano ha la “k” all’estrema
sinistra e la “o” all’estrema destra, in arabo sarà l’opposto. In Unicode, le
lettere che compongono la parola si codificano in entrambi i casi secondo il
loro ordine naturale, fonetico; cioè, prima “k”, poi “i”, “l” e infine “o”. Il
motore di rendering, sapendo che la scrittura araba è orientata da sinistra a
destra (osd), invertirà la posizione dei glifi di ogni linea di testo.
La faccenda si complica quando, in seno a una linea osd si trova una
segmento orientato da destra a sinistra (ods), come potrebbe essere un
numero o una parola straniera. Per risolvere questo problema, Unicode definisce
un apposito algoritmo bidirezionale, che precisa come si devono spostare
i caratteri per passare dall’ordinamento logico a quello visivo.
La Figura 1 mostra come si comporta
l’algoritmo bidirezionale in un caso semplice: la visualizzazione della voce
“kilo” di un ipotetico glossario arabo-russo. Nella prima linea, vediamo come
il testo astratto è organizzato in memoria: sia nella versione araba sia in
quella russa, la parola inizia con la “k” e finisce con la “o” (anche se in
arabo, veramente, finisce con la “w”). Nella seconda linea, vediamo il primo
passo del processo di rendering: il fatto che il testo inizi con una lettera
araba è sufficiente all’algoritmo bidirezionale per decidere che l’intero testo
è ods e, quindi, la posizione di tutti i caratteri viene rovesciata.
Questo, giustamente, porta il punto finale alla sinistra del testo (cioè alla
fine) e lo spazio alla sinistra (cioè dopo) il due punti. Notiamo, però, che
anche la parola russa è stata rovesciata e che, ora, si legge “oliK”. Il
secondo passo rimedia a questo errore, cercando tutte le sequenze di caratteri osd
e rovesciandoli nuovamente. I caratteri che non appartengono ad alcuna scrittura
specifica, come i segni di punteggiatura e gli spazi, hanno direzionalità
neutra e, quindi, assumono di fatto l’orientamento dei caratteri che li
circondano. Si noterà che, al termine del processo, la “K” iniziale del termine
russo si trova vicino al punto finale, mentre la “o” finale si trova vicino al
due punti e alla parola araba: le regole di Unicode (nonché la logica e la pronuncia)
ci dicono che questo è solo un’illusione: in realtà, la “o” è l’ultima lettera
prima del punto.

Figura 1 • Direzionalità e glifi variabili
Prima di poter mandare al video il nostro testo arabo-russo
è necessario un ultimo passaggio: scegliere le corrette forme contestuali
delle lettere arabe. Le lettere che compongono una parola araba sono tutte
legate l’una all’altra, come nel nostro corsivo manoscritto. Quasi tutte le
lettere si connettono alla lettera successiva per mezzo di un tratto
rettilineo; la lettera finale di ogni parola termina invece generalmente con
una “voluta”. Quasi tutte le lettere arabe hanno dunque quattro forme:
iniziale, finale, mediana e isolata, secondo che la lettera si connetta alla
lettera che la segue, a quella che la precede, a entrambe o a nessuna delle
due. Unicode ha un solo codice per ogni lettera araba; è il motore di rendering
che decide quale dei quattro glifi usare, basandosi sull’analisi delle lettere
vicine.
L’arabo non è l’unica delle scritture di Unicode a
richiedere glifi contestuali. Fra le cosiddette scritture complesse, le
più complesse sono senz’altro quelle dell’India e delle zone vicine (Tibet,
Sud-est asiatico). In queste scritture, ogni lettera consonantica incorpora il
suono della vocale “a”; le altre vocali vengono indicate per mezzo di segni diacritici
scritti sopra o sotto la consonante, oppure su uno o su entrambi i suoi lati.
Dal punto di vista grafico, queste scritture si caratterizzano inoltre per
l’esteso uso delle legature, cioè dell’unione di due o più lettere in un
unico glifo. In particolare, le combinazioni di due o più consonanti non
separate da vocali richiedono quasi sempre l’uso di legature, che fondono in
un’unica forma le consonanti coinvolte. Come nel caso dell’arabo, Unicode
codifica le scritture indiane secondo uno schema logico, fonetico, ignorando dettagli
tipografici come le legature o l’esatto posizionamento dei diacritici vocalici.
