Un'introduzione agli Oggetti Dati in Visual Dbase 7
Ultima modifica - 15 Marzo 1999
Ken Mayer, dBVIPS
L'obbiettivo di questo Documento
Questo documento e' stato creato per aiutare un programmatore nuovo all'ambiente Visual Dbase 7 a capire gli oggetti Dati. Questi oggetti sono necessari per aiutare uno sviluppatore ad usare Visual Dbase 7 al massimo delle sue potenzialita'.A tal fine questo sara' probabilmente un documento abbastanza lungo, cosi' come coprira' il lato "pratico" di lavorare con questi oggetti, discutendo le proprieta', eventi e metodi di ciascuno di essi, discutendo le relazioni di ciascuno oggetto con gli altri e cosi' via.
Uno sviluppatore nuovo a questo ambiente puo' anche voler esaminare alcuni degli altri documenti HOW TO al sito web dell'autore (indicato nel sommario di questo documento), includendo (ma non limitandosi ad essi) X2OODML.ZIP e MISCCODE.ZIP. Si dovrebbe anche visitare il sito web di Alan Katz e scaricare il suo documento OODML.HOW, che discute i concetti e la teoria dell' Object Oriented Database Manipulation Language.Il sito di Alan e'
http://www.ksoftinc.com/vdb
__________________________________________________________________________________
AVVISO:Questo documento ha lo scopo di aiutarti ad iniziare e non puo' coprire ogni diversa cosa che tu programmatore, puoi desiderare o hai bisogno di effettuare. Uno dei punti di forza ed anche uno dei fattori che confondono del Dbase e' che e' flessibile. A causa della sua flessibilita', un programmatore puo' confondersi cercando di trovare la giusta via per fare qualcosa per le proprie ( o piu' importante dei propri clienti) necessita'.
La cosa migliore da fare e' di usare questo documento, gli altri documenti menzionati, e la migliore risorsa disponibile, i Newsgroup del Visual Dbase messi a disposizione da Dbase Inc. Se non si riesce a fare qualcosa, visita i newsgroup e poni una domanda. Alla maggior parte delle domande viene data una risposta entro poche ore. ________________________________________________________________________________
Menu
- Uno sguardo d'insieme
- Una dettagliata analisi di ciascun oggetto Dati
- Sessioni
- Database
- Stored Procedure
- Query
- Rowset
- Index/DBFIndex (non documentato)
- Array di campi
- Campo
- Iniziando con gli oggetti Dati
- TableDef (non documentato)
- UpdateSet
- DataModule
- Sommario
Uno sguardo d'insieme
Oggetti Dati ? Che cosa sono mai gli oggetti dati ?
dBASE, Inc. ha preso il modello ad oggetti di prim'ordine che era stato creato per il Visual dBASE 5.x, e lo ha incluso nelle tabelle e nei database. Questo significa che si possono ora usare tabelle, records, e campi come oggetti, ognuno di essi con il proprio set di proprieta', eventi e metodi. Questo da' al programmatore molto controllo sul codice, e gli da' anche molta della potenza e riusabilita' del linguaggio orientato agli oggetti che si puo' ottenere dagli altri oggetti in dBase. E cosi',quali sono questi oggetti e come essi sono collegati fra loro? Prima che si vada in profondita' nella discussione facciamo un passo indietro e diamo uno sguardo agli oggetti Dati in Visual dBASE.
La maggior parte di questi oggetti sono contenitori. Cio' significa che essi possono avere all'interno altri oggetti. Un esempio di oggetto di questo tipo che sara' utilizzato spesso e' l'oggetto Query. Questo oggetto ha all'interno un oggetto rowset cosicche' esso e' un contenitore per l'oggetto rowset. Diversamente da altri contenitori vi puo' essere solo un oggetto rowset per ciascun oggetto query. L'oggetto rowset e' un contenitore di un array di campi. L'array di campi contiene i puntatori a ciascun oggetto campo che e' contenuto nel rowset. Quindi si puo' disegnare un diagramma come il seguente:
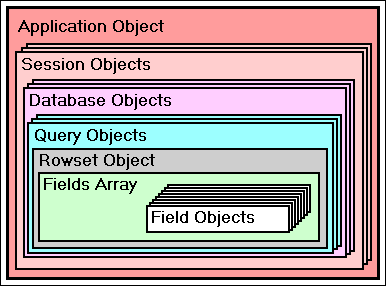
(Graphic courtesy of Gary White)
L'oggetto rowset ha un genitore, che e' la query, gli array di campi hanno un genitore che e' l'oggetto rowset, gli oggetto campo hanno un genitore che e' l'array di campi.
Da notare che non si puo' definire un oggetto rowset indipendentemente dall'oggetto query, ma puoi definire un oggetto campo indipendente da un array di campi o da un rowset (ma il suo uso all'esterno del rowset e' abbastanza difficoltoso, a meno che non lo si aggiunga all'array di campi di un rowset -- Gary White sta considerando una maniera di creare eventi usando l'oggetto campo ...).
Ora, per rendere le cose piu' interessanti, un oggetto database si riferisce ad un alias BDE. Un database, per sua vera natura, contiene tabelle. In tal modo l'oggetto database e' un riferimento ad un oggetto -- il database stesso. Tuttavia cosi' si semplifica troppo l'argomento. Si dovrebbe considerare l'uso di un BDE alias per le ragioni che saranno discusse quando si trattera' dell'oggetto database.
Un oggetto sessione e' usato per trattare accessi simultanei al database. (Lo scenario piu' probabile potrebbe essere una applicazione MDI dove possono essere aperte diverse mappe che accedono alle stesse tabelle.
Stored Procedures possono essere usate solo con tabelle SQL Server, e sono usate per accedere a procedure conservate sul database del server.
Le tabelle Standard locali non riconoscono le Stored Procedures e tentare di usarle su tabelle locali puo' causare problemi.
Un datamodule puo' essere usato per contenere: oggetti database, oggetti stored procedure, oggetti sessione ed oggetti query. I rowset sono, come notato in precedenza, contenuti automaticamente dalle query, cosi' mentre un datamodule contiene la query, esso non contiene direttamente il rowset.
Quanto sei confuso in questo momento? Spero non troppo.... Tutto questo conduce a qualcosa...vediamolo.
NOTA: Un aspetto che confonde un po' quando si lavora con gli oggetti dati in Visual Dbase e' che gli oggetti dati non hanno un riferimento alla form (o al report). Cio' significa che quando si progetta del codice contenente eventi e metodi degli oggetti dati, non ci si puo' riferire direttamente ad oggetti su una form o su un report. Vi sono delle maniere per aggirare questo problema, ma non si discutera' di esse qui, poiche' non si vuole confondere oltre quanto lo si possa gia' essere.
Una dettagliata Analisi di ciascun oggetto Dati.
Ciascuno di questi oggetti dati, come gia' notato in questo documento, ha proprieta', eventi e metodi.
Proprieta'
Le proprieta' sono gli attributi dei controlli. L'impostazione di una proprieta' puo' essere effettuata a programma cosi' come negli ambienti di progettazione (form, report, datamodule).L'impostazione e' normalmente costituita da un singolo valore, per esempio, una stringa di caratteri, un numero o un riferimento ad un altro oggetto.
Eventi
Gli eventi sono qualcosa a cui i controlli possono rispondere, un click del mouse, un controllo che ottiene il fuoco, una variazione del valore di un controllo. Tuttavia, al verificarsi dell'evento, perche' effettivamente avvenga qualcosa, si deve agganciare a tale evento del codice.
Eventi il cui nome inizia con ON, come onOpen, avvengono dopo l'azione alla quale essi si riferiscono. Cosi' l'evento onOpen avviene dopo che la query e' aperta. La seconda cosa e' che gli eventi che iniziano con CAN, come canClose, devono restituire un valore logico che determinera' se l'azione indicata puo'continuare. Cosi' l'evento canClose di una query deve ritornare true prima di poter chiudere la query. La restituzione di un valore false non permettera' la chiusura della query. La mancata restituzione di un valore Booleano puo' dare risultati imprevedibili.
Metodi
I metodi sono codice che effettua un'azione. Gli oggetti hanno un certo numero di metodi predefiniti che sono chiamati attraverso il controllo, p.es. form.rowset.next()
Una cosa che va tenuta presente e' che, se si usano i metodi predefiniti per inserire il proprio codice (over-riding del metodo), si dovra' quasi sempre chiamare il metodo predefinito, prima, dentro o dopo il proprio codice (Cio' puo' essere ottenuto inserendo SUPER::methodname() nel codice...).
SESSION
Un oggetto session e' come un contenitore. Esso puo' essere usato sia con un oggetto database sia direttamente con un oggetto query (tuttavia, se si sta usando un oggetto database, si dovrebbe usare la sessione con il database, non la query...).
Nelle precedenti versioni di Dbase, le sessioni erano necessarie quando una applicazione permetteva un accesso multiplo alle stesse tabelle dentro una "sessione" dell'applicazione. Se le tabelle vengono aperte ognuna nella propria sessione, si evitano alcuni tipi di conflitto (non tutti).
In Visual dBASE 7, il solo, reale, obbiettivo di usare un oggetto sessione e' raggiunto quando si desidera usare l'evento onProgress (per agganciarsi ad una bar progress) o se si stanno usando tabelle criptate (si puo' effettuare l'"auto login"). Oltre a questi casi , l'uso delle sessioni confonde ed aggiunge un livello di difficolta' in piu' a quello che lo sviluppatore sta facendo.
Le Sessioni hanno le seguenti proprieta', eventi e metodi:
- La proprieta' className e' a sola lettura e restituisce il nome della classe("SESSION"). Essa puo' essere usata quando navigando con la sintassi punto si cerca di scoprire a quale oggetto si e' arrivati.
- La proprieta' handle e' un collegamento BDE e dovrebbe essere usata solo se si sta accedendo al BDE attraverso le API (Application Programmer Interface) del BDE.
- La proprieta' lockRetryCount e' il numero di volte che si tenta di ripetere un blocco.(Un blocco puo' effettuarsi implicitamente, tentando di cambiare un controllo datalinkato su una form, o puo' essere fatto esplicitamente con i metodi lockRow o lockSet di un rowset...).
