|

|
System
calls
L'infrastruttura
delle system calls spiegato step by step.
Questo articolo spiega come aggiungere al nostro kernel l'infrastruttura per il
supporto delle system calls.

a cura di Salvatore D’Angelo – koala.gnu@tiscalinet.it
|
Introduzione
In
questo articolo, verrà mostrato come aggiungere al nostro
kernel didattico l' infrastruttura necessaria per il supporto delle
system calls. Una system call, come vedremo più avanti, non è
altro che un servizio che un processo utente richiede kernel. Oltre
alle system calls, questo articolo riprende il discorso sugli
interrupts già affrontato in parte negli articoli [1] e
[2].
Approfondiremo meglio il concetto di interrupt e come i
processori della famiglia Intel li gestiscono. Vedremo, inoltre, come
migliorare nel nostro kernel il supporto per la loro gestione, in
modo da semplificare lo sviluppo di futuri driver.
Interrupts
& Eccezioni
Interrupts
& Eccezioni: che cos'è un interrupt
Interrupts
& Eccezioni: Programmable Interrupt Controller (PIC) & IDT
Interrupts
& Eccezioni: call gates & IDT descriptors
Interrupts
& Eccezioni: controllo dei privilegi
Interrupts
& Eccezioni: stack layout
Interrupts
& Eccezioni: step 0
Interrupts
& Eccezioni: step 1
Programmable
Interrupt Timer (PIT) 8253/8254 CMOS
PIT:
step 2
Memoria
CMOS
Memoria
CMOS: step 3
System
calls
System
calls: step 4
Conclusioni
Bibliografia
Clicca
qui per scaricare il codice sorgente.
Interrupts
& Eccezioni
Interrupts
& Eccezioni: che cos'è un interrupt
I
processori della famiglia Intel fornisco due meccanismi per segnalare
la verifica di un dato evento a un programma in esecuzione:
interrupts e eccezioni.
Un interrupt è un evento asincrono
generato tipicamente da un device di I/O o dallo interval timer.
Generalmente gli interrupt si dividono in due categorie:
 | Interrupt
mascherabili, cioè gli interrupt provenienti dai PICs e
notificati alla CPU attraverso il piedino INTR. Questi interrupts
possono essere disabilitati attraverso il flag IF del registro
EFLAGS.
| Interrupt
non mascherabili (NMI), questo genere di interrupts vengono
inviati alla CPU attraverso il piedino NMI per segnalare gravi
condizioni di errore come hardware failures.
| |
Una
eccezione è un evento sincrono che viene generato quando il
processore individua una o più condizioni di programming
error, oppure su richiesta di una applicazione che gira in user mode.
Il termine sincrono sta ad indicare, in questo caso, che l' evento
viene segnalato al termine dell' esecuzione dell'istruzione che lo ha
generato. Questa categoria di eventi si divide in due categorie:
processor-detected exceptions
e programmed exceptions.
| Processor-detected
exceptions
A
questa categoria appartengono gli eventi causati da condizioni di
programming error o anomalie. Essa si suddivide in tre ulteriori
sottocategorie: fault,
trap e abort.
 | Fault,
generalmente indica una condizione di errore recuperabile. Un
esempio tipico di faults si verifica quando un processo richiede
una data pagina di memoria che, però, è stata
swappata su disco. In tale caso, il valore del registro eip (che
punta all' istruzione che ha generato il faults) viene salvato e
un apposito handler viene eseguito per rimediare alla condizione
di errore. Terminata l' esecuzione di questo handler, il kernel
può riprovare a rieseguire l' istruzione che aveva generato
il fault.
|
| Traps,
generalmente usato per informare un debugger che una data
istruzione è stata eseguita. Quando viene generato un
evento di questo tipo, viene salvata la locazione dell' istruzione
che segue quella che ha generato il trap. Dopo l' esecuzione dell'
handler il processo che era in esecucione riprenderà da
quest'ultima.
| Abort,
un evento di questo tipo indica un errore serio in qualche
struttura dati del kernel, un eventuale hardware failure e così
via. In genere l' handler di un evento di questo tipo effettua un
kill del processo che ha generato la condizione di errore.
| |
|
| Programmed
exceptions
A
questa categoria appartengono gli eventi generati su richiesta di
una applicazione che gira in user mode, attraverso una delle
istruzioni: int3, int, into o bound.
|
La
gestione degli interrupts e eccezioni è uno dei tasks più
complessi che un kernel possa gestire. Un progettista di sistemi
operativi deve tener conto dei seguenti aspetti quando si trova ad
affrontare questo tema:
| quando
si verifica un evento di interrupt (o eccezione), la CPU è
costretta a interrompere il lavoro attualmente in corso per gestire
tale evento. Poichè è obiettivo della CPU di portare
al termine il task precedentemente in corso quanto prima possibile,
è ovvio che risulta indispensabile gestire quell' evento in
un tempo relativamente piccolo. Linux per garantire questa
proprietà, spesso divide la gestione dell' evento in due
parti: top half and bottom half. La prima parte viene
eseguita immediatamente, mentre la seconda parte può anche
essere rimandata ad un successivo istante. In questo articolo non
affronteremo il tema dei bottom halves, che magari verrà
discussa in successivi articoli, insieme ad altre tecniche
utilizzate negli ultimi kernel della serie 2.4 e 2.6.
| Se un
evento di interrupt (o eccezione) può verificarsi in
qualsiasi istante è chiaro che esso possa verificarsi mentre
è in esecuzione la gestione di un altro interrupt (o
eccezione). Generalmente quando il kernel gestisce un interrupt
mascherabile, disabilita il flag IF del registro EFLAGS in modo che
la CPU ignori ulteriori interrupts di questo tipo. Viceversa, quando
il kernel si trova a gestire una eccezione, questa può essere
interrotta da un ulteriore evento di interrupt o eccezione. In
quest'ultimo caso è indispensabile che gli handler delle
eccezioni vengano scritti in modo tale che si possano eseguire
handler innestati.
| Se è
vero che il kernel in alcune circostanze deve garantire l'
esecuzione innestata di eventi di interrupts o eccezione è
chiaro che ci potrebbero essere delle regioni critiche da
sincronizzare. E' importante che il progettista di sistemi operativi
riduca al minimo il numero di queste regioni.
| | |
Interrupts
& Eccezioni: Programmable Interrupt Controller (PIC) & IDT
In [1]
abbiamo visto come i dispositivi di I/O sono collegati a un
particolare chip detto Programmable Interrupt Controller (PIC)
attraverso alcune linee di collegamento dette IRQs. Abbiamo visto
che, generalmente, su un PC vengono montati due PICs collegati in
cascata. Quando si collega un device ad un PC è necessario
associare ad esso una linea di IRQ e un range di indirizzi di I/O. Il
primo serve a segnalare al PIC eventuali richieste di I/O, mentre il
secondo serve alla CPU per leggere le informazioni provenienti dal
device. Quando un device deve notificare alla CPU un dato evento,
invia un segnale al PIC attraverso la linea IRQ ad esso assegnato.