Di questi dettagli deve occuparsi, come al solito, il motore di rendering.
La Figura 2 ci mostra il rendering
della parola trimurti (trinità’), scritta nella scrittura devanagari.
La linea superiore mostra come i caratteri astratti sono organizzati in memoria:
i segni vocalici seguono sempre la consonante cui si applicano e le
combinazioni di consonanti (“tr” e “rt”) sono codificate mettendo il carattere
094D (halant o virama) fra ogni consonante. Lo halant è un segno
diacritico che indica che non bisogna pronunciare la vocale “a” incorporata
nella consonante; in pratica, non viene quasi mai mostrato, in quanto esso si
lega quasi sempre alla consonante che lo precede, dando luogo a un glifo detto forma
dimezzata, oppure a quella che lo segue, dando luogo al glifo detto forma
sottoscritta. Entrambi i casi sono rappresentati dalla lettera “r”, nella
seconda linea della Figura 2.
In molti casi, la legatura determinata dallo halant coinvolge entrambe le
lettere che lo circondano, come nel caso della legatura “tr” che troviamo sulla
terza linea. L’ultimo passo è quello di riordinare i glifi che si
presentano visivamente in posizione diversa da quella logica. Nella quarta
riga, le vocali “i” vengono spostate sulla sinistra delle consonanti che
modificano, e la forma dimezzata della “r” viene spostata alla destra
della consonante “t” che, foneticamente, la segue. Le legature non sono appannaggio
esclusivo delle scritture indiane: anche le ben note “ff”, “fi”, “fl” del
nostro alfabeto sono trattate allo stesso modo: non serve che siano codificate
come caratteri a sé stanti: sono solo glifi scelti dal motore di
rendering per rappresentare queste combinazioni. Questo garantisce che la codifica
rimanga indipendente dal font: se legature come “fi” fossero codificate come
caratteri, dovrebbero per forza essere contenute anche in quei font che non le
richiedono, come ad esempio quelli monospaziati.
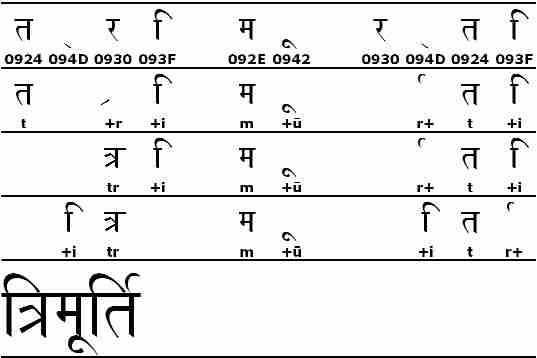
Figura 2 • Legature e riordino dei glifi
Per considerazioni analoghe a quelle fatte per le legature,
Unicode considera un segno come “é” non come un carattere ma come due: la
lettera “e” e il segno diacritico “´”, che la segue. Il compito di mostrare
l’accento sopra la lettera, anziché al suo fianco (“e´”) viene lasciato, come
al solito, al motore di rendering, che deve sapere che alcuni caratteri sono
segni diacritici e che, dunque, vanno posizionati in modo speciale. Trattare i
segni diacritici come caratteri indipendenti offre anche la possibilità di
codificare qualsiasi lettera accentata, come ad esempio una “h” con
l’accento circonflesso, o una “c” con l’accento acuto. Una cosa del genere non
è inutile come potrebbe sembrare, se si considera che le lingue che si scrivono
con l’alfabeto latino sono tantissime. Infatti, la “h” con l’accento
circonflesso si usa in esperanto e la “c” con l’accento acuto si usa in croato.