- La proprieta' lockRetryInterval e' il numero di secondi da attendere fra ciascun tentativo di blocco. (Vedi lockRetryCount)
- La proprieta' parent contiene un riferimento al datamodule, alla form o al report che "contiene" l'oggetto sessione.
- L'evento onProgress e' periodicamente attivato durante un lungo processo. Esso puo' essere usato per aggiornare, per esempio, un oggetto progress bar su una form e mostrare quindi all'utente quello che sta avvenendo.
- Il metodo access restituisce il livello di accesso dell'utente per quella sessione.
- Il metodo addPassword e' usato solo per tabelle .DB tables e permette di aggiungere una password alla lista delle password.
- Il metodo login permette all'utente di accedere ai meccanismi di sicurezza dei files .DBF (Si veda il comando XBase PROTECT nell'aiuto in linea).
- Il metodo user restituisce il login dell'utente per quella sessione.
Per creare una nuova sessione tutto quello che si deve fare e':
sMySession = new Session()
Per usare una sessione si deve assegnare una proprieta' sessione a quegli oggetti ( database e query) che sono influenzati da quella specifica sessione.
Per esempio:
sMiaSession = new Session()
dMioDatabase = new Database()
dMioDatabase.databaseName := "MioAlias"
dMioDatabase.session := sMiaSession
dMioDatabase.active := true
qMiaQuery = new Query()
qMiaQuery.database := dMioDatabase
qMiaQuery.session := sMiaSession
qMiaQuery.sql := "select * from MiaTabella"
qMiaQuery.active := true
qMiaQuery2 = new Query()
qMiaQuery2.database := dMioDatabase
qMiaQuery2.session := sMiaSession
qMiaQuery2.sql := "select * from MiaTabella2"
qMiaQuery2.active := true
Default Session
Si noti che c'e' sempre una sessione di default, che e' accessibile attraverso l'oggetto database di default dell'oggetto applicazione:
?_app.databases[1].session.access()
Se si desiderano usare sessioni nelle proprie applicazioni si dovrebbe valutare la possibilita' di impostarle nei propri datamodules, forms o report (secondo il progetto dell'applicazione). Si consulti l'aiuto in linea per maggiori dettagli sull'uso delle sessioni.
DATABASE
L'oggetto database e' usato quando si usano gli Alias BDE per gestire i propri archivi di dati. Per maggiori dettagli sugli Alias BDE si dovrebbero leggere MISCCODE.ZIP, nel sito web dell'autore, cosi' come la Guida al Programmatore che arriva con il dBASE e l'aiuto del BDE....
Un alias e' assolutamente richiesto quando si lavora con le tabelle SQL Server (come Interbase, Oracle, ecc.) ed e' opzionale ma utile quando si usano tabelle locali.
Se si decide di usare un alias, si dovrebbe usare un oggetto database nel proprio codice e nelle proprie forms, reports, datamodules ecc.
Se si sta lavorando solo con tabelle locali, perche' si dovrebbe usare un Alias BDE e quindi un oggetto database?
- L'utente puo' desiderare di muovere (o installare) i dati in una differente directory rispetto a quella stabilita durante la progettazione. Tutto quello che e' necessario in quel caso e' di cambiare il percorso dell'alias BDE facendolo puntare alla nuova directory e l'applicazione girera' senza alcuna modifica al codice sorgente.
- Puo' essere necessario rilasciare l'applicazione in una rete e non sapere esattamente in quale directory essa andra'. Ancora, cambiare il percorso nell'Alias BDE e' tutto cio' che e' necessario effettuare.
- Si possono eventualmente muovere i dati ad un server come Interbase, Oracle o uno degli altri...Si potrebbe allora progettare l'intera applicazione usando tabelle locali (se si hanno gli alias impostati), muovere ogni cosa al server quando la si rilascia ed ancora potrebbe non essere necessaria alcuna variazione all'interno della propria applicazione.
- C'e' una discussione nel documento HOW TO denominato "MISCCODE" nel mio sito web su come usare e creare Alias BDE. Se non si e' familiari con questo argomento, bisognerebbe darci un'occhiata.
Qui ci sono le proprieta' e metodi (non ci sono eventi) dell'oggetto database (alcuni di questi non sono coperti in gran dettaglio qui, poiche' l'autore non usa tabelle SQL Server... Vedi l'aiuto in linea per maggiori dettagli).
- La proprieta' active e' usata in realta' per "aprire" il database, o renderlo disponibile ad una applicazione. Cio' significa che si puo' disattivarlo, fare alcune cose, come per esempio cambiare la proprieta' databaseName, e successivamente riattivarlo.
- La proprieta' cacheUpdates determina se si devono nascondere localmente variazioni alle tabelle per dei processi batch successivi. (Inconveniente -- che cosa capita se si ha una interruzione di corrente elettrica?)
- La proprieta' className e' a sola lettura e dovrebbe fornire "DATABASE" -- essa e' utile quando si opera con la struttura punto ...
- La proprieta' databaseName e' obbligatoria -- e' il nome Alias BDE, puo' essere indifferentemente maiuscolo o minuscolo (se esso appare tutto con lettere maiuscole nel BDE Administrator, lo si puo' inserire minuscolo, maiuscolo ecc.).
- La proprieta' driverName e' il tipo di database (p.es., DBASE, o qualsiasi altro). Questo e' assegnato automaticamente dalla definizione del database del BDE Admistrator.
- La proprieta' handle e' un handle BDE (numero arbitrario che identifica il database), e dovrebbe essere usato solo se si opera con le API del BDE.
- La proprieta' isolationLevel determina il livello di isolamento della transazione (lettura non effettuata, lettura effettuata (default), lettura ripetibile).
- La proprieta' loginString puo' essere usata per accedere automaticamente al database, piuttosto che richiedere il codice utente (login) ciascuna volta che l'applicazione e' avviata.
- La proprieta' parent fornisce un riferimento oggetto alla form, al report o al datamodule genitori.
- La proprieta' session fornisce un riferimento all'oggetto sessione al quale il database e' assegnato. Se non e' impostata viene automaticamente assegnata la sessione "default" del dBase.
- La proprieta' share e' usata per determinare come condividere le risorse di accesso ai dati.
- Il metodo abandonUpdates elimina tutte le variazioni presenti nella cache.
- Il metodo applyUpdates tenta di registrare le variazioni presenti nella cache.
- Il metodo beginTrans avvia una transazione -- esso parte iniziando a registrare le variazioni. (Si veda commit e rollback ...).
- Il metodo close chiude il database (imposta la proprieta' "active" a false).
- Il metodo commit tenta di salvare tutte le transazioni effettuate a partire dall'ultima chiamata al metodo beginTrans().
- Il metodo copyTable e' usato per copiare una tabella. (Questo e' equivalente al comando COPY TABLE).
- Il metodo createIndex e' usato per creare un indice in una tabella partendo da un oggetto indice. Si noti che gli oggetti indice ed il metodo createIndex non sono trattati nell'aiuto in linea (sono caratteristiche non documentate), e sono trattati qui con una certa profondita', ma vengono descritti con maggiore dettaglio sul documento "Undocumented Features" presentato all'Icon98 e scaricabile dal sito web dell'autore.
- Il metodo dropIndex e' equivalente al comando XBase DELETE TAG -- esso rimuove un indice (tag) dagli indici presenti in una tabella.
- Il metodo dropTable e' equivalente al comando DELETE TABLE. Esso rimuove anche tutti i files associati con una tabella. (MDX,DBT).
- Il metodo emptyTable e' equivalente al comando XBase ZAP -- esso rimuove tutte le righe nella tabella.
- Il metodo executeSQL e' usato per trasferire i comandi SQL direttamente al Server SQL (utile solo quando e' usato con databases come Interbase, Oracle e altri).
- Il metodo getSchema fornisce informazioni su un database (come le tabelle, procedure o viste).
- Il metodo open apre la connessione con il database (imposta la proprieta' active a true).
- Il metodo packTable e' equivalente al comando XBase PACK -- esso e' utile solo per tabelle .DBF ed elimina tutte le righe cancellate in una tabella.
- Il metodo reindex ricostruisce i tag degli indici di una tabella (ed in molti casi risolve problemi di indici corrotti poiche' la definizione del tag dell'indice e' ancora nella testata della tabella. Questo vale solo per i tipi di tabella .DBF e .DB.
- Il metodo renameTable cambia il nome della tabella e tutti i riferimenti ad essa nei files collegati (per esempio il file .DBF puo' avere un .MDX e un .DBT - i loro nomi verranno anche cambiati).
- Il metodo rollBack annulla le variazioni effettuate su una tabella dopo una chiamata beginTrans().
- Il metodo tableExists e' usato per vedere se una tabella esiste in un database.
Il Database di default
E' importante notare che dBase ha un database di default, che punta alla "directory corrente". A questo si puo' sempre accedere attraverso l'oggetto applicazione:
_app.databases[1]
E qualsiasi metodo dell'oggetto database puo' essere eseguito:
_app.databases[1].packTable( "MyTable" )
La proprieta' active del database di default non puo' essere modificata -- si puo' tentare di impostarla a false, ma non avverra' nulla. Il database di default ha anche una sessione di default (si veda sotto).
Creazione di un riferimento ad un oggetto Database
Si puo' creare un riferimento ad un oggetto database in maniera abbastanza semplice. Ci sono solo alcune cose che si devono impostare:
- La proprieta' databaseName e' il nome dell'Alias BDE.
- La loginString se si ha necessita' (particolarmente per database SQL Server) e si desideri accedere al database automaticamente piuttosto che attraverso la finestra di dialogo di default.
- La proprieta' active deve essere posta a true.
- // for local tables
- d = new Database()
d.databaseName := "MyAlias"
d.active := true
// for a SQL Server database
d = new Database()
d.databaseName := "MyAlias"
d.loginString := "username/password"
d.active := true
// Assign a new session:
s = new Session()
d.databaseName := "MyAlias"
d.session := s
d.loginString := "username/password"
d.active := true
Transaction Processing
Uno delle cose per cui si puo' desiderare usare l'oggetto database e' per la gestione delle transazioni. Molte applicazioni di questi giorni non usano piu' le transazioni, ma e' ancora qualcosa di cui si puo' avere necessita' per le proprie applicazioni o che gli utenti possono preferire.