Compito del PIC è quello di tradurre questo segnale di IRQ in
un indice nella Interrupt Descriptor Table (IDT) che conterrà
l' indirizzo della routine che gestirà l' interrupt. In [1]
abbiamo visto che questa tabella viene inizializzata in modo tale che
ogni entry (o vettore) punti a un null handler il cui compito è
quello di visualizzare un messaggio di errore. Durante la fase di
inizializzazione del kernel le entries di questa tabella vengono
aggiornate in modo tale che ogni vettore punti ad uno specifico
handler. l' associazione tra vettore di interrupt e IRQ viene
effettuata attraverso il comando ICW2 del PIC (vedi [1]). Nel file
setup.S abbiamo il seguente codice:
#
Comando ICW2. (out[0x21] = 0x20, Master).
movb $0x20, %al
#
IRQ0 -> 20h, IRQ1 -> 21h, and so on
outb %al,
$0x21
call delay
# Comando ICW2. (out[0xA1] = 0x28,
Slave).
movb $0x28, %al
outb %al, $0xa1
# IRQ8 -> 28h,
IRQ9 -> 29h, and so on
call delay
con il quale si associa IRQ0 al
vettore di interrupt 0x20, IRQ al vettore 0x21 e così via fino
a IRQ15 associato al vettore 0x2F.
Quindi se il device collegato a
IRQ1 (es. tastiera) invia un segnale di IRQ al PIC, questi provvederà
a calcolare la corrispondente entry nella IDT che, nel nostro caso è
0x21. Per segnalare questa informazione alla CPU, il PIC scrive 0x21
in una delle sue porte di I/O ed invia un segnale di interruzione
alla CPU attraverso il piedino INTR. La CPU a questo punto leggerà
il valore 0x21 e manderà al PIC un segnale di
acknowlegement.
E' importante ricordare che il PIC può
essere programmato in modo tale da abilitare/disabilitare la
ricezione di segnali da specifiche linee IRQs. Disabilitare una linea
di IRQ è diverso rispetto all' operazione di azzerare il bit
IF del registro EFLAGS. Quando disabilitiamo una linea IRQ, i segnali
di interrupts non vengono persi, bensì vengono recuperati non
appena viene riabilitata la linea. Viceversa, azzerando il bit IF del
registro EFLAGS, non si fa altro che dire alla CPU di ignorare gli
interrupts mascherabili.
La Fig. 1 illustra con un semplice
schema il processo sopra descritto, ulteriori chiarimenti è
possibile ottenerli leggendo il capitolo 4 di [5] e il capitolo 6 di
[12].
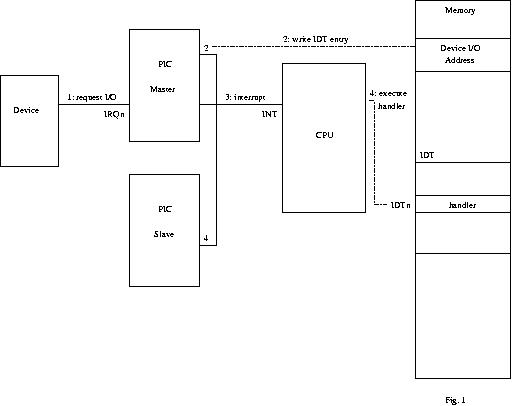
A questo
punto il lettore si porrà sicuramente le seguenti domande:
come sono fatte le entries della IDT? Cosa contengono con esattezza
tali entries?
Iniziamo con il rispondere alla seconda domanda.
Come già visto sopra, i vettori 0x20-0x2F contengono gli
indirizzi degli handler degli interrupts mascherabili. Le entries
0x00-0x19 sono riservate alle exceptions, eccetto:
| 0x02,
contenente l' handler dell' unico interrupt non mascherabile (NMI);
| 0x03,
contenente l' handler di int3;
| 0x05,
contenente l' handler di bound;
| 0x12-0x19,
che sono riservati.
| | | |
I
vettori nel range 0x30-0xFF non vengono usati ad eccezione di 0x80,
utilizzato da Linux per la gestione delle system calls (come vedremo
più dettagliatamente in seguito).
l' altra domanda a cui bisogna rispondere, è
come sono fatte le entries di una IDT.
Prima
di rispondere a questa domanda, però, è necessario
introdurre il concetto di call gate.
Interrupts
& Eccezioni: call gates & IDT descriptors
Sappiamo
che l' istruzione assembler CALL può essere utilizzata per
effettuare chiamate a procedure all' interno del segmento di memoria
corrente (near call)
o a procedure presenti in un altro segmento (far call).
Le chiamate near calls vengono generalmente usate per chiamati locali
al task corrente, mentre le far calls vengono utilizzate per invocare
routines di sistema o routines di altri tasks.
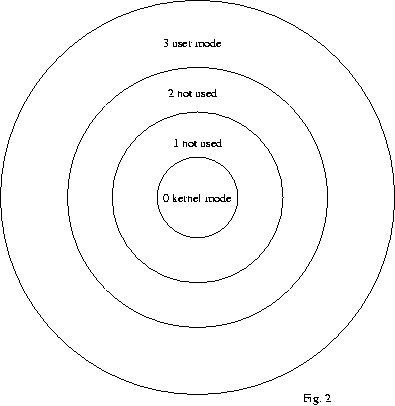
L' architettura dei processori Intel prevede 4 livelli di
protezione numerati da 0 a 3. 0 è il livello con i massimi
privilegi, al contrario 3 è il livello di protezione meno
restrittivo. La ragione principale per cui sono stati introdotti
questi livelli di protezione è quella di fornire un sistema
più affidabile in cui difficilmente un'applicazione possa
compromettere l' esecuzione dell' intero sistema.
La Fig. 2
rappresenta i quattro livelli di protezione come cerchi concentrici
in cui quello più interno (livello 0) conterrà il
codice più critico dell' intero sistema (il kernel), mentre in
quello più esterno, generalmente, girano le applicazioni
utente.
E'
chiaro che una routine presente al livello i può accedere
senza problemi ad una porzione di codice presente al livello j, con j
> i e i,j in [0 .. 3]. Viceversa, se un modulo di codice al
livello i vuole accedere ad una porzione di codice al livello j, con
j<i e i,j in [0 .. 3], lo può fare a patto di farlo
attraverso una opportuna interfaccia di protezione chiamata gate.
Se si tenta di violare questa regola la CPU genera una
general-protection exception.
Una chiamata a procedura ad un
livello di protezione più alto può essere fatta
attraverso una istruzione del tipo CALL (selettore,
offset), dove selector punta a
un descrittore chiamato call gate descriptor il
quale contiene:
|
informazioni
di protezione;
|
selettore
di segmento contenente la routine da invocare;
|
offset
nel segmento in cui è presente la routine.
| | |
Dopo questa breve introduzione sul
concetto di call gate, finalmente possiamo rispondere alla domanda
sul formato delle entries della IDT.