Ci si potrebbe dunque aspettare che Unicode non contenga alcuna “lettera accentata”
come la “é”. Purtroppo non è così: per motivi pratici (l’inadeguatezza dei
primi motori di rendering, la necessità di convertire il testo da e per le
vecchie codifiche), Unicode comprende anche molte centinaia di caratteri
precomposti, che codificano con un solo codice la sequenza formata da una
lettera e da uno o più segni diacritici. È dunque spesso possibile codificare
la stessa “lettera accentata” in due o più modi diversi. Prima di procedere
alla visualizzazione del testo, è consigliabile ricondurre a unità queste
codifiche alternative, per mezzo di un processo detto normalizzazione.
Il testo può essere normalizzato in due modi opposti: o sostituendo i caratteri
precomposti con i loro elementi costitutivi o, viceversa, sostituendo le
sequenze di lettera e diacritici con i corrispondenti caratteri precomposti. La
prima riga della Figura 3 ci mostra un caso limite:
la “c” con la cediglia e con l’accento acuto può
essere codificata in ben cinque modi diversi. Il primo passo della
normalizzazione consiste nello scomporre tutti i caratteri precomposti,
riducendo così a due le cinque varianti di partenza: “c” + cediglia + acuto e
“c” + acuto + cediglia. Il secondo passo riordina i segni diacritici, spostando
tutti i diacritici che stanno sotto la lettera prima di quelli che le stanno
sopra; il testo è finalmente normalizzato e i cinque casi sono stati ricondotti
a uno solo: “c” + cediglia + accento acuto. Il riordino dei segni diacritici
non sarebbe stato possibile se i diacritici si fossero trovati entrambi sopra
la lettera o entrambi sotto; ad esempio, “u” + dieresi + acuto e “u” + acuto +
dieresi non possono essere assimilati, in quanto hanno significato e aspetto
diversi: mentre nel primo caso il glifo dell’acuto sta sopra quello della
dieresi, nel secondo caso le posizioni si invertono. La forma di
normalizzazione che abbiamo appena visto si chiama scomposizione canonica
(canonical decompositon) o NFD. Con l’ultimo passo, possiamo
trasformare tutte le sequenze di lettera + diacritico nei corrispondenti
caratteri precomposti, laddove questi esistano. Questa seconda forma di normalizzazione
si chiama composizione canonica (canonical composition) o NFC.
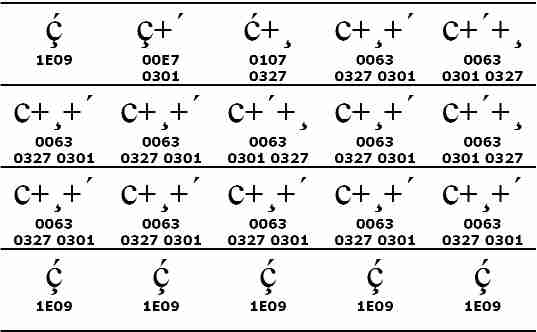
Figura 3 • Forme di normalizzazione
Abbiamo già visto che Unicode non è esente da compromessi.
Le cosiddette “lettere accentate” non sono l’unico caso di caratteri
ridondanti: lo standard comprende parecchie legature (comprese “fi” e “fl”);
forme contestuali delle lettere arabe; varianti tipografiche di lettere e cifre
(corsivo, grassetto, Fraktur, apice, esponente, eccetera), usate per comporre
formule matematiche; doppioni di lettere usate come simboli (ad esempio, “Å”
simbolo di ångström, o “µ”, simbolo di micron). Stando alla teoria del modello
carattere/glifo, tutti questi caratteri non dovrebbero esistere, ma lo standard
li comprende per compatibilità con altri standard, ovvero per permettere di
convertire il testo da altre codifiche in Unicode e poi nuovamente nella
codifica di partenza, senza perdere alcuna informazione. Dal momento che,
comunque, eliminare informazioni ridondanti è spesso un bene, Unicode definisce
anche un tipo di normalizzazione più spinto, che permette di convertire questi caratteri
di compatibilità nei corrispondenti caratteri normali: si hanno dunque
altre due forme di normalizzazione che si chiamano scomposizione di
compatibilità (compatibility decompositon) o NFKD e composizione
di compatibilità (compatibility composition) o NFKC.