Una transazione e' un procedimento grazie al quale si svolgono in successione una serie di operazioni senza che l'utente intervenga. Questo procedimento e' qualche volta chiamato "batch".
Quando si attiva un database, si puo' iniziare una transazione, con il metodo del database beginTrans():
// per tabelle locali
d = new Database()
d.databaseName := "MyAlias"
d.active := true
d.beginTrans()
// fa qualcosa -- inizia l'applicazione
// o carica la form e permette all'utente
// di fare il proprio lavoro ... etc.
d.commit() // salvera' le transazioni, ed aggiornera'
// le tabelle in maniera appropriata
// Oppure
d.rollback() // cancellera' tutte le transazioni iniziando
// da quando il metodo beginTrans() e' stato chiamato.
Metodi di Manutenzione delle Tabelle
Ci sono diversi metodi che sono collegati all'oggetto database che replicano alcuni dei comandi Xbase DML. Brevemente essi sono:
- copyTable() -- questo e' l'equivalente del comando XDML "COPY TABLE". Esso copia la tabella insieme ai file collegati con essa (cioe' .MDX, .DBT per le tabelle .DBF ) se si sta lavorando con tabelle locali.
- createIndex() -- questo, combinato con l'oggetto indice, e' equivalente al comando INDEX ON.... Esso sara' descritto in maggiore dettaglio quando si parlera' dell' oggetto indice. Questo oggetto non e' trattato nella documentazione del Visual Dbase.
- dropIndex() -- cancella un tag di indice come nel comando DELETE INDEX.
- dropTable() -- e' equivalente al comando DELETE TABLE -- esso elimina pure i files associati con le tabelle locali.
- emptyTable() -- e' equivalente al comando XDML ZAP -- esso rimuove tutte le righe dalla tabella. Si noti che la tabella non deve essere in uso in alcuna area di lavoro quando si chiama questo metodo. Se lo e', si ricevera' un messaggio di errore.
- packTable() -- e' equivalente al comando XDML PACK -- esso rimuove le righe segnate con il flag di cancellazione dalle tabelle di tipo .DBF. Come nel caso di emptyTable, la tabella non puo' essere gia' in uso.
- reindex() -- simile al comando REINDEX in XDML, in Visual dBASE 7 e' piu' robusto che nelle precedenti versioni -- riparera' anche tag di indici corrotti. Cosi' come con altri metodi qui descritti, la tabella deve essere aperta in maniera esclusiva.
- renameTable() -- e' equivalente al comando XDML RENAME TABLE. Esso individua anche i file ausiliari e li rinomina in maniera appropriata.
STORED PROCEDURE
Se si sta lavorando solo con tabelle locali allora l'oggetto STOREDPROC risulta privo di utilita'. Tuttavia se si lavora con database SQL Server (o "backend server") allora questo oggetto puo' essere molto utile.
Non ho diretta esperienza con tale oggetto cosi' dovrete avere pazienza. Dopo avere descritto le proprieta' non ho molto altro da dire....
- La proprieta' active determina se la stored procedure e' aperta.
- La proprieta' className e' una proprieta' che dovrebbe mostrare "STOREDPROC".
- La proprieta' database contiene un riferimento al database cui la stored procedure appartiene.
- La proprieta' handle e' un numero arbitrario che identifica la stored procedure nel BDE, e dovrebbe essere usata solo se si sta tentando di lavorare con le API del BDE.
- La proprieta' params e' un array associativo che contiene i parametri per la stored procedure sul server.
- La proprieta' parent contiene un riferimento al datamodule, alla form o al report che e' il contenitore di questo oggetto.
- La proprieta' procedureName e' il nome della stored procedure.
- La proprieta' rowset e' un puntatore alla procedura che e' il risultato della stored procedure.
- La proprieta' session e' un puntatore alla sessione di controllo. Se e' vuoto, si riferisce alla sessione di default.
- L'evento canClose puo' essere usato per bloccare la chiusura della stored procedure sulla base di un codice definito dallo sviluppatore.
- L'evento canOpen puo' essere usato per bloccare l'apertura di una stored procedure sulla base di un codice definito dall'utente.
- L'evento onClose scatta dopo una chiusura con successo della stored procedure (la proprieta' active e' posta a false).
- L'evento onOpen scatta dopo un'apertura con successo della stored procedure (la proprieta' active e' posta a true).
- Il metodo execute esegue la stored procedure (chiamata automaticamente quando la proprieta' active e' posta a true).
- Il metodo prepare prepara la chiamata alla stored procedure.
- Il metodo requery riesegue la stored procedure.
- Il metodo unprepare resetta tutto quando la stored procedure viene chiusa (chiamato automaticamente quando la proprieta' active e' posta a false).
- La parte seguente proviene dall'Aiuto in linea:
"Un oggetto StoredProc serve per chiamare una procedura memorizzata in un database. La maggior parte delle procedure memorizzate richiede uno o più parametri di input e può restituire uno o più valori di output. I parametri vengono passati e ricevuti dalla procedura memorizzata tramite la proprietà params dell'oggetto StoredProc, la quale punta ad un array associativo di oggetti Parameter.
Alcune procedure memorizzate restituiscono un rowset. In tal caso, l'oggetto StoredProc è simile ad un oggetto Query, con la differenza che, anziché eseguire un'istruzione SQL che descrive i dati da recuperare, si definisce il nome di una procedura memorizzata, le si passano i parametri e la si esegue. Al rowset risultante si accede tramite la proprietà rowset dell'oggetto StoredProc, proprio come avviene in un oggetto Query.
Poiché le procedure memorizzate sono basate su server SQL, occorre creare ed attivare un oggetto Database, da assegnare poi alla proprietà database dell'oggetto StoredProc. Le tabelle standard non sopportano le procedure memorizzate.
Quindi, bisogna impostare la proprietà procedureName al nome della procedura memorizzata. Per la maggior parte dei server SQL, BDE può acquisire i nomi e i tipi dei parametri per la procedura memorizzata. Su alcuni server non è disponibile alcuna informazione; in questo caso, nella proprietà procedureName occorre includere anche i nomi dei parametri".
Vi sono delle altre informazioni nell'aiuto in linea se si necessita di maggiori spiegazioni.
QUERY
L'oggetto Query e'l'oggetto dati piu'spesso incontrato. L'oggetto query e' usato per creare un riferimento alle singole tabelle del proprio database, ed e' obbligatorio quando si lavora con tabelle che usano l'OODML.
E' quindi davvero importante che lo si comprenda bene. Esso e' il contenitore del rowset, che e' dove si trovano la maggior parte dei metodi e degli eventi che gestiscono i dati, cosi' come il rowset e' un contenitore per i campi... Prima che si parli del suo uso, diamo un'occhiata alle proprieta', agli eventi ed ai metodi della query.
- La proprieta' active e' usata per rendere la query "active" -- fino a quando questa proprieta' non e' impostata, non vi e' alcun rowset disponibile, poiche' il rowset non e' creato fino a che tale proprieta' non e' true. Si noti che questa e' una proprieta' da impostare necessariamente -- affinche' si acceda realmente ai dati in una tabella questa proprieta' deve essere true.
- La proprieta' className e' a sola lettura, e dovrebbe sempre mostrare QUERY. Cio' e' utile quando si attraversa la notazione punto per sapere dove ci si trova.
- La proprieta' constrained e' usata per determinare, nel caso vi sia una clausola WHERE nella proprieta' SQL (vedi sotto), se gli aggiornamenti al rowset devono essere limitati dalla clausola WHERE . Questa proprieta' lavora solo per tabelle "STANDARD" ( .DBFs locali e .DBs).
- La proprieta' database e' un puntatore all'oggetto database, nel caso ve ne sia uno in uso. Daremo un'altra occhiata a questa proprieta' quando si discutera' dell'oggetto database.
- La proprieta' handle e' il numero arbitrario che identifica la query nel BDE (Borland Database Engine) -- essa e' a sola lettura, ma puo' essere utile se si decidono di usare le API del BDE per fare delle cose che non si possono effettuare direttamente con l'oggetto query (questo e' un argomento avanzato e non si discutera' di esso successivamente in questo documento).
- La proprieta' masterSource e' usata (perlopiu' per le tabelle SQL Server, Interbase, Oracle, e cosi' via) per impostare la master query in una relazione genitore/figlio. Se si sta lavorando con tabelle locali non si dovrebbe usare questa proprieta' a meno che non si usino i params array ( come indicato sotto). Dall'aiuto in linea: "Impostando la proprietà masterSource, i parametri nell'istruzione SQL vengono automaticamente sostituiti con i campi corrispondenti del rowset principale, forzando perciò la query secondaria. Possono essere usati campi calcolati. I campi vengono confrontati ai parametri per nome. La corrispondenza con il nome del campo non tiene conto della differenza tra maiuscole e minuscole."
- La proprieta' params e' un puntatore ad un array associativo che contiene parametri per l'istruzione SQL nella proprieta' SQL o per una stored procedure.
- La proprieta' parent e' per default null -- se una query e' usata in un datamodule, form o report questa proprieta' punta a quell'oggetto.
- La proprieta' requestLive determina se il rowset e' scrivibile. Se essa e' posta a false (il default e' true) allora il rowset e' a sola lettura.
- La proprieta' rowset e' un puntatore all'oggetto rowset che e' contenuto nella query, quando la query e' attiva.
- La proprieta' session e' un puntatore all'oggetto sessione. Si discutera' di questo argomento piu' avanti.
- La proprieta' sql e' una parte vitale della query -- e' il mezzo, attraverso le istruzioni standards SQL SELECT, per definire la tabella, le righe e i campi che saranno usati nel rowset risultante. NOTA: Si puo' usare l'editor SQL per generare un file .SQL ed usarlo con la proprieta' sql-- tuttavia si scoprira' che l'SQL generato e' senza necessita' voluminoso e poco maneggevole e spesso ha bisogno di modifiche per essere davvero utile. In piu' si puo' facilmente incappare con queries a sola lettura usando il generatore SQL. Vedere le discussioni qui ed in altri documenti nel sito web dell'autore (MISCCODE.ZIP in particolare) riguardante quanto si ha realmente bisogno di sapere di SQL.
- La proprieta' unidirectional specifica se assumere che la navigazione sia solo in avanti per aumentare le prestazioni sui databases SQL-server.