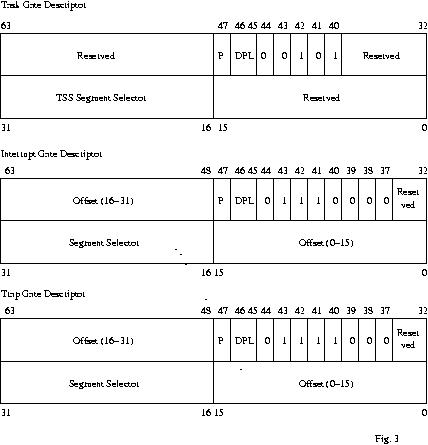
La
IDT può contenere tre tipi di call gate descriptor:
| task
gate descriptor, non usato da
Linux;
| interrupt
gate descriptor, contiene l'
indirizzo logico (selettore, offset) dell' handler utilizzato per la
gestione dell' interrupt. Prima di trasferire il controllo all'
handler, il processore azzera il bit IF del registro EFLAGS
disabilitando ulteriori interrupts mascherabili. Questo tipo di
descriptor viene utilizzato per gestire interrupt mascherabili;
| trap
gate descriptor, ha un
funzionamento analogo all' interrupt gate descriptor, con la
differenza che il bit IF del registro EFLAGS non viene azzerato,
lasciando così abilitati gli interrupts mascherabili. Questo
genere di descrittore viene usato per puntare ad handler di
eccezioni che, come già anticipato prima, possono essere
interrotti da altri interrupts (mascherabili e non).
| | |
La
Fig. 3 mostra il formato dei tre descrittori sopra citati.
Interrupts
& Eccezioni: controllo privilegi
Quando la CPU invoca l' handler di un interrupt, la
prima cosa che fa è controllare se la sorgente che ha generato
l' interruzione ha i privilegi per farlo. Per far ciò
confronta il campo CPL contenuto (nei due bit meno significativi) nel
selettore del call gate descriptor, con il campo DPL del descrittore
della IDT, se quest'ultimo ha un valore maggiore rispetto al primo
allora viene lanciato un errore di protezione generale.
Negli
steps 1, 2 e 3, vedremo come i call gate descriptors associati agli
interrupts non mascherabili (quelli provenienti dai device di I/O
tramite linee IRQs) avranno un DPL=0 e gli handler risiederanno nel
kernel segment avente CPL=0. Al contrario, per le system call il
valore DPL=3.
Interrupts
& Eccezioni: stack layout
Un altro
aspetto fondamentale da prendere in considerazione nella gestione
degli interrupts, è il layout dello stack. I processori
utilizzano uno stack per ogni livello di protezione. Quindi ogni
processo Linux utilizza due stacks, uno per quando gira in user mode
ed un altro per quando gira in kernel mode.
Quando si
verifica un interrupt il processore interrompe il processo
correntemente in esecuzione in user mode (livello di protezione 3) ed
esegue un handler in kernel mode (livello di protezione 0). Nel fare
ciò vengono eseguiti i seguenti passi:
| effettua
i controlli di protezione (privilege check);
| salva
temporaneamente i registri SS, ESP, EFLAGS, CS e EIP;
| carica
il selettore e lo stack pointer del nuovo stack (quello relativo al
nuovo livello di protezione) prendendoli dal TSS del processo
corrente e mette queste informazioni in SS e ESP; con questa
semplice operazione avviene lo switch dello stack;
| effettua
il push, nel nuovo stack, dei valori di SS e ESP precedentemente
salvati (SS, ESP, EFLAGS, CS e EIP);
| copia
i parametri dallo stack della procedura chiamante al nuovo stack;
| carica
il selettore e l' instruction pointer dal call gate nei registri CS
e EIP;
| esegue
l' handler.
| | | | | | |
La
Fig. 4 mostra il layout del kernel e user stack durante l' esecuzione
di un interrupt.
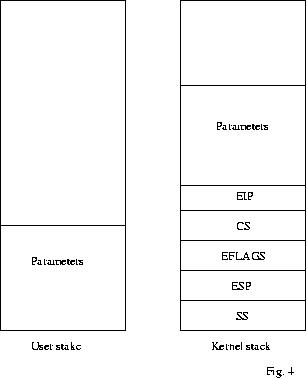
Il ritorno
da un interrupt inizia con l' esecuzione dell' istruzione IRET che, a
differenza dell' istruzione RET, recupera anche il contenuto del
registro EFLAGS. I passi eseguiti sono quindi:
| effettua
i controlli di protezione (privilege check);
|
| recupera
i valori dei registri CS e EIP;
| recupera
i valori dei registri EFLAGS;
| recupera
i valori che i registri SS e ESP avevano prima dell' interrupt;
questo comporta lo switch allo user stack;
| riprende
l' esecuzione del processo;
| | | |
A questo
punto, dopo tutta questa teoria, iniziamo a vedere in pratica alcuni
argomenti finora discussi. Nell' articolo [2] abbiamo visto come
scrivere un driver per la tastiera e, come bisogna configurare
opportunamente il PIC affinchè gli eventi di tale periferica
venissero correttamente segnalati alla CPU. Tuttavia, non abbiamo
ancora introdotto una infrastruttura adeguata, che ci consenta di
associare un IRQ ad un dato handler di periferica attraverso una
interfaccia semplice e chiara. Obiettivo dei prossimi 2 steps è
proprio quello di introdurre tale infrastruttura e consentire di
associare un IRQ ad un handler semplicemente con una chiamata a
funzione:
add_irq_handler(<num
irq>, <handler>).
In
successivi articoli, mostreremo anche come aggiungere l'
infrastruttura per la gestione delle eccezioni e come gestire quelle
predefinite dal processore.
Interrupts
& Eccezioni: step 0
In
questo step non faremo nulla di nuovo se non quello di spostare il
codice di inizializzazione del PIC dal file setup.S nel nuovo file
irq.c. Questo
file conterrà da adesso in avanti tutto il codice inerente
alla programmazione degli IRQs.
Uno dei motivi per cui ho deciso di fare ciò è
quello di diminuire quanto più possibile il codice in
assembler. Un altro motivo è che in questo modo si evita di
disperdere in più files il codice per la gestione degli IRQs.
Quindi
definiamo in irq.c
la routine init_irq()
che conterrà la traduzione in C del codice di setup del PIC
presente in setup.S.
#define
INT_CTL 0x20
#define INT_CTLMASK 0x21
#define
INT2_CTL 0xA0
#define INT2_CTLMASK 0xA1
// IRQ 2 on Master
is cascaded
static unsigned char cache_21 = 0xFB;
static
unsigned char cache_A1 = 0xFF;
void
init_irq(void) {
//
OCW1 command. Mask all the IRQ on Master
outb(0xff,
INT_CTLMASK);
// OCW1 command. Mask all the IRQ on
Slave
outb(0xff, INT2_CTLMASK);
// set up PIC
// ICW1
command.
outb_p(0x11, INT_CTL);
// ICW4 will be sent and size
of entry in interrupt vector is 4 bytes.
outb_p(0x11,
INT2_CTL);
outb_p(0x20, INT_CTLMASK);
// ICW2
command.
outb_p(0x28, INT2_CTLMASK);
// IRQ0 -> 20h,
IRQ1 -> 21h, and so on
// IRQ8 -> 28h, IRQ9 -> 29h, and
so on
// ICW3 command.
outb_p (0x04, INT_CTLMASK);
outb_p
(0x02, INT2_CTLMASK);
// The controller master is attached
to
// the slave through IRQ12 (IRQ4 on slave).