Normalizzando il testo con queste forme, la “Å” di ångström diventa la normale
lettera “Å” delle lingue scandinave, la “µ” di micron diventa la normale “m”
greca, la legatura “fi” diventa una “f” seguita da una “i”, eccetera.
Come s’è detto, i dettagli della trasformazione dei
caratteri astratti in glifi cambiano molto da un font a un altro. Ad esempio,
font bastoni o monospaziati potrebbe non avere nemmeno le classiche legature
“fi” o “fl”, mentre font più tradizionali potrebbe avere un repertorio di
legature ben più sofisticato: “ch”, “ct”, “fh”, “fj”, “ij”, “Qu”, “st” e molte
altre. Uno stesso brano di testo può dunque comportare trasformazioni
completamente diverse secondo il font scelto per comporlo. D’altronde, la cosa
non stupisce: come potrebbero le stesse regole tipografiche valere, ad esempio,
per il Verdana e per il Fraktur? Se a questo aggiungiamo l’internazionalità, le
cose non possono che complicarsi: come potrebbero non essere diverse la
tipografia cinese e quella araba, quella indiana e quella europea, quella etiopica
e quella eschimese? La gamma delle variazioni tipografiche è talmente ampia
che, in pratica, per ogni font bisognerebbe riscrivere da capo il motore di
rendering. Per risolvere questo problema, le tecnologie di font più moderne
tendono, in un certo senso, a incorporare il motore di rendering dentro
il font. Un font digitale, ad esempio un font in standard TrueType, era
finora un tipo particolare di archivio di dati contenente informazioni
riguardo un certo stile di caratteri tipografici, come la forma e le misure di
ogni glifo. Comunque, un font era un oggetto inerte, passivo, destinato a essere
semplicemente consultato dal motore di rendering. Ma a causa della
complessità del modello carattere/glifo di Unicode, tutto questo non basta più:
un font deve diventare un componente software attivo, simile un programma,
e deve provvedere autonomamente a effettuare tutte le trasformazioni necessarie
a realizzare la sua particolare concezione del modello carattere/glifo.
O, per meglio dire, la concezione del modello carattere/glifo del progettista
di quel font. Un progettista (o, più realisticamente, un’équipe di progettisti)
che deve dunque saper unire alle tradizionali competenze tipografiche e visive
competenze informatiche e logiche, non dissimili a quelle di un programmatore.
Fra le nuove tecnologie di tipografia elettronica,
sta emergendo soprattutto il sistema OpenType, sviluppato congiuntamente
da Microsoft e da Adobe. I font OpenType sono disponibili su diverse
piattaforme, in particolare sui più recenti sistemi Windows (NT, 2000, XP).
OpenType è un’estensione del precedente sistema TrueType, progettata per
affrontare la complessità del modello carattere/glifo di Unicode. Un font
OpenType contiene tutte le tabelle di dati già disponibili nei font
TrueType, e ne aggiunge molte di nuove. La più importante fra le nuove tabelle
si chiama GSUB e contiene tutte le informazioni necessarie a trasformare
i caratteri astratti in glifi. La tabella GSUB somiglia a una macchina
a stati finiti: un modello matematico che è alla base del funzionamento
stesso dei computer. La GSUB è dunque simile a un programma: una serie
di regole di trasformazione da applicare ai caratteri del testo al fine di ottenere
i corrispondenti glifi. Ogni regola definisce quale trasformazione compiere e a
quale condizione; ad esempio, per ogni lettera araba la regola dirà che
bisogna usare il glifo della forma iniziale se la lettera è seguita ma
non preceduta da un’altra lettera araba. Altre tabelle da menzionare sono la GPOS,
che decide il posizionamento di ogni glifo rispetto a quelli adiacenti (ad esempio,
è grazie a questa tabella che un accento su una lettera maiuscola viene messo
più in alto che non su una lettera minuscola), e la GDEF, che classifica
i glifi e specifica dove il cursore debba essere posto (quest’ultima
informazione è particolarmente importante per le legature: anche se “fi” è un
unico glifo, l’utente deve poter mettere il cursore anche fra la “f” e la “i”).
I font OpenType presuppongono comunque che il motore di rendering abbia
preventivamente effettuato alcune operazioni di base, come l’algoritmo
bidirezionale e il riordino dei glifi per le scritture indiane.