- La proprieta' updateWhere determina quali campi usare nel costruire la clausola WHERE in una istruzione SQL UPDATE. Vale solo per databases SQL-server (p.es., Interbase, ecc.).
- L'evento canClose scatta quando la proprieta' active viene posta a false. Se questo evento ritorna un valore false la query non puo' essere chiusa.
- L'evento canOpen scatta quando la proprieta' active e' posta a true. Se questo evento ritorna un valore false, la query non puo' essere aperta.
- L'evento onClose si attiva dopo che la query e' chiusa e dopo l'evento canClose, se c'e'.
- L'evento onOpen si attiva dopo che la query e' aperta e dopo l'evento canOpen, se c'e'.
- Il metodo execute e' automaticamente chiamato quando la proprieta' active e' posta a true, esso puo' essere chiamato ancora, se necessario, ma cio' non dovrebbe essere fatto a meno che non si crei una custom query e si scavalchi il metodo execute (in questo caso si deve chiamare questo metodo...)
- Il metodo prepare prepara la stored procedure stabilita nella proprieta' procedureName di un oggetto StoredProc o l'istruzione SQL conservata nella proprieta' sql di un oggetto Query. Se l'oggetto e' connesso ad un database basato su SQL-server, il messaggio prepare e' passato al server (si veda l'aiuto in linea).
- Il metodo requery e' usato per effettuare di nuovo una query sulla tabella nel caso in cui l'istruzione SQL sia stata modificata. Cio' corrisponde ad impostare la proprieta' active a false e quindi di nuovo a true, senza chiamare di nuovo il metodo prepare.
- Il metodo unprepare rilascia (automaticamente) le risorse usate dalla query quando la proprieta' active e' posta a false.
Come usare una query?
Si ritornera' su questo argomento, ma per iniziare, ed assumendo che si sta lavorando con tabelle locali, sara' necessario creare una instanza (copia) della query, assegnare la proprieta' SQL, e quindi porre la sua proprieta' active a true.
q = new query()
q.sql = "SELECT * FROM mytable"
q.active = true
Una cosa che qualche volta preoccupa i nuovi utilizzatori del Visual Dbase e' che essi "devono conoscere l'SQL". No, non e' necessario. Il comando sopra citato e' la maggior parte dell'SQL che si deve assolutamente conoscere per costruire delle applicazioni Visual dBase molto dettagliate. La maggior parte di quello che si puo' desiderare di fare e' incluso nelle proprieta', negli eventi e nei metodi dell'oggetto rowset che si trattera' tra poco.
L' "*" nell'istruzione SELECT e' una wildcard, come in DOS -- essa significa quando e' usata nella SELECT, "tutti i campi".
Le tre istruzioni di sopra sono le sole necessarie se si sta creando un programma che manipola dati, ma cosa bisogna fare se si desidera usare una form o un report ?
Non potrebbe essere piu' semplice. Si apra una form nell'editor di form, si clicchi su "Tabelle" nel centro di controllo e si trascini la tabella che si desidera usare sulla superficie della form (o del report). Si vedra' un'icona che rappresenta l'oggetto query. Questa ha le lettere SQL su di essa. L'editor di form automaticamente crea il codice SQL necessario, sebbene tale codice si presenta in maniera diversa se si esamina il sorgente:
this.CUSTOMER1 = new QUERY()
this.CUSTOMER1.parent = this
with (this.CUSTOMER1)
left = 52.5714
top = 2.5
sql = "select * from customer"
active = true
Endwith
Gli editor impostano automaticamente le proprieta' left e top cosi' che ogni volta che si apre la form l'icona della query si trova nello stesso posto. Quando si esegue la form, l'icona della query non comparira' nella form, essa si vedra' solo in fase di progettazione.
La prima istruzione crea una instanza dell'oggetto query, ma si noti che piuttosto che "CUSTOMER1" si vede "this.CUSTOMER1" -- "this" si riferisce alla form. Si noti anche che la proprieta' parent viene automaticamente assegnata ed ancora "this" si riferisce alla form.
Si potrebbe scrivere lo stesso codice mostrato all'inizio in un modo simile nel proprio programma:
q = new Query()
with( q )
sql = "select * from mytable"
active = true
endwith
Questa scrittura e' valida come la precedente.
Istruzioni SQL SELECT
Se si esamina qualsiasi libro sull' SQL, si trovera' che ci sono molte opzioni che si possono usare con l'istruzione SQL Select.
Come notato sopra, non si deve realmente sapere molto sulle istruzioni SQL Select per usare questi oggetti Dati. Tuttavia, si dovrebbero conoscere un po' di cose, particolarmente se si e' familiari con l'SQL.
La clausola WHERE lavora bene, ma ci sono alcuni avvertimenti.
- L'istruzione SQL deve essere una stringa.
- I numeri devono essere contenuti nella stringa, p.es.:
- query.sql = "select * from parts where part_id > 1"
- Le date devono essere stringhe carattere, nel formato US MM/DD/YY o MM/DD/YYYY -- si noti che questo e' un requisito ANSI SQL, non del Visual dBASE o del BDE.
- query.sql = "select * from parts where date_field = '01/01/1999'"
// or
query.sql = [select * from parts where date_field = ']+date()+[']
Le date vanno racchiuse tra virgolette per differenziarle dalle operazioni matematiche. Questo consente al BDE di sapere che 04/15/1998 e' una data e non il valore 4 diviso il valore 15 diviso il valore 1998.
- I valori Booleani TRUE e FALSE possono essere referenziati sia con le virgolette che senza. La precedente notazione .T. non e' riconosciuta dal BDE quando usata in istruzioni SQL. Si devono usare le parole "TRUE" or "FALSE".
Query a sola lettura
Local SQL (istruzioni SQL usate su tabelle locali ) spesso genereranno queries a sola lettura. Le istruzioni seguenti genereranno queries a sola lettura:
ROWSET
L'oggetto rowset e' il vero cavallo di battaglia degli oggetti Dati in Visual dBASE. La maggior parte delle funzionalita' presenti nei comandi e nelle funzioni DML del vecchio Xbase si trovano ora nelle proprieta', negli eventi e nei metodi dell'oggetto rowset (vedi X2OODML.ZIP).
- La proprieta' autoEdit e' usata per impostare una form in maniera tale che l'utilizzatore possa sempre essere in grado di modificare la riga (record) che e' collegata ai controlli sulla form o per impedire la modifica fino a quando venga effettuata una chiamata esplicita al metodo beginEdit(). Questa e' una facile maniera alternativa per abilitare o disabilitare tutti i controlli presenti in una form.
- La proprieta' className e' una proprieta' a sola lettura e dovrebbe sempre ritornare "ROWSET". Essa puo' essere usata quando ci si muove attraverso la struttura punto. (form.query1.rowset.fields["campo1"].value)
- La proprieta' endOfSet ritorna un valore logico di true se la tabella e' vuota o se il puntatore di riga e' prima della prima riga o dopo l'ultima riga.
- La proprieta' fields e' un array associativo di oggetti che punta agli oggetti campo.
- La proprieta' filter e' usata per filtrare un rowset. Non mescolare questa proprieta' con i metodi applyFilter() e beginFilter() -- si creerebbe solo confusione.
- La proprieta' filterOptions permette di impostare alcune opzioni specifiche relative al filtraggio dei dati -- in particolare se il valore da filtrare deve corrispondere completamente o in parte, come lunghezza, al valore nella tabella, e se il maiuscolo-minuscolo e' importante.
- La proprieta handle e' usata dal BDE ed e' realmente utile solo se si sta lavorando con le API del BDE per esigenze particolari.
- La proprieta' indexName e' usata per impostare l'indice che dovra' essere usato dal rowset.
- La proprieta' live determina se i dati possono essere modificati. (P.es., se questa proprieta' e' posta a false, allora beginEdit() non avra' effetto ...).
- La proprieta' locateOptions e' simile alla proprieta' filterOptions, ma riguarda solo i metodi locate.
- La proprieta' masterFields e' usata per mettere in relazione due tabelle insieme con la proprieta' masterRowset descritta subito dopo. Essa e' descritta con maggiore dettaglio piu' avanti in questo documento.
- La proprieta' masterRowset e' usata con la proprieta' masterFields per mettere in relazione due tabelle. Essa e' descritta con maggiore dettaglio piu' avanti in questo documento.
- La proprieta' modified ritorna un valore logico true o false a seconda se i campi del rowset siano stati modificati o no. Cio' e' utile per determinare se l'utente puo' abbandonare o salvare od effettuare altri lavori.
- La proprieta' notifyControls e' usata per determinare se i controlli datalinkati devono essere aggiornati quando avvengono delle variazioni (navigazione, ecc) nei campi. Nella maggior parte dei casi dovrebbe essere posta a "true", ma ci possono essere delle situazioni, particolarmente nel caso di lunghe elaborazioni, nelle quali si puo' desiderare di porla a "false".
- La proprieta' parent e' un puntatore all'oggetto query che e' il genitore di quel particolare rowset.
- La proprieta' state e' un valore numerico che mostra in quale stato e' il rowset (edit, append, filter, browse, ecc.).
- L'evento canAbandon si attiva quando viene chiamato il metodo abandon() ma prima che si compia qualsiasi azione. Puo' essere usato per eseguire uno specifico codice quando le variazioni ad una riga vengono abbandonate, o per impedire all'utente di abbandonare, per un qualsiasi motivo, le modifiche ad una riga.
- L'evento canAppend si attiva prima che l'utente aggiunga una nuova riga. Puo' essere usato per eseguire del codice o per impedire all'utente di aggiungere una nuova riga.
- L'evento canDelete si attiva prima che il metodo delete cancelli una riga. Puo' essere usato per eseguire uno specifico codice o per impedire all'utente di cancellare una riga.
- L'evento canEdit si attiva quando viene chiamato il metodo beginEdit(), e puo' essere usato per eseguire uno specifico codice o per impedire all'utente la modifica di una riga.
- L'evento canGetRow si attiva quando la query sta esaminando le righe da visualizzare. Questo include la visualizzazione in un browse,ecc. L'effetto di questo evento e' di fornire un altro livello di filtro per la propria tabella.