// The
controller slave is attached to
// the master through
IRQ2.
outb_p
(0x01, INT_CTLMASK);
// ICW4 command.
outb_p (0x01,
INT2_CTLMASK);
// restore masks. OCW1 command.
outb(cache_21,
INT_CTLMASK);
// Mask all interrupt for controller
Slave
outb(cache_A1, INT2_CTLMASK);
// Mask all interrupt
except IRQ2
}
Questi
comandi sono del tutto equivalenti a quelli presenti nel file
setup.S, dove abbiamo lasciato solo i comandi che mascherano tutti
gli IRQs, in modo tale che al boot si evita che la CPU riceva eventi
dal PIC, poi man mano che si procede nel codice di inizializzazione
(quello in C per intenderci) si abiliteranno gli IRQs necessari
(tastiera, timer, ecc.).
Evitiamo in questa sede di spiegare i
comandi sopra riportati, perchè già sono stati trattati
in [1].
Affinchè
questo codice di inizializzazione venga invocato prima del setup
della tastiera, è necessario invocare tale funzione in
start_kernel prima del setup della tty.
void
start_kernel(void) {
init_irq();
tty_init();
...
}
Infine,
modifichiamo il Makefile affinchè anche il file irq.c venga
compilato.
KERNEL_OBJ=head.o
main.o tty_io.o keyboard.o console.o asm.o vsprintf.o irq.o
La sola aggiunta di
irq.o alla riga di sopra comporterà la compilazione del file
irq.c e la sua inclusione nell' immagine del kernel.
Interrupts
& Eccezioni: step 1
In questo
articolo vedremo in dettaglio l' infrastruttura per la gestione degli
IRQs e vedremo anche come utilizzarla per il driver della tastiera
che al momento ha un codice di gestione IRQ ad hoc senza una
interfaccia chiara.
Iniziamo con il definire, nel file irq.c,
una tabella di 16 elementi ognuno dei quali conterrà un
puntatore all' handler della relativa linea IRQ.
volatile
void *IRQ_TABLE[16];
Introduciamo
ora la funzione da usare per associare un handler ad una data linea
IRQ.
void
add_irq_handler(unsigned int irq_nr, void *handler) {
long
flags;
save_flags(flags); cli();
if (is_valid_irq(irq_nr)) {
IRQ_TABLE[irq_nr]
= handler;
enable_irq(irq_nr);
}
restore_flags(flags);
}
Come
si evince dal codice, quello che viene fatto è di aggiungere
l' handler alla tabella sopra citata (a patto che l' irq in input sia
valido, cioè compreso tra 0 e 15) con gli interrupts
disabilitati. Dopo che l' handler è stato aggiunto alla
tabella viene abilitata la linea IRQ attraverso una nuova funzione
enable_irq che
sotto andremo ad analizzare.
E'
chiaro, quindi, che invocando add_irq_handler(irq, handler), si
abilita l' IRQ irq e ogni volta che arriverà un evento
da tale linea, la funzione handler verrà eseguita.
La
funzione enable_irq è dichiarata statica perchè è
usata solo da add_irq_handler e quindi non fa parte dell' interfaccia
verso l' esterno. In [1] abbiamo visto che il PIC comunica con la CPU
attraverso due porte: 0x20 e 0x21 per il PIC Master e 0xA0 e 0xA1 per
quello Slave. Abbiamo inoltre visto come, grazie al comando OCW1 si
possa abilitare/disabilitare le linee IRQs. In irq.c definiamo due
importanti variabili globali al file che conterranno ciascuna la
maschera degli IRQs abilitati su ciascun PIC.
static
unsigned char cache_21 = 0xFB; // IRQ 2 on Master is
cascaded
static unsigned char cache_A1 = 0xFF;
Sappiamo
che se il bit i del comando OCW1 è impostato a 1, la relativa
linea IRQ viene diabilitata. La variabile cache_21 mantiene il valore
in memoria degli IRQs abilitati sul PIC Master, mentre cache_A1 tiene
traccia delle linee IRQs abilitate sullo Slave. Nel file setup.S
abbiamo disabilitato tutte le linee tranne IRQ2 sul PIC Master,
infatti i valori con cui inizializzeremo queste variabili tendono a
rappresentare proprio questo stato.
A
questo punto vediamo come queste due variabili vengono usati all'
interno della funzione enable_irq.
static
void enable_irq(unsigned int irq_nr) {
unsigned
char mask;
mask = ~(1 << (irq_nr & 7));
if
(irq_nr < 8) {
cache_21
&= mask;
outb(cache_21,0x21);
}
else {
cache_A1
&= mask;
outb(cache_A1,0xA1);
}
}
Per
prima cosa la funzione calcola la maschera che consente l'
abilitazione della linea IRQ irq_nr.
Se irq_nr == i, allora l' i-esimo bit della maschera è 0 (0
indica l' abilitazione della linea IRQ). Se irq_nr è compreso
tra 0 e 7 si modifica lo stato del PIC Master, altrimenti quello
dello Slave. Si aggiorna il valore cache_XX ponendolo in and con la
maschera precedentemente calcolata e si invia un comando OCW1 al PIC.
A questo punto, bisogna analizzare il
codice che consente l' esecuzione dell' handler corretto quando
proviene un evento da una data linea IRQ.
Iniziamo con l'
introdurre un nuovo file traps.c
in cui definiamo una nuova routine init_traps
a
cui delegheremo il compito di associare a ciascuna entry della IDT un
ben preciso handler.
Alle prime
32 entries (0-31) verrà associato il null handler, mentre alle
successive 16 entries si associeranno le routine che gestiranno gli
eventi provenienti dalle linee IRQs. Le restanti entries possono
essere utilizzate dal kernel come software interrupt. Nello step 4,
vedremo che il kernel utilizzerà solo l' interrupt 0x80 per la
gestione delle system call.
void
init_traps(void) {
int
i;
// exception: 0x0 - 0x10. Not implemented yet
for
(i=0x0; i<0x20; i++)
set_intr_gate(i,
&_unhand_int);
set_intr_gate(0x20,
&_hwint0);
set_intr_gate(0x21, &_hwint1);
set_intr_gate(0x22,
&_hwint2);
set_intr_gate(0x23, &_hwint3);
set_intr_gate(0x24,
&_hwint4);
set_intr_gate(0x25, &_hwint5);
set_intr_gate(0x26,
&_hwint6);
set_intr_gate(0x27, &_hwint7);
set_intr_gate(0x28,
&_hwint8);
set_intr_gate(0x29, &_hwint9);
set_intr_gate(0x2A,
&_hwint10);
set_intr_gate(0x2B,
&_hwint11);
set_intr_gate(0x2C,
&_hwint12);
set_intr_gate(0x2D,
&_hwint13);
set_intr_gate(0x2E,
&_hwint14);
set_intr_gate(0x2F, &_hwint15);
//
system call: 0x80. Not implemented yet
for (i=0x30;
i<IDT_ELEMENTS; i++) {
set_intr_gate(i,
&_unhand_int);
}
}
Il
null handler _unhand_int
non fa altro che stampare un messaggio di errore e ciclare in modo da
bloccare il sistema (più avanti magari vedremo approcci di
gestione più adeguati). Le routine _hwint0/_hwint15,
verranno usati per gestire gli eventi provenienti dagli IRQs e li
analizzeremo meglio più avanti in questo paragrafo.
