A Multiprocessor System for Displaying Quadric CSG Models
Reinier van Kleij1 and Frido Kuijper2
1. Delft University of Technology, The Netherlands. Email:
rein@duticg.tudelft.nl
2. TNO Physics and Electronics Laboratory, The Netherlands. Email:
frig5@fel.tno.nl
Abstract. Constructive Solid Geometry (CSG) is a method for defining
solid objects as a combination of simple primitives. We present a
multiprocessor system for interactive display of CSG models. Several techniques
are compared to find an optimum system. Using exact models instead of
polygon-approximated models improved the scalability.
Constructive Solid Geometry (CSG) is a powerful technique for modelling complex
mechanical parts. With CSG, simple parametrised objects, called primitives, are
positioned in space and dimensioned using geometric transformations. By
applying volumetric set operations (union, intersection, difference) the
primitives are combined into composite objects to which the set operations can
also be applied. The set operations are stored in the nodes of the so-called
CSG tree; the primitives are stored in the leafs. The root node represents the
composite object.
The CSG scanline algorithm [1] gives reasonable display times on
general-purpose workstations, but is too slow for interactive display. We have
developed an extendible multiprocessor display system based on the T800
transputer. The system achieves interactive display times for CSG models. We
have experimented with methods to distribute the work among the processors.
Using an exact representation of the quadrics instead of a polygon-approximated
one benefits the scalability.
This paper is structured as follows. Section 2 gives a description of the CSG
scanline algorithm for quadrics, which served as our starting point. Section 3
describes the techniques we have investigated. Section 4 discusses the
implementation and the results. Section 5 gives some conclusions.
Atherton [1] has developed an elegant algorithm for displaying polyhedral CSG
models, which is based on the standard scanline visible-surface algorithm for
polyhedral objects. The scanline algorithm consists of two parts: the
preprocessing part and the scan conversion part. In the preprocessing part, the
primitives in the CSG model are transformed to image space and the edges are
sorted into edge-buckets. An edge-bucket is a linked list of edges that occur
for the first time at the scanline the bucket belongs to. The preprocessing
needs to be done for all primitives before the scan conversion part can
start.
The scan conversion part draws the image in scanline order. Two important data
structures are used during scan conversion. The Active Edge List (AEL): the
list of all edges intersecting the current scanline, sorted from left to right.
Two adjacent edges determine a span. The Active Face List (AFL): the list of
all faces that might be visible on the current span. The AEL is updated when
the next scanline is to be drawn. A scanline is drawn from left to right, span
after span.
The visible face on a span is determined by sorting the faces in the AFL and
classifying each face using the CSG tree. The first face, which is classified
as on the composite object is the visible face. When there are intersections,
the span is subdivided on the intersection and the above procedure is repeated
for the two subspans. Bronsvoort [3] gives a number of efficiency improvements.
The CSG scanline algorithm is efficient by exploiting coherence between
scanlines, between spans and on the spans. In order to display CSG models with
quadrics, both the preprocessing part and the scan conversion part of the
algorithm need to be adjusted [5]. The use of quadrics results in a small
geometric database and reduces the amount of data, that has to be communicated
in a multiprocessor environment.
Our goal was to develop a multiprocessor system that displays CSG models within
a few seconds. To parallelize the CSG scanline algorithm we used the data
decomposition approach. This approach works well, because the data can be
divided in chunks with equal workloads. We use a static data scheduling
approach, which implies that after a primitive is preprocessed, the results
need to be broadcast to all other processors.
For preprocessing we use the processor farm model with a demand-driven task
scheduling strategy [6]. Each processor requests the primitives for
preprocessing from the host. Since the preprocessing accounts for a small part
of the display times, we did not put much effort in optimizing it.
Parallel scan conversion is achieved by computing different parts of the image
in parallel. As the scanline algorithm exploits coherence in the scan
conversion part, we tried to preserve it. The screen is subdivided into strips
(see Figure 1a). We first look at strips of one scanline. To equally distribute
the work among the processors, we have experimented with normal and data
pipeline interleaving.
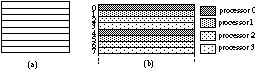
Fig.1. Strip subdivision of the screen (a) and normal interleaving (b)
Each processor processes the same number of scanlines e.g. processor 0
processes scanlines 0, N, 2N, ..., processor 1 processes scanlines 1, N+1,
2N+1, etc., with N is the number of processors (see Figure 1b). This scheme has