- L'evento canNavigate si attiva quando avviene un qualsiasi tentativo di navigazione (next(), first(), last(), goto() ...). Puo' essere usato per non permettere la navigazione nella tabella o per eseguire del codice prima della navigazione.
- L'evento canSave si attiva quando viene chiamato il metodo save(), e puo' essere usato per eseguire uno specifico codice e/o impedire all'utente di salvare le variazioni ad una riga.
- L'evento onAbandon scatta dopo un "abandon" coronato da successo.
- L'evento onAppend scatta dopo un append riuscito. Questo e' un buon posto per impostare i valori di default per i campi, nel caso in cui non si usino delle proprieta' custom per tali campi.
- L'evento onDelete si attiva dopo la cancellazione di una riga.
- L'evento onEdit si attiva dopo una chiamata riuscita al metodo beginEdit().
- L'evento onNavigate scatta dopo una navigazione nella tabella.
- L'evento onSave scatta dopo un salvataggio riuscito del rowset.
- Il metodo abandon causera' un aggiornamento del buffer del record con i dati conservati nella tabella, distruggendo cosi' qualsiasi variazione effettuata dall'utente.
- Il metodo applyFilter attiva un filtro creato sia mediante un filter-by-form o mediante un filtro a programma iniziato con un beginFilter().
- Il metodo applyLocate inizia una ricerca basata su specifici criteri, sia con un locate-by-form che con una richiesta a programma. Il metodo puo' essere chiamato con o senza un beginLocate(). Una chiamata a locateNext() continuera' la ricerca. Se non viene trovato nessun record con i criteri specificati il puntatore di riga andra' a endOfSet.
- Il metodo atFirst ritorna un valore logico true/false a seconda che la riga corrente sia o no la prima riga del rowset.
- Il metodo atLast ritorna un valore logico true/false a seconda che la riga corrente sia o no l'ultima riga del rowset.
- Il metodo beginAppend crea un buffer vuoto per il record, e se il buffer viene salvato, crea una nuova riga nella tabella conservando i valori del buffer nei campi. Se viene effettuata una chiamata al metodo abandon(), allora il buffer viene pulito e ripristinata la riga della tabella alla quale si puntava prima che fosse chiamato il metodo beginAppend.
- Il metodo beginEdit copia i dati della riga corrente in un buffer. Se viene chiamato il metodo save() del rowset, allora le variazioni effettuate vengono salvate nella tabella; se invece viene chiamato il metodo abandon() del rowset, allora il buffer viene pulito e i dati originali ripristinati.
- Il metodo beginFilter puo' essere usato per mettere la form nella modalita' filter-by-form, e puo' essere usato anche per assegnare a programma i valori per filtrare il rowset. Una volta che e' chiamato l' applyFilter() del rowset, allora se qualche riga rispetta le condizioni poste, solo queste righe verranno visualizzate, fino a quando viene chiamato un clearFilter().
- Il metodo beginLocate puo' essere usato per mettere la form in modalita' locate-by-form, o puo' essere usato a programma per assegnare i valori per una ricerca all'interno di una tabella. Una volta che viene chiamato il metodo applyLocate() del rowset, la ricerca iniziera'. (vedi applyLocate per maggiori informazioni.)
- Il metodo bookmark e' usato per ottenere il bookmark della riga corrente. Esso puo' essere usato col metodo goto() per ritornare ad una riga. Avvertenza: se si cambia l'indice il bookmark non e' piu' valido.
- Il metodo bookmarksEqual e' usato per confrontare bookmarks.
- Il metodo clearFilter cancella qualsiasi filtro impostato sia con i metodi beginFilter()/applyFilter() che con la proprieta' filter del rowset. Questo ha l'effetto di ristabilire il rowset senza il filtro.
- Il metodo clearRange e' usato per annullare le condizioni di range impostate con setRange()
- Il metodo count ritorna il numero di righe nel rowset. Questo metodo rispetta tutti i filtri e dovrebbe anche rispettare i risultati se si usa canGetRow().
- Il metodo delete imposta il flag di cancellazione in un .DBF, o per altri tipi di file cancella fisicamente la riga. Si noti che l'OODML non rispetta il "Soft Delete" dell' XBase DML -- se si cancella una riga, pur essendo fisicamente presente, essa a tutti gli effetti non e' piu' recuperabile. (Per maggiori dettagli si veda X2OODML.ZIP nel sito web dell'autore.)
- Il metodo findKey compie una veloce ricerca nella tabella usando l'indice attivo (attraverso la proprieta indexName).
- Il metodo findKeyNearest agisce come findKey, ma funziona come se il comando XBase DML SET NEAR e' "ON".
- Il metodo first muove il puntatore di riga alla prima riga del rowset.
- Il metodo flush salva il buffer del rowset sul disco.
- Il metodo goto muove il puntatore di riga al bookmark specificato (vedi bookmark() sopra).
- Il metodo last muove il puntatore di riga all'ultima riga del rowset.
- Il metodo locateNext usa i criteri specificati con applyLocate(), e continua dalla posizione corrente nella tabella tentando di trovare la successiva corrispondenza. Se nessuna corrispondenza viene trovata il puntatore di riga va a endOfSet.
- Il metodo lockRow blocca la riga corrente cosicche' nessuno oltre all'utente corrente possa modificare quella riga. Nella maggior parte delle situazioni cio' non e' necessario, poiche' dBase gestisce automaticamente i blocchi.
- Il lockSet blocca il rowset come sopra.
- Il metodo next muove il puntatore di riga alla riga successiva. Esso puo' prendere un parametro che indica semplicemente di quante righe ci si muove. Se viene passato un valore negativo, il metodo muovera' il puntatore di riga indietro di un numero di righe pari a tale valore (p.es., next( -1 ) -- muovera' il puntatore verso l'inizio del rowset).
- Il metodo refresh e' usato per aggiornare il rowset dal disco. Vedi l'aiuto in linea per dettagli. Non e' normalmente necessario chiamare tale metodo.
- Il metodo refreshControls e' usato per forzare un aggiornamento dei controlli che sono datalinkati ai campi nella riga corrente.
- Il metodo refreshRow funziona come refresh(), ma agisce solo sulla riga corrente.
- Il metodo rowCount potrebbe ritornare un valore utile, ma puo' anche non ritornarlo. Esso e' progettato per lavorare con un "rowset logico" che un .DBF in realta' non crea. Se il valore e' indefinito questo metodo ritorna -1.(E' preferibile probabilmente usare count()....)
- Il metodo rowNo ritorna il numero logico di riga nel rowset. Si noti che i .DBF non lavorano con rowset logici e quindi i risultati non saranno consistenti.
- Il metodo save salva il buffer della riga su disco.
- Il metodo setRange e' usato per limitare i valori esistenti nel rowset. Esso usa l'espressione dell'indice attivo.
- Il metodo unlock sblocca qualsiasi blocco effettuato con lockRow() e/o lockSet().
Wow! C'e' molta carne al fuoco! Il problema e' che si e' dato appena un rapido sguardo e ci si puo' chiedere come si usi tutto cio'. Non si disperi, si copriranno alcuni aspetti in maggior dettaglio e vi sono altri esempi sia nei documenti HOW TO nel sito dell'autore che nell'aiuto in linea...Perora si stanno soltanto guardando le varie componenti, piu' tardi si cerchera' di metterle assieme.
Piuttosto che spendere del tempo nel tentativo di manipolare ora il rowset, concludiamo l'esame degli altri oggetti dati....
INDEX
L'oggetto indice, che e' sfortunatamente non documentato nell'aiuto in linea, da' la possibilita' di creare indici con il linguaggio OODML. Vi sono in realta' due differenti oggetti indice, uno dei quali e' una sottoclasse dell'altro. L'oggetto indice primario e' chiamato INDEX, l'altro e' chiamato DBFINDEX, quest'ultimo e' specificatamente usato per il formato di tabella .DBF. Ci sono piccole differenze fra i due. Si iniziera' con l'oggetto INDICE ed esamineremo le sue proprieta' e quindi si noteranno le differenze fra INDEX e DBFINDEX.
- La proprieta' caseSensitive e' equivalente allo standard MDX in un indice DBF, che e' per default, sensibile al Maiuscolo/Minuscolo. Si puo' impostare questa proprieta' a true o false.
- La proprieta' className e' una proprieta' a sola lettura ,"INDEX", come il nome della classe , o "DBFINDEX" per l'altro oggetto.
- La proprieta' descending determina se l'espressione per l'indice e' in sequenza discendente.
- La proprieta' fields e' l'equivalente di un'espressione per un indice -- vale a dire su quali campi si sta indicizzando. Nella maggior parte dei databases si possono solo definire campi e non espressioni per l'indice.
- La proprieta' indexName contiene il nome dell'indice.
- La proprieta' parent e' una standard proprieta' "parent" utile se si decide di contenere l'oggetto indice in qualche altro oggetto (come un rowset o una form).
- La proprieta' unique determina se l'indice conserva solo valori unici o tutte le righe nella tabella.
- DBFIndex ha le seguenti proprieta':
- La proprieta' className e' a sola lettura e restituisce "DBFINDEX" come nome della classe.
- La proprieta' descending determina se l'espressione usata per l'indice e' in sequenza discendente.
- La proprieta' expression e' una espressione standard che puo' includere nomi di campo, funzioni dBASE e cosi' via. E' vitale che si capisca che per tabelle DBF7 (il nuovo formato di tabella) non si possono usare funzioni definite dall'utente nelle proprie espressioni.Tuttavia si puo' ancora usare UPPER() e cosi' via ...
- La proprieta' forExpression e' equivalente alla clausola XDML "FOR" del comando INDEX. Si possono cosi' limitare le righe realmente indicizzate sulla base di una espressione condizionale. Vedi "expression" per i limiti..
- La proprieta' indexName contiene il nome dell'indice.
- La proprieta' parent e' una standard proprieta' "parent" utile se si decide di contenere l'oggetto indice in qualche altro oggetto (come un rowset o una form).
- La proprieta' type vale "0" per MDX, o "1" per NDX. Da notare che l'OODML permette di creare un file .NDX file, ma in realta' non ne permette l'uso. La sola maniera di usare un .NDX e' con l'XDML.
- La proprieta' unique determina se l'indice conserva solo valori unici o tutte le righe con uguale indice nella tabella.