Com'è facile
osservare dal codice sopra riportato, abbiamo usato la macro
set_intr_gate (introdotta per la prima volta nello step 0 di [2]) per
definire in ciascuna entry della IDT un interrupt call gate.
Le routines _hwint1/_hwint7, utilizzate per gestire
gli eventi segnalati dal PIC master, sono definite nel file asm.S,
attraverso la seguente macro:
mentre le
routines _hwint8/_hwint15, utilizzate per gestire gli eventi
segnalati dal PIC slave, sono definite con quest'altra macro:
#define
HWINT_SLAVE(irq) \
ENTRY(_hwint##irq) \
SAVE_ALL; \
inb
$INT2_CTLMASK, %al; \
orb $1<<(irq-8), %al; \
outb
%al, $INT2_CTLMASK; \
movb $ENABLE, %al; \
outb %al,
$INT_CTL; \
jmp .+2; \
outb %al,
$INT2_CTL; \
STI; \
call
*(IRQ_TABLE+4*irq); \
CLI; \
inb $INT2_CTLMASK, %al; \
andb
$~(1<<(irq-8)), %al; \
outb
%al, $INT2_CTLMASK; \
RET
Le due
macro sono praticamente simili eccetto qualche lieve differenza
dovuto al fatto che indichiamo gli IRQs sullo slave con i numeri 8/15
anzichè 0/7, quindi analizzeremo in dettaglio solo la prima.
Per chi ha poca conoscenza di assembler,
traduco la macro in un pseudo codice C.
|
salva
tutti i registri sul kernel stack compreso l' indirizzo della
routine ret_from_intr |
|
mask1
= maschera con il bit irq a 1 |
|
outb[inb[0x21]
| mask1, 0x21] |
|
outb[0x20,
0x20] |
|
abilita
interrupt mascherabili |
|
esegui
l' handler irq_table[irq] |
|
disabilita
interrupt mascherabili |
|
mask2
= maschera con il bit irq a 0 |
|
outb[inb[0x21]
& mask2, 0x21] |
|
jump
alla routine ret_from_intr |
Per
prima cosa vengono salvati i registri nel kernel stack (oltre a
quelli già salvati in automatico dal processore come spiegato
sopra) attraverso la macro SAVE_ALL. Al top dello stack ci sarà
l' indirizzo della routine ret_from_intr che gestirà, come già
visto in [2] il ritorno dall' interrupt. l' istruzione outb[inb[0x21]
| mask1, 0x21], non è altro che un comando OCW1 inviato al PIC
per indicare che successivi eventi devono attendere in coda per
essere elaborati (vedi [1]).
Il
comando outb[0x20, 0x20] segnala al PIC la fine dell' interrupt e,
con il successivo comando STI, si fa in modo che la CPU non ignori
successivi interrupt mascherabili.
A questo
punto, viene eseguito l' handler dell' interrupt puntato da
IRQ_TABLE[irq], terminato il quale viene riabilitata la linea IRQ in
questione con il comando outb[inb[0x21] & mask2, 0x21] e si salta
alla routine ret_from_intr.
La
routine ret_from_intr non fa altro che ripristinare i valori dei
registri dal kernel stack e chiamare l' istruzione IRET.
ret_from_intr:
cli
popw
%gs
popw %fs
popw %es
popw %ds
popa
iret
A questo
punto, è pronta la nostra infrastruttura per la gestione degli
IRQs e possiamo iniziare a provarla proprio con il nostro keyboard
driver. Sostituiamo, quindi, in keyboard_init (nel file keyboard.c)
le righe:
set_intr_gate(0x21,
&kb_intr);
outb_p(inb_p(0x21) & 0xfd, 0x21);
con la
seguente nuova riga.
add_irq_handler
(1, &keyboard_interrupt);
D'ora in
avanti basterà utilizzare questa funzione per associare un
handler ad una specifica linea IRQ.
Programmable
Interrupt Timer (PIT) 8253/8254 CMOS
Molte
attività di un sistema operativo sono strettamente legate al
tempo. Basta pensare ad esempio a screen saver che si attivano dopo
un periodo di inutilizzo dei dispositivi d'input da parte dell'
utente. Generalmente, le attività legate al tempo che un
sistema operativo si trova a svolgere, sono raggruppabili in due
categorie:
| tener
traccia dell' ora corrente in modo da restituirla a processi utente
su richiesta o per marcare timestamp di specifiche risorse;
| segnalare
al kernel o a un'applicazione utente che un certo periodo di tempo è
ormai trascorso.
| |
Affinchè
un kernel possa gestire queste due categorie di tasks, è
necessario che l' hardware su cui esso si poggia supporti tali
funzionalità. Su architetture Intel un kernel può
interagire con tre tipi di dispositivi: Real Time Clock, Time Stamp
Counter, e il PIT. I primi due vengono usati per tener traccia del'
ora corrente, mentre l' ultimo serve per inviare segnali al kernel o
ad applicazioni utente allo scadere di un certo intervallo di tempo.
Su architetture Intel, generalmente il PIT viene implementato
attraverso il CMOS chip 8253 su PC & XT e 8254 su AT+.
Il
CMOS PIT 8253/8254 ha 3 canali interni detti: timer 0, timer 1 e
timer 2. Il primo viene usato come Timer Clock, il secondo per il
refresh della RAM e il terzo per emettere suoni attraverso lo
speaker. Tutti e tre i canali hanno un oscillatore associato che
lavora ad una frequenza base di 1,193182 Mhz. E' possibile
programmare ciascun canale, rispettivamente, attraverso le porte di
I/O: 0x40, 0x41 e 0x42. In questo paragrafo utilizzeremo solo la
prima per fare in modo che dal canale 0 fuoriesca un segnale di
interrupt sulla linea IRQ 0 ad una frequenza di 100 Hz. Il PIT
utilizza, infine, un ultimo registro (Mode Control Register)
associato alla porta 0x43 il cui formato è il seguente:
| bit
6-7 : timer channel
| bit
4-5 : LSB (11) o MSB
| bit
3-1 : counter mode (011=square wave rate generator)
| bit 0 :
count format (0 = binary);
| | | |
Ad
esempio, volendo che il PIT fornisca attraverso il channel 0 (porta
0x40) un segnale di interrupt con frequenza di 100 Hz, bisogna
scrivere un pezzo di codice come il seguente:
#define
HZ 100
#define TIMER_FREQ 1193182
#define TIMER_COUNT
(TIMER_FREQ /HZ)
outb_p(0x36, 0x43);
outb_p(TIMER_COUNT,
0x40);
outb_p(TIMER_COUNT>>8, 0x40);
si osservi
come i bits 6-7 del mode control register sono stati impostati a 0
per selezionare il canale 0. I bits 4-5 indicano la modalità
di lettura/scrittura. Poichè alle porte 0x40, 0x41 e 0x42 è
possibile inviare singoli byte, nel momento in cui è
necessario inviare delle word bisogna specificare in che ordine
questi byte verranno inviati. Specificando 1 per entrambi i bits non
facciamo altro che informare il PIT che invieremo prima il byte meno
significativo e poi quello più significativo. Attraverso i
bits 1-3 si informa il PIT il tipo di timing che si desidera. Con i
due bytes da noi inviati sulla porta 0x40 diciamo al PIT di generare
un segnale ad onda quandra ad una frequenza di 100 Hz (ossia ogni 10
ms). Questo segnale arriverà al PIC attraverso la linea IRQ 0.