a drawback: a large number of processors gives a large distance between the
scanlines of one processor and the coherence between scanlines is lost.
Blonk et al [2] proposed an interleaving method, in which no coherence between
scanlines is lost, by using the data pipeline concept. The computations for a
scanline are divided into two tasks: the update task, in which the AEL is
updated and the draw task, in which the scanline is drawn. Each update task is
executed with coherence by using the AEL of the previous scanline, which is
received from the previous processor in the pipeline. On finishing the update
task, the resulting AEL is sent to the next processor in the pipeline, and a
draw task is created and stored in the draw task queue. The draw tasks are read
from the draw task queue and executed semi-parallel with the update tasks (see
Figure 2a). Since the update tasks are executed sequentially, efficiency is
reduced by a start-up delay and a pipeline delay [2]. Moreover, since the
update tasks accounts for 5% of the workload, the speed-up factor is limited by
20 (Amdahl's Law [7]).
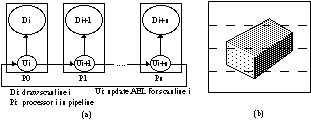
Fig.2 . Control flow mapping onto a pipeline of processors (a) and
static, equal strips (b).
To solve the limited scalability of both interleaving techniques, we cluster
the processors into groups, which compute strips consisting of more than one
scanline. The scanlines in the strip can be distributed among the processors in
the group by using normal or data pipeline interleaving. We have experimented
with three strip scheduling strategies to distribute the strips among the
groups: static, equal strips, dynamic strips with global seeking and dynamic
strips with mate seeking.
With static, equal strips the screen is divided into N equal strips, with N the
number of groups. A disadvantage is the uneven load balance, because images
tend to be more complex near the centre of the screen (see Figure 2b).
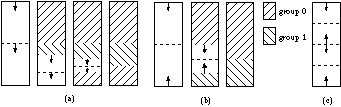
Fig.3. Global seeking (a) and mate seeking (b) with two groups and
screen subdivision for mate seeking for 4 groups (c).
This strategy is based on task stealing [4]. When a group of processors has
finished its strip, it sends a request to the other groups to steal work from
them; if there is a group that has enough work left, it gives it to the
requesting group. In this way the work is distributed evenly among the groups
of processors (see Figure 3a). Some overhead is introduced: when a group gets
work from another group, the AEL of the first scanline, which might be distant
from the last drawn scanline, needs to be computed.
To minimize the number of screen subdivisions, we developed the mate seeking
technique, in which two neighbouring groups, called mates, start drawing their
strip working in opposite direction towards each other. Only when they reach
the same scanline, the groups need to steal work from the other groups (see
Figure 3b). So groups of processors can work on adjacent scanlines as long as
possible. This is achieved at the cost of some additional communication to
check whether two groups have reached the same scanline. Figure 3c gives an
example of the initial screen subdivision and the drawing directions in the
strips, when there are four groups.
The system was implemented under Helios on a Parsytec MultiCluster-2 transputer
system, which consists of three subsystems: the IO subsystem with a 4 Mb T800,
which is the host processor, and a GDS-2 graphics board, the processing
subsystem with 32 2 Mb T800's, which are used for display, and a programable
link switch to which all processors are connected (see Figure 4). The solid
modelling system runs on the host. The renderers are physically interconnected
by a wrap-around mesh [7]. In Figure 4 a row of squares depicts a group that
compute a strip in parallel. We define the MxN architecture to be the
configuration with M groups, each group consisting of N processors, arranged in
a MxN wrap-around mesh. Measurements of the display times of the test models
(see Figure 10) were done to see, which concepts are most efficient. Also we
wanted to find out whether the use of an exact representation of the quadrics
did benefit in a multiprocessor environment. All times are given in seconds.
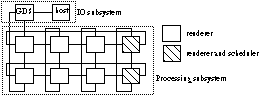
Fig.4. The implemented system and the physical connections for a 2x4
architecture.
Testing the interleaving techniques was done with the Hobin and Bing models.
From Figure 5 we see that normal interleaving performs best and we can
conclude, that the pipeline delay and the start-up delay are worse than the
increased scanline-coherence exploitation.
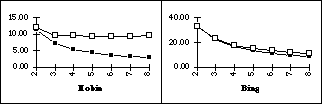
Fig. 5. Scan conversion times with normal (n)and data pipeline
interleaving(r).
From Figure 6 we see that global seeking is slightly better than mate seeking,
because mate seeking results in more communication than global seeking. So the
optimum system uses global seeking and normal interleaving. From Figure 7 we
see that the system with 32 processors performs best with an 8x4 architecture.
Comparing the results for the 32x1, 1x32 and the 8x4 architecture, we see that
clustering processors in groups benefits the system.