- Come si puo' vedere i due oggetti indice sono molto simili, ma non completamente identici. Questo perche' gli indici dBase sono sempre stati un po' piu' flessibili della maggior parte degli indici SQL Server.
Per definire un indice .DBF e quindi crearlo, si deve operare nella maniera seguente:
i = new DBFIndex()
i.indexName := "MioIndice"
i.expression := "field1 + upper(field2)"
// un'altra caratteristica non documentata:
_app.databases[1].createIndex( "NomeTabella", i )
Questo e' realmente tutto cio' che e' richiesto. Se si vuol fare qualcosa di piu' si deve impostare il tipo a 1 per .NDX (da notare, tuttavia, che l'OODML non sa come gestire un file .NDX ), si puo' impostare la proprieta' unique a true, la proprieta' descending a true e cosi' via. Si ricorda che l'espressione per l'indice deve essere corretta.
Qualcosa in piu' sulle espressioni
Per il momento si assume che si sta lavorando con .DBF, poiche' tale tipo di files e' quello nativo per il Dbase. Si discuteranno brevemente un po' di cose.
Indici numerici
Definire indici numerici non e' generalmente una buona idea. Nella maggior parte dei casi si dovrebbe indicizzare su stringhe di caratteri. "La maggior parte dei campi chiave sono essenzialmente caratteri, anche se essi contengono dei numeri. Per esempio, numeri di telefono, CAP , partite IVA non hanno niente di numerico. Una buona maniera di procedere e' che se non si devono effettuare calcoli aritmetici con essi, tali campi dovrebbero essere caratteri." -- Gary Thoenen [dBVIPS]
Date
La gestione delle date puo' essere interessante. Se si stanno usando date nel formato Americano MM/DD/YYYY, e si imposta un indice sulla data "cosi' come e' " , cosa capitera' se si hanno date che coprono diversi anni ? L' ordinamento sara' effettuato per mese, piuttosto che per anno e per mese.
Posiamo allora impostare il formato della data a YY/MM/DD, che e' piu' logico (Anno, Mese, Giorno).Cosa capitera' allora quando arrivera' l'anno 2000 ? Tutte le date relative all'anno 2000 appariranno nell'indice prima dell'anno 1999. Questo non e' probabilmente una cosa desiderabile. La maniera migliore di procedere per indicizzare le date e' di usare la funzione DTOS. DTOS() ritorna date come una stringa di caratteri nel formato YYYYMMDD (senza barre).
La cosa interessante e' che questo stratagemma funziona con tutti i formati internazionali di data.
Lunghezza delle espressioni
La lunghezza massima di una espressione puo' essere di 100 caratteri, ma questa e' realmente una espressione troppo lunga. Se si sta lavorando con campi multipli e si combinano in una espressione che e' piu' lunga di 100 caratteri, Dbase non la considerera'. Come aggirare il problema ? Si usi la funzione left() per estrarre da ciascun campo una parte tale da ottenere valori unici di chiave e tutto lavorera' perfettamente. Se per esempio si sta lavorando con una collezione di CD, molti titoli di album sono piuttosto lunghi (uno che mi passa per la mente e "I Miti e le Leggende di Re Artu' e dei Cavalieri della Tavola Rotonda" di Rick Wakeman..). Si puo' desiderare di avere un indice sul nome dell'artista e quindi sul titolo dell'album. Ma se il campo artista e' diciamo, 40 caratteri, ed il campo titolo e' 100, si possono avere dei problemi. Per creare una espressione relativa a questo indice, si puo' probabilmente prendere l'intero nome dell'artista e quindi solo i primi 40 caratteri (o meno) del titolo:
i.expression := artista+left( titolo, 40 )
Dipendenza dal Maiuscolo/Minuscolo
Le espressioni di indice DBF sono sempre stati sensibili al Maiuscolo/Minuscolo. Non si sa mai quello che un utente fara' con tuo programma. La maniera' piu' sicura di costruire con una espressione e di crearla non dipendente dal Maiuscolo/Minuscolo. Come ottenere cio'? Si indicizzi su una stringa di caratteri MAIUSCOLI e si abbia la certezza che le procedure di ricerca convertino in maiuscolo i valori inseriti dall'utente. Per creare un'espressione , si deve usare:
i.expression := upper( artista+left( titolo, 40 ) )
Come ottenere informazioni sulle etichette degli indici.
Non e' facile ottenere informazioni attorno ai propri indici, a meno che non si usi il non documentato oggetto TableDef.
Questo argomento e' coperto in dettaglio nel documento dell'autore presentato a Icon98 sulle Undocumented Features al suo sito web.
Miscellanea
Si tenga presente che piu' etichette di indici si hanno in una tabella, piu' tempo e' necessario per aggiornare una tabella, includendo l'aggiunta di nuove righe, la modifica di righe (specialmente se all'utente e' permesso di modificare campi usati nelle espressioni delle proprie etichette di indici) e cosi' via. Se si effettuano variazioni a programma alle proprie tabelle, la situazione puo' peggiorare. Ci sono delle maniere per aggirare questi problemi, ma non verranno per il momento prese in considerazione.
Vi sono maggiori informazioni sugli indici nel documento presentato dall'autore a Icon98 su Undocumented Features e disponibile nel suo sito web...
ARRAY DI CAMPI
Questo e' un argomento davvero semplice. L'array di campi e' un array che e' contenuto dal rowset e contiene i puntatori agli oggetti campo per il rowset. Che cosa si puo' fare con un array di campi? Ebbene, l'array di campi permette di individuare i campi. Si possono aggiungere o cancellare campi nell'array di campi (utile per campi calcolati, un argomento che si trattera' successivamente). Si puo' anche sapere quanti campi vi sono nell'array di campi. Non c'e' molto altro. Ecco una lista delle proprieta' e dei metodi.
- La proprieta' className e' la stringa "FIELDARRAY" - utile quando ci si muove attraverso la sintassi punto (gli daremo un'occhiata piu' avanti).
- La proprieta' parent e' un puntatore al rowset che contiene l'array di campi.
- La proprieta' size contiene il numero di campi nell'array di campi.
- Il metodo add permette di aggiungere campi all'array di campi.
- Il metodo delete permette di togliere campi dall'array di campi.
- Come notato, tutto cio' e' abbastanza semplice. La cosa piu' importante e' che questo e' un array associativo, il che significa che si puo' selezionare un campo sia attraverso un numero (la sua posizione nella lista) sia attraverso il suo nome. Per trovare il valore di un campo si puo' fare cosi':
? form.rowset.fields[ 1 ].value
// or
? form.rowset.fields[ "fieldName" ].value
Piuttosto che spendere molto tempo su quest'argomento, diamo un'occhiata all'oggetto campo.C'e' molto da vedere li'...
FIELD
L'oggetto FIELD e' usato per consentire l'accesso a campi individuali in una tabella e lavorare con proprieta', eventi e metodi per modificare il comportamento ed il valore del campo. Ci sono in realta' differenti tipi di oggetti FIELD. I primi due tipi sono sottoclassi dell'oggetto FIELD principale. Se si sta lavorando con un .DBF, allora automaticamente si sta usando un DBFFIELD, o, nel caso di una tabella che e' stata convertita (usando il comando Xbase CONVERT per aggiungere il campo _DBASELOCK) si avra' un LOCKFIELD. Si possono incontrare anche i tipi di campo PDXFIELD e/o SQLFIELD, ciascuno dei quali ha proprieta' specifiche per quel tipo di campo.
Di seguito sono enumerate tutte le proprieta' dei campi, e se non sono comuni alla classe FIELD, viene data una nota per quel tipo di campo.
- La proprieta' className e' a sola lettura e mostrera' il nome della sottoclasse dell'oggetto campo.(p.es., DBFFIELD, PDXFIELD, etc.).
- La proprieta' decimalLength si trova solo in DBFFIELD, ed e' il numero di posti decimali di un campo numerico.
- La proprieta' default e' propria solo di DBFFIELD o PDXFIELD. E' il valore di default quando si aggiunge una nuova riga ad una tabella. Questo valore puo' essere inserito solo in fase di impostazione della tabella.
- La proprieta' fieldName indica il nome del campo.
- La proprieta' length e' la lunghezza in caratteri del campo.
- La proprieta' lookupRowset fornisce un riferimento al rowset restituito quando si usa la proprieta' lookupSQL.
- La proprieta' lookupSQL e' una istruzione SQL usata per generare un lookupRowset. Questa e' una utilissima caratteristica che sara' contemplata in maggiore profondita' piu' avanti in questo documento.
- La proprieta' lookupTable e' una proprieta' solo di un campo PDXFIELD che punta alla tabella usata nel lookup per il lookupType.
- La proprieta' lookupType e' una proprieta' solo di un campo PDXFIELD che definisce il lookup usando la lookupTable (definita sopra).
- La proprieta' maximum e' una proprieta' solo delle sottoclassi DBFFIELD o PDXFIELD -- e' una "costrizione" -- si puo' impostare il valore massimo in questa proprieta' in fase di impostazione della tabella e se l'utente tenta di inserire un valore più grande avverra' un errore.
- La proprieta' minimum e' una proprieta' solo di DBFFIELD or PDXFIELD che lavora come la proprieta' maximum di sopra.
- La proprieta' parent e' usata per fornire un riferimento all'array di campi.
- La proprieta' picture e' una proprieta' solo di PDXFIELD usata per fornire un modello per la visualizzazione del campo.
- La proprieta' precision e' una proprieta' solo di SQLFIELD che fornisce il numero di cifre di precisione.
- La proprieta' readOnly e' una proprieta' solo di DBFFIELD o PDXFIELD che permette di impostare un campo a sola lettura.
- La proprieta' required e' una proprieta' solo di DBFFIELD or PDXFIELD usata per determinare se questo campo puo' o non essere lasciato vuoto (null). Questa proprieta' puo' solo essere impostata in fase di progettazione della tabella.
- La proprieta' scale e' una proprieta' solo di SQLFIELD che determina in che scala e' un numero.
- La proprieta' type e' un valore carattere che visualizza il tipo di campo (CARATTERE, NUMERICO, AUTOINCREMENTO, ecc.).
- La proprieta' value e' un riferimento al valore reale conservato nel campo.