I sistemi MacIntosh rispondono all’OpenType con il
sistema ATSUI (Apple Type Services for Unicode Imaging), parte
del più ampio sistema AAT (Apple Advanced Typography). Anche il
sistema ATSUI è un’estensione del modello TrueType, ma ha alcune
caratteristiche tecniche che lo differenziano da OpenType, rendendolo forse un
po’ più sofisticato. Nei font ATSUI quasi tutta “l’intelligenza” del motore di
rendering è incorporata nel font. L’unica operazione di base che il motore di
rendering debba effettuare prima di mettere in moto il font è l’algoritmo bidirezionale.
Le tabelle mort e gvar dei font ATSUI corrispondono all’incirca
alla GSUB dell’OpenType, ma permettono una gamma di trasformazioni più
ampia, comprendendo anche il riordino dei glifi.
Oltre a quelli dei due protagonisti, Microsoft e
Apple, esistono molti altri progetti di tipografia elettronica avanzata.
Bisogna almeno menzionare il sistema Graphite, sviluppato dal SIL
(Summer Institute of Linguistics, un istituto che si occupa di etnologia
e di linguistica). Anche Graphite estende i font TrueType. Assomiglia molto ad
ATSUI, con la differenza che è orientato a piattaforme di scarsa potenza, come
i vecchi sistemi Windows che ancora si trovano comunemente nei paesi del Terzo
Mondo. Lo scopo dichiarato di Graphite è infatti quello di mettere Unicode al
servizio dei linguisti che lavorano sul campo, nello studio delle lingue in via
d’estinzione. È probabile che questo nobile tentativo stia perdendo d’attualità
con l’avanzare del progetto FreeType, che è un’implementazione libera
del sistema OpenType, adatto a qualsiasi tipo di computer.
Con la diffusione di queste nuove tecnologie di
tipografia digitale, Unicode cessa, a dodici anni dalla sua nascita, di essere
una bella teoria e diventa una realtà, a disposizione di chiunque usi un
computer. Le barriere che fino a ieri impedivano di usare sui computer molte
delle lingue umane stanno per crollare definitivamente. È ovvio che a molte
persone questo cambiamento non interesserà minimamente, ed è probabile che
molti non lo noteranno nemmeno. Alcuni ambienti, però, non mancheranno di
trarre vantaggio dalle nuove possibilità di internazionalizzazione offerte da
Unicode. La possibilità di comunicare in lingue fino a ieri inaccessibili apre
nuove possibilità per diversi settori. Questa possibilità potrebbe porre sfide
nuove anche ai grafici che, ad esempio, potrebbero vedersi commissionare
progetti che prevedano anche la localizzazione nelle lingue dell’India,
del Medio Oriente, dell’Asia orientale. Per i grafici, questo potrebbe costituire
una sfida culturale: quella di rivedere le proprie scelte progettuali alla luce
di tradizioni tipografiche diversissime da quelle occidentali.
- The Unicode Consortium, The Unicode Standard Version 3.0, Addison-Wesley, Reading (Massachussetts) 2000.
- G.R. Cardona, Storia universale della scrittura, A. Mondadori, Milano 1986.
- F. Coulmas, The Blackwell Encyclopedia of Writing Systems, Blackwell, Oxford 1996.
- A. Nakanishi, Writing Systems of the World, Tuttle, Tokyo 1980.
La Unicode List (accessibile dalla sezione Mail
Lists del sito Unicode) è il forum elettronico di discussione del Consorzio
Unicode. Io l’ho visitato per fare qualche domanda sulla storia di Unicode.
• Quando è iniziato il progetto Unicode?
Kenneth Whistler • In breve, a
dare inizio ai balli sono stati Joe Becker (della Xerox), Mark Davis e Lee
Collins (entrambi della Apple), a partire al 1987, in particolare con il loro
lavoro preliminare sull’unificazione dei caratteri cinesi. Comunque, il
“progetto Unicode” ha avuto molti inizi, molti momenti che si potrebbero
considerare pietre di fondazione.