Fig.6. Display times for the three strip scheduling techniques using a
8x4 architecture

Fig. 7. Display times for different dimensions of the optimum system.
To test the scalability of the system, measurements for all models were done
with different numbers of processors, ranging from 1 to 32. We define the
efficiency as EN = T1/(TN*N) * 100% where T1 is the display time on 1 processor
and TN is the display time on N processors. In Figure 8 we see that the
efficiency decreases rapidly; this is because of the low performance of the
Helios communication for the preprocessing results, the pixel colours and the
strip scheduling requests.

Fig.8. Efficiency of the optimum system with increasing number of
processors
To get insight in the benefits of using quadrics exactly instead of polygonal
models, we have done measurements with a polygonal Bing model. From Figure 9 we
see that the efficiency decreases less with quadrics than with polygons with an
increasing number of processors.

Fig. 9. Display times and efficiency for the quadric and polygonal
Bing model for an increasing number of processors
We have developed a multiprocessor display system for quadric CSG models with
interactive display times. Due to the expensive communication primitives under
Helios, the attempt to exploit coherence as fully as possible was not
successful. An analytical model of the implementation might help to predict,
whether data pipeline interleaving and mate seeking pay off in other
environments. Clustering processors in groups working on strips of more than
one scanline turned out to be a good idea. The use of exact representations for
quadrics resulted in a better scalable system. Future scanline interleaved
graphics architectures based on general-purpose processors should have
efficient and scalable communication facilities, supporting both point-to-point
communication and broadcasting.
We would like to thank Wim Bronsvoort, Erik Jansen, Ad Langenkamp and Frits
Post for the stimulating discussions and FEL TNO for using its hardware
facilities.
1. Atherton PR (1983) A scan-line hidden surface removal procedure for
constructive solid geometry. Computer Graphics 17(3): 73-82
2. Blonk M, Bronsvoort WF, Bruggeman F, de Vos L (1988) A parallel system for
CSG hidden-surface elimination. In: Parallel Processing, Proceedings IFIP WG
10.3 Working Conference on Parallel Processing, Cosnard M, Barton MH and
Vanneschi M (eds), Elsevier Science Publishers, Amterdam, pp 139-151
3. Bronsvoort WF (1990) Direct display algorithms for solid modelling. Ph.D.
Thesis. Delft University Press.
4 Holliman NS (1990), Visualising solid models: An exercise in parallel
programming. School of Computer Studies and Mechanical Engineering, University
of Leeds, United Kingdom
5 van Kleij R (1992) Efficient Display of Quadric CSG Models. Computers in
Industry 19(2):201-211
6. May D, Shepard R (1987) Communicating process computers. Inmos Technical
Note 22, Inmos Ltd, Bristol.
7. Quinn MJ (1987) Designing efficient algorithms for parallel computers. New
York, McGraw-Hill

Fig. 10. Test models used for measurements (display resolution: 512x512
pixels).