La scelta della
frequenza del segnale di output non è casuale, perchè
esa influenza enormemente i tempi di risposta del sistema.
Generalmente, frequenze alte consentono migliori tempi di risposta, a
patto che il processore sia sufficientemente potente da consentirlo.
Infatti su processori Alpha Linux usa una frequenza di 1024 Hz. I
tempi di risposta di un sistema spesso dipendono da quanto
velocemente un processo viene prelazionato da uno ad alta priorità.
Aumentando la frequenza delle interruzioni del timer interrupt
aumenta il numero di volte in cui si richiama lo scheduling e quindi
la probabilità che un processo venga prelazionato. Tuttavia,
tempi frequenze troppo alte implicano anche un maggiore tempo di
esecuzione in kernel mode con conseguente rallentamento delle
applicazioni user space. Quindi aumentare questo parametro ha senso
solo su processori sufficientemente potenti.
PIT:
step 2
In
questo step programmeremo il chip CMOS PIT 8253/8254 affinchè
ad una frequenza di 100 Hz invii al PIC un segnale di interrupt sulla
linea IRQ0. Introduciamo, innanzittutto, un primo file chiamato
sched.h,
che conterrà la define HZ della frequenza del segnale in
uscita dal canale 0 del PIT.
#define
HZ 100
Questo
file, conterrà in futuro importanti strutture dati per la
gestione dei processi. E' necessario definire un altro nuovo file,
chiamato time.c,
è necessario definire affinchè contenga tutto il codice
relativo alla gestione del timer.
Definiamo in esso la
funzione di inizializzazione del timer che, oltre ad avere il codice
già analizzato sopra, associa anche l' handler timer_interrupt
all' IRQ 0.
#define
TIMER_FREQ 1193182L
#define TIMER_COUNT ((unsigned)
(TIMER_FREQ/HZ))
#define TIMER_MODE 0x43
#define TIMER_0
0x40
#define SQUARE_WAVE 0x36
static void
setup_timer(void) {
outb_p
(SQUARE_WAVE, TIMER_MODE);
outb_p ((unsigned char)TIMER_COUNT,
TIMER_0);
outb_p ((unsigned char)(TIMER_COUNT>>8),
TIMER_0);
add_irq_handler (0, &timer_interrupt);
}
void
time_init(void) {
setup_timer();
}
l' handler
timer_interrupt, in questo step, non fa altro che incrementare una
variabile jiffies e stampare un punto a video, in successivi articoli
vedremo come questo handler sarà fondamentale per implementare
un efficiente scheduler.
unsigned
long volatile jiffies = 0;
static void timer_interrupt(void) {
++jiffies;
printk(".");
}
In base a
quanto visto nello step precedente, un segnale sulla linea IRQ 0
attiverà la routine _hwint0 in asm.S che avrà un codice
diverso rispetto alle restanti linee IRQs:
ENTRY(_hwint0)
SAVE_ALL
call
*(IRQ_TABLE)
movb $ENABLE, %al
outb $al, INT_CTL
RET
in quanto
non disabilita/abilita la linea IRQ ed esegue il comando EOI dopo l'
esecuzione dell' handler.
Infine,
è importante richiamare nella funzione main di main.c la
routine time_init.
void
start_kernel(void) {
init_traps();
init_irq();
tty_init();
time_init();
sti();
while(1);
}
Memoria
CMOS
Visto che
nello step precedente abbiamo programmato il PIT affinchè
generasse un intervallo con una frequenza di 100 Hz, in questo step
utilizzeremo la memoria CMOS per far stampare, in fase di boot, la
data e ora corrente.
La
memoria CMOS è una memoria tampone che contiene alcune
importanti informazioni sulla configurazione della macchina. Queste
informazioni vengono mantenute anche se il PC è spento per un
lungo periodo, essendo la memoria alimentata da una batteria che si
trova sulla scheda madre.
l' accesso alla memoria CMOS avviene
tramite due porte di I/O. La porta 0x70 utilizzata per indirizzare il
byte interessato, e la porta 0x71 per leggere o modificare il
relativo byte. Non vi è nessun controllo sul byte indirizzato
nella memoria CMOS, infatti la porta 0x70 è una porta a sola
scrittura, quindi prima di leggere o modificare qualsiasi byte
contenuto nella memoria è importante disabilitare gli
interrupt attraverso l' istruzione CLI e riabilitarli successivamente
attraverso l' istruzione STI. Questa coppia di istruzioni, purtroppo,
non ha nessun effetto sugli interrupt NMI.
La
memoria CMOS ha una dimensione standard di 64 bytes, ma col passare
del tempo i produttori di schede madri ne hanno aumentato la capacità
a 128 bytes.
Di seguito è possibile osservare una
tabella riassuntiva del contenuto della CMOS.
|
Indirizzo
|
Lunghezza
|
Contenuto
|
|
0x00
|
0x0E
|
Real
Time clock information
|
|
0x0E
|
0x01
|
Diagnostic
state bye
|
|
0x0F
|
0x01
|
Shutdown
state bye
|
|
0x10
|
0x01
|
Tipo
di floppy disk drive
|
|
0x11
|
0x01
|
Riservato
|
|
0x12
|
0x01
|
Tipo
di Hard Disk drive
|
|
0x13
|
0x01
|
Riservato
|
|
0x14
|
0x01
|
Equipment
set byte
|
|
0x15
|
0x02
|
Dimensione
memoria base
|
|
0x17
|
0x02
|
Dimensione
memoria estesa (superiore a 1Mb)
|
|
0x19
|
0x01
|
Tipo
di Hard Disk drive C
|
|
0x1A
|
0x01
|
Tipo
di Hard Disk drive D
|
|
0x1B
|
0x06
|
Riservato
|
|
0x21
|
0x0D
|
Riservato
|
|
0x2E
|
0x02
|
CMOS
checksum
|
|
0x30
|
0x02
|
Dimensione
memoria estesa superiore a 1Mb
|
|
0x32
|
0x01
|
Secolo
corrente
|
|
0x33
|
0x01
|
Informazioni
addizionali
|
|
0x34
|
0x0C
|
Riservato
|
|
0x40
|
0x40
|
Estensioni
della memoria CMOS da parte dei produttori di schede madri
|
Memoria
CMOS: step 3
Dopo
questa breve panoramica sulla memoria CMOS estratta da [8], vediamo
come sfruttare queste informazioni per stampare, in fase di boot, l'
ora e data corrente. Definiamo, innanzittutto, un nuovo file mktime.h
che conterrà la definizione di una importante struttura dati
di questo step:
struct
mktime {
int
sec;
int min;
int hour;
int day;
int mon;
int year;
};
Questa
struttura conterrà data e ora fino alla risoluzione del
secondo. Creiamo un altro file, chiamato mc146818rtc.h,
che conterrà alcune importanti macro. La prima che andiamo ad
esaminare è la macro che consente la lettura di un byte dalla
CMOS.