- L'evento beforeGetValue si attiva quando viene effettuato un tentativo di ottenere un valore da una tabella. Esso puo' essere usato per far si' che il valore di un campo appaia in qualsiasi maniera si desideri (il termine "morphing" e' qualche volta usato per questo), ed e' usato quando si creano campi calcolati.
- L'evento canChange si attiva quando viene fatto un tentativo di cambiare la proprieta' value del campo. Se questo evento ritorna "false" allora il valore non puo' essere cambiato.
- L'evento onChange si attiva dopo che la proprieta' valore e' cambiata.
- L'evento onGotValue si attiva dopo che il valore viene letto (vedi beforeGetValue).
- Il metodo copyToFile viene usato per copiare i contenuti di un campo binario (memo,ole...) sul disco.
- Il metodo replaceFromFile e' usato per recuperare il contenuto di un file e conservarlo in un campo binario.
Si ha fiducia a questo punto nel fatto che le varie parti si stanno riunendo. O avviene questo o i propri occhi si stanno trasformando in gelatina. Se quest'ultimo e' il caso ci si allontani dal computer per un po',quest'ultimo tanto rimarra' dov'e'.
Primi passi con gli Oggetti Dati
Ora che abbiamo esaminato gli oggetti Dati piu' importanti in Visual Dbase 7 cerchiamo di usarli un po'. Questo documento non puo' probabilmente coprire ogni singola caso nel quale lo sviluppatore puo' imbattersi quando usa una specifica funzionalita'. Tuttavia con un po' di fortuna posso ottenere almeno il risultato che egli ci rifletta su....
La maggior parte di quanto segue assume che si stanno usando forms (e/o reports, le idee sono per buona parte uguali) e cosi' la sintassi per i comandi indicati presupporra' forms, o in molti casi l'evento onClick dei controlli pushbutton su forms. Si tenga presente che lo stesso tipo di cose puo' essere effettuato tramite programma.
Come usare una Tabella in una form
Dopo tutta questa babele di informazioni, sicuramente si ha l'impressione che cio' che si sta andando a fare sia complicato, non e' cosi'?
Cio' che segue e' valido per i reports e le etichette cosi' come per le forms.
In realta' non potrebbe essere piu' semplice. Per usare una tabella su una form, il metodo piu' semplice e' di aprire una nuova form nell'editor di form, cliccare sul Centro di Controllo in Visual dBase 7, cliccare su "Tabelle", e trascinare la propria tabella sulla superficie dell'editor di form.
Avverra' che dBase porra' un'icona sulla superficie della form, che e' usata per rappresentare un oggetto non-visuale (quando la form viene eseguita, l'utente non vedra' quest'oggetto). L'icona avra' le lettere "SQL" su di essa --- questo e' un oggetto query. In piu' posizionando l'icona sulla superficie dell'editor dBase impostera' la proprieta' SQL, e la proprieta' active verra' posta per default a "true".
Se si sta usando un Alias BDE, si avra', oltre all'oggetto query, anche un oggetto database.
L'editor di form automaticamente effettuera' le corrette connessioni fra l'oggetto database e l'oggetto query.
Se si ha bisogno di qualcosa di piu', come impostare un'espressione di indice affinche' sia l'indice principale, e' necessario effettuare un "drill down" nell'Ispezione. Si clicchi sull'icona SQL della tabella ed in Ispezione, si clicchi sulla parola "rowset". Si vedra' "Oggetto" nella seconda colonna ed avra' un pulsante con la lettera "I" ("Inspect") su di esso. Si clicchi sulla I. Ora si vedra' l'oggetto rowset associato con la query. Si clicchi sulla proprieta' "indexName" e si selezioni l'etichetta dell'indice che si desidera usare. Tutto cio' e' abbastanza facile.
Cliccando sulla "I" di fields si vedra' normalmente una tavolozza di "campi". Se non e' cosi' si clicchi col pulsante destro sulla superficie di progettazione della form e si selezioni "Tavolozza di Campi". Cosi' si visualizzeranno i campi della propria tabella. Essi possono essere trascinati, se si vuole, direttamente sulla superficie di progettazione....
L'inizio e' abbastanza facile, eh? C'e' molto di piu', ma qui non c'e' molto spazio per andare in dettaglio. L'autore tentera' di creare un tutorial, in un prossimo futuro, su come creare un'applicazione e una buona parte di esso sara' speso nella creazione delle forms... Tuttavia, nel frattempo, si possono consultare "CONTROLS.ZIP", "CUSTCTRL.ZIP", "GRID.ZIP", ed altri HOW TO a loro collegati nel sito web dell'autore.
Una cosa che e' importante notare e' che la form stessa ha una proprieta' chiamata "rowset". dBASE automaticamente inserisce un riferimento alla prima query posta sulla form in questa proprieta' della form.
Navigando attraverso le Tabelle
Una volta che si ha una tabella su una form, e presumibilmente alcuni controlli per i campi, si dovra', perlomeno, permettere all'utente di navigare attraverso la tabella.
Se si e' posti la proprieta' indexName dell'oggetto rowset, la tabella sara' percorsa sulla base della sequenza prevista dall'espressione dell'indice.
La navigazione e' effettuata attraverso i metodi del rowset che sono stati gia' discussi nella sezione relativa al rowset di questo documento. Vi sono alcune cose che si dovrebbero osservare:
- Se l'utente modifica i dati, e quindi scorre la tabella (Naviga), le variazioni ai dati sono automaticamente salvate.La sola maniera per evitare il salvataggio e' che l'utente "abbandoni" le variazioni.
- Alcuni metodi ed eventi del rowset causano una navigazione che puo' essere inaspettata:
- La navigazione standard : i metodi first(), last(), next(), goto() naturalmente causeranno una navigazione.
- filter, applyFilter(), applyLocate(), findKey(), findKeyNearest(), setRange() causeranno una navigazione e salveranno le variazioni al rowset.
- Una cosa che e' davvero utile e' che gli esempi che arrivano col Visual dBase includono alcune routines per gestire la navigazione attraverso una tabella (esse sono incluse nel file CUSTOM\DATABUTTONS.CC). In piu' l'autore ha espanso un po' le capacita' di questi pulsanti e ha creato un proprio set, che puo' essere trovato nella libreria dUFLP (nel sito dell'autore) nel file CUSTBUTT.CC.
Se si decide di scrivere da se' il codice per la navigazione nella tabella, vi sono alcune cose da considerare:
- Non permettere che l'utente navighi aldila' del primo o dell'ultimo record del rowset -- altrimenti avverranno degli errori. La maniera migliore di gestire questo caso e' di controllare i metodi atFirst() o atLast() del rowset prima di permettere la navigazione...si puo' astutamente abilitare o disabilitare i pulsanti, o semplicemente mostrare un msgbox() che indichi che l'utente non puo' effettuare una determinata azione.
- E' probabilmente una buona idea non permettere all'utente la navigazione se si sta aggiungendo o modificando una riga, poiche' la variazioni saranno salvate automaticamente. Cio' puo' essere fatto controllando la proprieta' STATE del rowset.
Modifica
Si puo' impostare un rowset affinche' non sia modificabile fino a quando l'utente non decida esplicitamente di voler effettuare una modifica (Io trovo che questa sia una buona idea -- e' davvero facile variare accidentalmente qualcosa...) Cambiando la proprieta' del rowset autoEdit a false (per default e' true). Questo ha l'effetto di disabilitare tutti i controlli che sono dataLinkati ai campi del rowset.
Se si decide di usare la proprieta' autoEdit a false, allora si dovra' fornire una maniera all'utente di modificare la riga corrente. Questo puo' essere fatto con:
form.rowset.beginEdit()
e tale codice puo' essere posto nell'evento onClick di un pulsante.
Si dovrebbe anche fornire una opzione "save" e una "cancel" per chiamare i metodi save() ed abandon() del rowset.
Un problema che arriva con i Comboboxes ...
Se si usa questo metodo per disabilitare i controlli, il combobox sembra attivo anche quando non lo e'. L'utente puo' selezionare un nuovo valore, e sembra che questo valore modifichi la riga, fino a quando l'utente non passi ad un'altra riga o non vada in modalita' edit (od effettui qualsiasi altra azione che aggiorni i controlli datalinkati dei valori nei campi).
Cio' puo' essere sconcertante. Tuttavia Gary White ha fornito la seguente soluzione per questo problema. Bisogna inserire il seguente codice negli eventi onGotFocus e onChange per il combobox:
function combobox1_onGotFocus
this.savedValue = this.value
return
E nell'evento onChange:
function combobox1_onChange
// this = combobox
// datalink = field
// parent = field array
// parent = rowset
if this.datalink.parent.parent.state == 1
this.value = this.savedValue
endif
return
Si noti che affinche' il tutto funzioni si devono usare entrambi questi eventi. (Si puo' anche aggiungere dell'altro codice nell'evento onChange, si deve soltanto mantenere il codice sopra riportato... magari aggiungendo un 'return' prima dell'istruzione endif).
Un problema simile che arriva con gli Editors....
Il controllo editor e' anche peggiore sotto quest'aspetto, poiche' esso ignorera' lo stato del rowset.
Tuttavia Gary White ci fornisce, anche in questo caso, il seguente fix...
function key
/*
Questo codice di Gary White e' finalizzato all'aggiramento
di un problema con i rowset che hanno la proprieta'
autoEdit posta a false, e gli editors. L'editor sembra immune
a questa proprieta' del rowset ed i suoi contenuti possono
essere modificati qualunque sia lo stato del rowset...
*/
// this = editor
// dataLink = field
// parent = fieldArray
// parent = rowset
if type( "this.datalink.parent.parent" ) # "U"
r = this.datalink.parent.parent
if r.autoEdit == false and ;
( r.state # 2 and r.state # 3 )
return 0
endif
endif
Cancellazione di righe
L'OODML non supporta il "soft delete" Xbase (fondamentelmente questa e' la capacita' di continuare a mostrare una riga cancellata sulla form) direttamente. E' possibile fare cio' attraverso le API del BDE e c'e' un esempio di questo in "X2OODML.ZIP" nel sito web dell'autore (e nella libreria dUFLP nello stesso sito).