• Mi pare di capire che Unicode possa considerarsi un
“sottoprodotto” della Han Unification, cioè il progetto di definire un
repertorio comune di logogrammi per il cinese, il giapponese e il coreano. È
così?
Whistler • Lo sforzo della Han Unification,
portato avanti in comune da Xerox e da Apple, fu una delle motivazioni chiave
che portarono alla realizzazione Unicode e, poi, alla fondazione del Consorzio
Unicode per definire e diffondere lo standard. Comunque, l’idea di una codifica
universale è di molto precedente. Per certi versi, lo Xerox Character Code
Standard (XCCS) era già un serio tentativo di pervenire a una codifica
universale. Bisogna poi considerare che l’inizio del progetto della ISO di un
set di caratteri universale multibyte (il 10646) precedette la fondazione
ufficiale di Unicode. Parte dell’impeto necessario alla definizione di Unicode
dipese, ovviamente, dall’insoddisfazione per l’architettura delle prime bozze
del 10646.
• Chi ha inventato il nome “Unicode” e quando?
Whistler • Almeno a questa domanda c’è una
risposta ben definita: il termine fu coniato da Joe Becker e sta per unique,
universal, and uniform character encoding. La prima attestazione
documentata del termine risale al dicembre del 1987.
• Quando è stato costituito e quando ha iniziato a operare
il WG2, il gruppo di lavoro della ISO incaricato dal sotto comitato SC2 di
definire lo standard 10646?
Whistler • Il quarto meeting del WG2 si tenne a
Londra nel febbraio del 1986. I primi tre meeting si tennero rispettivamente a
Ginevra, Torino e Londra. Quindi, la data di fondazione del WG2 da parte
dell’SC2 dovrebbe aggirarsi intorno al 1984.
• A un certo punto, Unicode e ISO 10646 hanno deciso di
unificare i rispettivi repertori di caratteri. Quando e come è successo?
Whistler • Non si può dare una data precisa, tipo
la firma di un armistizio. Per certi versi la fusione dei due standard è ancora
in corso, in quanto si sta ancora lavorando su modifiche ed emendamenti
riguardanti alcuni casi particolari dell’architettura. Comunque, le date chiave
furono:
- 3 gennaio 1991: fondazione del Consorzio Unicode, un chiaro segnale all’SC2
che gli “unicoder” stanno facendo sul serio;
- maggio 1991: 19º meeting del WG2 a San Francisco, dove si tiene una riunione
separata fra membri del WG2 e di Unicode che aprirà la pista alla successiva
“fusione” dei due standard;
- 3 giugno 1991: la data del documento 10646M proposal draft to merge Unicode
and 10646;
- agosto 1991: il meeting del WG2 a Ginevra accetta la Han Unification e altre
caratteristiche tecniche di Unicode.
• Molti sono ancora convinti che Unicode sia un “codice a 16
bit”. Quando furono definiti i cosiddetti “piani surrogati”, che portarono
Unicode a più di un milione di caratteri?
Whistler • La cosa divenne pubblica con Unicode
2.0, nel 1996. Comunque, la decisione fu presa dall’UTC (Unicode Technical
Commitee) molto prima della pubblicazione.
• A proposito di piani surrogati, dei quasi 43 000 caratteri cinesi
aggiunti nella versione 3.1 quanti sono di uso comune?
Thomas Chan • La maggior parte di questi caratteri
viene dallo standard cinese CNS 11643-1992. Nel suo articolo Taming the
Masses (su Internet all’indirizzo
www.gwdg.de/~cwitter/cw/taming.html)
Christian Wittern afferma che i caratteri dei piani estesi dello standard CNS
sono di uso raro persino nei testi antichi, e probabilmente ancor più raro in
quelli moderni.
• Sono curioso anche sulla storia della codifica prima di
Unicode. Ad esempio, quando e da chi fu pubblicato il famoso standard ASCII?
Whistler • L’ASCII apparve nel 1967. Lo standard
fu promulgato dall’ANSI X3.4. Ma, a dire il vero, l’ASCII venne prima, nel
1963. Ma l’ASCII di allora era leggermente diverso da quello che conosciamo
oggi. Nel 1972 fu pubblicato lo standard ISO 646, che era un primo tentativo di
internazionalizzare l’ASCII.