#define
CMOS_READ(addr) ({ \
outb_p(addr|0x80,0x70);
\
inb_p(0x71); \
})
Si osservi
come prima si specifica l' indirizzo da leggere scrivendolo sulla
porta 0x70 e poi la si legge effettivamente dalla porta 0x71.
Nella
routine time_init(), prima del setup dell' handler, leggiamo l'
orario dalla CMOS e memorizziamolo in una variabile di tipo struct
mktime.
void
time_init(void) {
struct
mktime time;
do {
time.sec
= CMOS_READ(RTC_SECONDS);
time.min =
CMOS_READ(RTC_MINUTES);
time.hour = CMOS_READ(RTC_HOURS);
time.day
= CMOS_READ(RTC_DAY_OF_MONTH);
time.mon =
CMOS_READ(RTC_MONTH);
time.year = CMOS_READ(RTC_YEAR);
}
while (time.sec != CMOS_READ(RTC_SECONDS));
....
}
Gli
indirizzi della CMOS dove è memorizzata la data e ora corrente
sono i primi 0x0E bytes (vedi tabella sopra) e le macro di questi
offset (RTC_SECONDS, RTC_MINUTES, ecc.), sono definiti nel file
mc146818rt.h nel modo seguente.
#define
RTC_SECONDS 0
#define RTC_MINUTES 2
#define RTC_HOURS
4
#define RTC_DAY_OF_MONTH 7
#define RTC_MONTH
8
#define RTC_YEAR 9
Poichè
questi dati sono espressi in BCD, si effettua una opportuna
conversione prima di stampare i dati a video.
if
(!(CMOS_READ(RTC_CONTROL) & RTC_DM_BINARY) ||
RTC_ALWAYS_BCD{
BCD_TO_BIN(time.sec);
BCD_TO_BIN(time.min);
BCD_TO_BIN(time.hour);
BCD_TO_BIN(time.day);
BCD_TO_BIN(time.mon);
BCD_TO_BIN(time.year);
}
Con la
macro BCD_TO_BIN definita nel file mc146818rt.h. A questo punto
siamo pronti a stampare l' orario a video.
printk("Date
(mm/dd/yy): %02d/%02d/%02d\n", time.mon, time.day,
time.year);
printk("Time (hh:mm:ss): %02d:%02d:%02d\n",
time.hour,
time.min, time.sec);
System
calls
Lo
standard Posix definisce uno strato software che consente a qualsiasi
processo in user mode di richiedere servizi al kernel. Questo strato
consente di accedere a risorse hardware come stampanti, dischi ecc.,
senza dover conoscere i dettagli di funzionamento di tali risorse.
Questo offre un notevole vantaggio da un punto di vista della
portabilità dei programmi. Un altro vantaggio è
sicuramente la security, perchè ovviamente i processi girando
in user mode avranno potere limitato e le richieste fatte al kernel
possono essere opportunamente controllate prima di essere eseguite.
Una system call non è altro che una
richiesta fatta da un processo al kernel via software interrupt.
Queste system calls vengono invocate attraverso delle wrapper
routines definite nella libreria
standard libc. Ad
esempio la chiamata di sistema fork per il forking di processi è
una wrapper routine che richiede l' esecuzione del servizio di
forking al kernel attraverso un opportuno interrupt software (0x80 su
Linux) e settando opportunamente alcuni registri.
#define
_syscall0(type,name) \
extern
inline type name(void) \
{ \
type
__res; \
__asm__ volatile ("int $0x80" \
: "=a"
(__res) \
: "0" (__NR_##name)); \
if (__res >= 0)
\
return
__res; \
errno
= -__res; \
return -1; \
}
_syscall0(int,
fork);
Si osservi
come venga invocato l' interrupt software 0x80 settando il registro
EAX con l' identificativo che il kernel ha assegnato alla system call
fork.
Ovviamente in fase di compilazione i programmi dovranno
linkarsi alla libc per poter utilizzare questi servizi dei kernels,
cosa che viene fatta automaticamente dai compilatori.
La Fig. 5 mostra cosa accade in Linux (e quindi al
nostro kernel) quando un processo invoca una wrapper routines come la
fork.
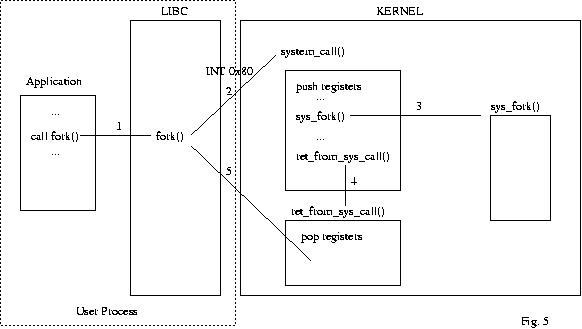
La
wrapper routine, imposta opportunamente alcuni parametri come l' id
che il kernel ha associato a quella determinata system call e invoca
un software interrupt (0x80 nel nostro caso). Questo provoca lo
switch della CPU i kernel mode con la conseguente esecuzione di una
routine uguale per qualsiasi system call invocata.
Questa kernel routine salva il contenuto
attuale dei registri sul kernel stack, che verranno ripristinati
prima che il processo ritornerà in user mode. Tra i registri
salvati non compaiono eflags, cs, eip, ss, e esp, che vengono
salvati automaticamente dalla CPU quando viene invocato il software
interrupt. A questo punto, viene eseguita la routine sys_xxx
che esegue la system call xxx
lato kernel. Terminata l' esecuzione di questa funzione, si esegue il
pezzo di codice che serve al kernel per riprendere l' esecuzione del
processo dal punto in cui aveva lasciato. Questa pezzo di codice che,
in genere, viene denominata in Linux con il nome ret_from_sys_call
(ret_from_intr nel nostro caso), ripristina i registri
precedentemente salvati e chiama l' istruzione IRET.
Ad ogni
system call il kernel associa un id che la identifica. Affinchè
esso possa associare a ciascuna system call xxx
con id k la rispettiva
kernel routine di servizio sys_xxx,
viene usata una system call dispatcher table;
questa tabella, avrà nella k-esima entry il riferimento alla
routine sys_xxx.
Un aspetto molto importante e delicato nella
gestione delle system call e il passaggio dei parametri. Abbiamo
visto che i programmi accedono alle system calls attraverso delle
wrapper routine, le quali settano i valori passati da essi in
appositi registri. l' uso dei registri per il passaggio dei parametri
pone alcuni limiti:
| visto il numero
esiguo di registri disponibili su architetture Intel non più
di 6 parametri è possibile passare alle system calls, in
particolare, si utilizza il registro eax per contenere l' id della
system call e ebx, ecx, edx, esi e edi per gli altri parametri.