La ragione di cio' sta nel fatto che .DBF e' la sola tabella che permette questa funzionalita' -- tutte le altre assumono che una riga cancellata non sia piu' presente. Niente paura, tuttavia: se l'utente decide di cancellare una riga essa e' ancora nella tabella, ma non la si puo' mostrare all'utente, e non si puo' (usando l'OODML) permettere all'utente di richiamare (undelete) quella riga.
Come trovare delle righe in una Tabella
Vi sono diverse maniere di "trovare" righe in una tabella. Si puo'usare "findkey" e/o findKeyNearest()", si puo' usare "beginLocate()" e "applyLocate()", e molto di piu'. Tutto cio' e' discusso in "MISCCODE.ZIP" nel sito web dell'autore in maggiore dettaglio.
Come filtrare delle righe in una Tabella
Cosi' come "trovare" delle righe, vi sono diverse maniere di filtrare delle righe in una tabella, includendo la proprieta' "filter" del rowset, i metodi "beginFilter()" e "applyFilter()", il metodo "setRange()" e l'evento "canGetRow" del rowset. Tutto cio' e' discusso in "MISCCODE.ZIP" nel sito web dell'autore in maggiore dettaglio.
Tabelle collegate
Nelle precedenti versioni di dBase si sono usati diversi comandi per impostare relazioni
(SET RELATION, SET SKIP ...). Nell'OODML di Visual dBASE 7's OODML questo e' stato reso piu' semplice. Vi e' una discussione abbastanza estesa di cio' nel documento "MISCCODE.ZIP" HOW TO nel sito web dell'autore.
Campi calcolati
I campi calcolati sono piuttosto importanti in un gran numero di applicazioni.. Essi sono semplici campi che visualizzano un calcolo o un valore non presente nella tabella per l'utente (qualcuno pensa che un campo calcolato sia specificatamente finalizzato ai calcoli matematici, invece la combinazione di due campi in uno e' considerato un campo calcolato ed ottenere un valore da un lookupRowset e' un campo calcolato). L'utente non puo' direttamente agire con loro, poiche' essi sono, per loro natura, campi a sola lettura- essi non sono direttamente collegati ad una tabella. (L'utente puo' in realta' modificare tali campi a meno che non imposti la proprieta' ReadOnly sul campo, ma tale modica non si riflettera' sulla tabella stessa...)
Per creare un campo calcolato si deve creare un'istanza di un campo oggetto, impostare alcune proprieta' (come discusso sotto), e quindi aggiungere il campo all'array di campi per il rowset. Se impostato nella maniera opportuna, poiche' l'utente naviga attraverso la tabella, questo campo sara' calcolato (usando l'evento beforeGetValue) e i risultati si visualizzeranno sulla form o sul report di stampa.
Il seguente e' un semplice esempio di come si crea un campo calcolato per visualizzare il " nome completo" partendo dai campi nome e cognome nella tabella. Si tenga a mente che qualsiasi espressione valida per il Visual dBase funzionera'. Questo esempio assume che il campo oggetto venga aggiunto in un evento canOpen o onOpen della query.
// istanziazione dell'oggetto campo
f = new Field()
f.fieldName := "Full Name"
f.readOnly := true
// "this" nella seguente istruzione si riferisce
// all'oggetto campo (importante informazione)
f.beforeGetValue := {|| trim( this.parent["first name"].value ) + " " +this.parent["last name"].value }
// "this" nella seguente istruzione si riferisce alla query:
this.rowset.fields.add( f )
E' davvero importante che si usi l'evento beforeGetValue per eseguire realmente il calcolo, o il valore non si aggiornera' quando si naviga attraverso la tabella. Se si assegna invece la proprieta' "value", tale valore verra' visualizzato solo per la prima riga visualizzata e non si aggiornera' quando si naviga fra i records.
Si possono avere vari campi calcolati per un rowset e si deve solo cercare di essere sicuri che ciascuno abbia una proprieta' fieldName unica.
TableDef
L'oggetto tableDef e' una risorsa non documentata del Visual Dbase 7. Esso e' estremamente utile, in quanto puo' visualizzare informazioni su una tabella, sugli indici di una tabella, sui campi di una tabella e su qualsiasi vincolo definito nella tabella.(Tuttavia, non si puo' scrivere nessuna di queste informazioni usando tableDef).
Piuttosto che duplicare informazioni gia' scritte, si dovrebbe esaminare il documento di Icon98 su Undocumented Features nel sito web dell'autore. Questo particolare oggetto e' descritto in maniera estesa, con esempi di codice e piu' in quel documento.
UpdateSet
L'oggetto UpdateSet in Visual dBASE e' utile per effettuare aggiornamenti di gruppo (batch) alle tabelle e/o copiare tabelle da un formato ad un altro. Per maggiori dettagli sull'oggetto UpdateSet, si veda "MISCCODE.ZIP" nel sito web dell'autore. In tale documento l' argomento e' coperto in dettaglio ed e' piu' facile effettuare dei riferimenti a quel documento che cercare di mantenere informazioni duplicate in diversi posti.
DataModules
Un DataModule e' un oggetto speciale in Visual Dbase. Esso e' un contenitore per oggetti Dati. Il suo scopo principale e' di migliorare il modello ad oggetti e le possibilita' di "riusabilita' del codice" per una migliore programmazione orientata agli oggetti.
L'importanza di un datamodule sta nel fatto che si possono impostare le proprie tabelle e qualsiasi codice si desidera impostare per quelle tabelle in un datamodule, e usare tutto quel codice senza dover ricrearlo per ciascuna form o report.
Si puo' anche avere un datamodule custom, che permette di creare delle sottoclassi partendo da uno schema standard di dati e usare tali sottoclassi per le proprie mappe reali (con specifiche modifiche nei datamoduli derivati) e cosi' via.
(Un esempio di cio' potrebbe essere quello di impostare il proprio database o anche un oggetto sessione in un datamodule custom, e quindi derivare altri datamoduli da quello senza dover impostare nuovamente la propria sessione e gli oggetti dati!)
Questo documento ha gia' raggiunto una certa lunghezza, e piuttosto che spendere molto tempo spiegando in dettaglio i datamoduli, preferisco parlarne in qualche situazione dove si lavora con piu' di una tabella o si sta impostando del codice abbastanza complesso (come per esempio un evento canAppend o simili) ed e' molto meglio usare un datamodule ed incapsulare tutto il codice in esso, cosi' se e' necessario usarlo in un'altra form, si puo' risparmiare una gran quantita' di lavoro. Usa molto i datamoduli. Essi renderanno la tua vita di sviluppatore molto piu' facile.
Una nota, tuttavia, per aiutare nell'uso dei datamoduli:
Un datamodule non sa che cosa e' una "form" (o un report), cosi' come gli altri oggetti data non sanno che cosa e' una "form". Questo significa che non si puo' usare codice come il seguente dentro un datamodule ( si otterra' un errore del tipo "form" non trovata o qualcosa di questo tipo):
form.entryfield1.value := "myvalue"
Quando si inserisce un datamodule in una form, si sta in realta' ponendo un oggetto "datamodRef" nella form, che ha una proprieta' "ref ", che punta al datamodule reale. La ragione di cio' sta nel fatto che si puo' usare lo stesso datamodule, nello stesso tempo, su multiple form (o reports) -- come puo' il datamodule stesso sapere quale form o report e' il suo "parent" ? Se ci si riferisce a "form" nel datamodule come potrebbe quest'ultimo sapere quale form (o report) si intende?
E' difficile abituarsi a questa cosa, giacche' la maggior parte degli oggetti contenuti in una form o report capiscono a che cosa essi appartengono.
E' possibile, sebbene non sia una buona idea, riferirsi all'entryfield di una form da dentro un rowset contenuto da una query, contenuto da un datamodule, con queste linee:
// this = rowset
// parent1 = query
// parent2 = datamodule
// parent3 = connector (si veda OODML.HOW di A.Katz - N.d.T.)
// parent4 = form
this.parent.parent.parent.parent.entryfield1.value ...
La ragione del perche' non e' una buona idea e' che, se si e' decisi ad usare lo stesso datamodule in un report, non esiste un oggetto entryfield nel report. Si puo' desiderare di usare il datamodule su una differente form --- il nome dell'entryfield e' sempre lo stesso nelle varie mappe ?
Sommario
Questo documento non ha avuto l'intenzione di essere esaustivo per gli sviluppatori, ma piu' che altro e' stato creato affinche' gli sviluppatori nuovi al Visual dBase e/o nuovi al modello OODML del Visual Dbase 7 familiarizzino con gli oggetti Dati . Io spero che quello che ho scritto qui sia impiegato in maniera appropriata dove meglio la potenza di questi strumenti si ritenga possa essere applicata e che si possano quindi migliorare le proprie applicazioni basate su questa nuova conoscenza.
Vi sono molti riferimenti ad altri documenti presenti nel sito web dell'autore, questi documenti possono essere trovati a:
http://www.mindspring.com/~hirschv/dbase/dbase.htm
In piu', non posso che suggerire, in maniera decisa, che si legga anche, se non lo si e' gia' fatto, l'OODML.HOW di Alan Katz, che copre molta della teoria del modello ad oggetti dei dati in Visual dBase 7.
AVVISO: l'autore e' membro del dBVIPS (dBASE Volunteer Internet Peer Support) -- un gruppo di volontari che fornisce supporto tecnico per dBase Inc. sui newsgroup del Visual dBase (news.dbase2000.com). Se si hanno quesiti da porre riguardanti questo documento .HOW, o sul Visual dBase si puo' comunicare direttamente con l'autore e con i dBVIPS negli appropriati newsgroup su internet. Il supporto tecnico non e' generalmente fornito per mezzo di e-mail privati inviati dai membri del dBVIPS.
.HOW files sono creati come un servizio gratuito dai membri del dBVIPS per aiutare gli utenti ad usare in maniera piu' completa il Visual dBase. Essi sono curati sia dai membri del dBVIPS che dal Supporto Tecnico di dBASE, Inc. (per assicurare qualita'). Questo .HOW NON PUO'ESSERE PUBBLICATO senza il permesso esplicito dell'autore, che conserva tutti i diritti sul documento.
Copyright 1999, Kenneth J. Mayer. All rights reserved.
Informazioni su dBASE, Inc. Possono essere trovate a:
EoHT: BEGDATA.HTM -- March 15, 1999 -- KJM (traduzione in italiano di Santo Lo Galbo - 30 luglio 1999)