• L’ASCII, allora, apparve quando i computer erano già molto
diffusi (almeno nei laboratori, se non ancora sulle scrivanie di chiunque).
Quali standard di codifica si usavano prima dell’ASCII?
Doug Ewell • Prima dell’ASCII esistevano una grande
varietà di standard di codifica. Molti di questi erano basati sui codici usati
sulle schede perforate, oppure sul repertorio di caratteri disponibili sulle
stampanti a catena. Spesso queste codifiche davano l’impressione di non essere
state “progettate” ma piuttosto di essere state messe insieme a casaccio.
L’ASCII aveva di buono che era già, in certo qual modo, una codifica
“universale”, sia pure limitatamente agli Stati Uniti. Fra le codifiche precedenti
all’ASCII, le più popolari erano il Fieldata, il PTTC e il BCDIC (il precursore
a sei bit dell’EBCDIC).
Frank da Cruz • Vedi anche, sul manuale del
C-Kermit (su Internet all’indirizzo
www.columbia.edu/kermit), il capitolo relativo
ai set di caratteri. Le cose più interessanti riguardano alcune vecchie codifiche
russe come il DKOI e il KOI-7, e la versione originale del KOI-8, che scoprimmo
durante una visita all’Unione Sovietica del 1989.
• Dopo l’ASCII e prima di Unicode apparve l’ISO 8859, uno
standard che si usa ancora comunemente per molte lingue che usano le scritture
latina, araba, ebraica, greca e cirillica. Quando fu pubblicato?
Whistler • L’ISO 8859 è formato da molte sotto
sezioni, ognuna delle quali fu pubblicata in date diverse e supporta lingue diverse.
Tim Greenwood • Da un articolo che scrissi anni
fa, risulta che lo standard fu approvato nel 1984 dall’ECMA, e che l’ISO e
l’ANSI stavano discutendone l’adozione nel 1985.
• Quando apparvero le prime codifiche a doppio byte?
John G. Otto • Ne esistevano già alla fine degli anni
’60. Ma queste prime codifiche a doppio byte si usavano per l’inglese, non per
le lingue dell’Estremo Oriente. I calcolatori a 60 bit Control Data, progettati
da Seymour Cray, usavano byte da 6 bit e, per codificare le lettere minuscole e
altri segni speciali, usavano combinazioni di due byte.
• Ma torniamo ai nostri giorni: una delle tecnologie
tipografiche più importanti per supportare Unicode è OpenType. Oltre ai sistemi
Windows, questi font sono supportati su altre piattaforme?
John H. Jenkins • I font OpenType funzionano senza
modifiche su Mac OS, nel senso che i glifi appaiono sullo schermo. Per mezzo di
funzioni del sistema operativo, i programmi Mac possono accedere alle nuove
tabelle OpenType del font e usare i dati in esse contenute. La parte che ancora
manca è il supporto automatico del layout OpenType.
Alan Wood • La Apple offre, con il Mac OS X,
quattro font OpenType giapponesi: Hiragino Kaku Gothic Pro, Hiragino Kaku
Gothic Std, Hiragino Maru Gothic Pro e Hiragino Mincho Pro. Adobe offre il font
TektonPro con InDesign versione 1.5 per Mac OS 9.
John Hudson • “Supportare OpenType” può essere
inteso in vari modi. Le funzionalità grafiche necessarie per le varie scritture,
ad esempio quelle dell’India, sono supportato dalle applicazioni Windows per
mezzo del modulo di sistema Uniscribe, fornito da Microsoft. Credo che
anche gli sviluppatori di FreeType siano al lavoro sulle scritture dell’India,
anche se non so a che punto siano.
Eric Muller • FreeType implementa il sistema
OpenType, incluse le funzionalità di layout. Per scelta, FreeType richiede solo
che il sistema supporti il linguaggio di programmazione ANSI C, in quanto è
stato pensato per i processori embedded. La risposta potrebbe dunque
essere: è supportato su tutte le piattaforme.
© 2005 Aiap