Questi registri, come già visto sopra, verranno salvati sul
kernel stack subito dopo l' indirizzo di ritorno. Se si rende
necessario passare più di 6 parametri, si può sempre
usare un buffer, contenente uno o più parametri, puntato da
uno dei registri.
|
| La lunghezza di
ciascun parametro non deve essere superiore alla size dei registri
(32 bits per processori Intel). Questo, tuttavia, non è un
problema visto che lo standard Posix stabilisce che per parametri
con size maggiore di 32 bits si deve passare l' indirizzo.
|
I valori dei parametri
memorizzati sullo stack, verranno facilmente prelevati dalla kernel
routine che esegue la richiesta di servizio attraverso una semplice
dichiarazione come questa:
int
sys_xxx(type1 param1, type2 param2, ...) {
...
}
delegando
così al compilatore il ripristino dei parametri dal kernel
stack. Per ragioni di sicurezza la prima cosa che dovrebbe fare
questa routine è quella di controllare la validità dei
parametri per evitare che una irregolare richiesta blocchi l' intero
sistema.
Come già
anticipato precedentemente, ad ogni system call è associata
una wrapper routine definita attraverso una delle macro _syscallx,
con x che può assumere un valore da 0 a 5. Questo valore
indica il numero di parametri che accetta la routine. I primi due
parametri di questa macro sono il tipo di ritorno della system call e
il suo nome. Successive coppie di parametri indicano il tipo e nome
del parametro della system call.
All' inizio di questo
paragrafo abbiamo visto la dichiarazione della macro _syscall0 che,
espansa con i parametri (int, fork) da vita alla wrapper routine
della system call fork.
extern
inline int fork(void) \
{
\
type
__res; \
__asm__ volatile ("int $0x80" \
: "=a"
(__res) \
: "0" (__NR_fork)); \
if (__res >= 0) \
return
__res; \
errno
= -__res; \
return -1; \
}
__NR_fork
denota l' entry della system call dispatcher table che punta alla
routine di servizio sys_fork.
System
calls: step4
In
questo step implementeremo l' infrastruttura necessaria per la
gestione delle system calls. Per scopi di test definiremo una system
call di debug, che chiameremo print,
per la stampa di messaggi a video.
int
print(char *msg);
Iniziamo
con il creare due nuovi files sys.h
e sys.c. Nel
primo file definiremo la size max della system call dispatcher table
#define
NR_SYSCALLS 1
mentre
nel secondo definiremo la tabella vera e propria.
extern
asmlinkage int sys_print(char *msg);
void *sys_call_table[] = {
sys_print };
Com'è
facile osservare, sys_print
sarà la kernel routine che gestirà il servizio offerto
dalla system call print. l' implementazione di questa routine di
servizio si trova nel file console.c ed esegue una semplice printk.
In questo step la system call print verrà invocata dal
processo idle in kernel mode, quindi è sufficiente la printk
per implementarla.
int
sys_print(char *msg) {
printk(msg);
return
0;
}
A questo
punto si crea il file unistd.h che conterrà la definizione
delle macro per le wrapper routines.
#define
__NR_print 0
#define _syscall1(type,name,atype,a) \
type
name(atype a) \
{ \
type
__res; \
__asm__ volatile ("int $0x80" \
:
"=a" (__res) \
: "0" (__NR_##name),"b"
(a)); \
if
(__res >= 0) \
return
__res; \
errno
= -__res; \
return -1; \
}
extern
int errno;
int print(char *msg);
Si
osservi come alla system call sia stato associato l' id __NR_print =
0. A questo punto, quando un processo user mode invoca la wrapper
routine print, imposterà il registro eax con l' id 0, il
registro ebx con l' indirizzo del messaggio e invocherà il
software interrupt 0x80.
A
questo interrupt si associerà un trap gate nel file traps.c
attraverso la seguente riga di codice.
set_system_gate(0x80,
&system_call);
Questa
routine imposterà l' entry 0x80 della IDT nel modo seguente:
|
selettore
= kernel code segment;
|
offset
= indirizzo della routine system_call;
|
type
= 15 per indicare che si tratta di una trap, cioè non
disabilita gli interrupts mascherabili;
|
DPL=3
questo permette ai processi user mode di invocare l' exception
handler.
| | | |
Il
codice dell' handler system_call, definito nel file asm.S, è
il seguente.
.extern
sys_call_table
ENTRY(system_call)
SAVE_ALL
STI
cmpl
$NR_SYSCALLS-1, %eax
ja 1f
pushl %edx
pushl
%ecx
pushl %ebx
call *sys_call_table(,%eax,4)
addl
$3*4, %esp
1:
RET
Innanzittutto
vengono salvati tutti i registri attraverso la consueta macro
SAVE_ALL. Poi si controlla se l' id della system call in eax è
valido, si salvano i restanti registri non salvati con la precedente
macro e si invoca la routine di servizio attraverso la system call
dispatcher table. Terminata quest'ultima si esegue la RET che preleva
l' indirizzo al top dello stack e fa un salto ad esso. Come per magia
al top dello stack è presente l' indirizzo della routine
ret_from_intr dichiarata sempre nello stesso file.
ret_from_intr:
CLI
popw
%gs
popw %fs
popw %es
popw %ds
popa
IRET
Questa
routine non fa altro che ripristinare tutti i registri e invocare l'
istruzione IRET.
Infine testiamo tutto il nostro lavoro invocando la system
call mediante il processo idle nella routine start_kernel del file
main.c.
void
start_kernel(void) {
....
#ifdef
DEBUG
print("System call: ok!\n");
#endif
while(1);
}
Affinchè
questa system call funzioni anche da processi in user mode, è
necessario copiare il messaggio da user space a kernel space, cosa
che vedremo nel successivo articolo.
Conclusioni
Con questo
articolo penso che abbiamo aggiunto al nostro kernel un altro
importante tassello: la gestione degli interrupt & system calls.
Nel prossimo articolo inizieremo ad introdurre le strutture dati
principali per la gestione dei processi, compresa la realizzazione di
uno scheduler e una gestione della memoria fisica minimale.
Bibliografia
[1]
Linux Boot Process
[2] Keyboard & Console Programming
[3]
Codice sorgente del kernel
Pablox
http://www.xoom.virgilio.it/javaman
[4]
Codice sorgente del kernel
Scaraos
http://www.scaramanga.co.uk/scaraOS
[5]
Understanding Linux Kernel
Bovet & Cesati
O' Reilly
[6]
Linux Internals
Second Edition
Michael Beck & Harold
Boheme
Addison Wesley
[7] INTEL CORPORATION - “80386
Programmer's Manual”
[8] http://www.programmazione.it
– Articolo sul sistema operativo Prometeus di Antonio Mazzeo
[9]
Linux source code 0.96a
http://www.kernel.org
[10]
Linux source code 1.0
http://www.kernel.org
[11]
Progettazione e sviluppo dei sistemi operativi
Edizione
Italiana
Andrew S Tanembaum
Paolo Ciancarino
Gruppo
Editoriale Jackson
[12] IA-32 Intel Architecture
Software
Developer's Manual
Volume 1: Basic
Architecture
http://www.intel.com
[13]
IA-32 Intel Architecture
Software Developer's Manual
Volume 3:
System Programming Guide
http://www.intel.com
| 


