ASPETTI PRATICI DEGLI ALGORITMI GENETICI
Quando si progetta un’applicazione con i GA, bisogna
considerare più degli aspetti teorici descritti prima. Ogni
applicazione avrà bisogno della propria funzione fitness, come
già detto, ma ci sono molti problemi pratici specifici con i
quali lavorare. Molti dei passi di un GA tradizionale possono
essere implementati usando un numero di differenti algoritmi. Per
esempio la popolazione iniziale può essere scelta a caso oppure
con un qualche metodo euristico.
Ora descriveremo alcuni metodi per selezionare due individui per
l’accoppiamento. Per capire i motivi dietro queste tecniche,
descriveremo prima i problemi che esse cercano di superare.
Questi problemi sono legati alla funzione fitness, di cui ora
parleremo più in dettaglio.
Funzione Fitness
Insieme allo schema di codice usato, la funzione fitness è l’aspetto
cruciale di ogni GA. Molta ricerca si è concentrata sull’ottimizzazione
di tutte le parti dei GA, poiché i miglioramenti possono essere
applicati a una varietà di problemi. Frequentemente,
comunque, si è trovato che solo un piccolo miglioramento del
comportamento può essere fatto. Grefenstette ha indicato un
insieme di parametri ottimali (crossover, mutazione, popolazione,
etc), ma ha concluso che i meccanismi di base di un GA sono così
robusti che, entro margini abbastanza grandi, i parametri non
sono critici. Quello che è critico nel comportamento di un
Ga è invece la funzione fitness e lo schema di codifica usato.
Idealmente, vogliamo che la funzione fitness sia piatta e
regolare, così che i cromosomi con fitness ragionevole siano
vicini (nello spazio dei parametri) ai cromosomi con fitness
leggermente migliore. Per molti problemi di interesse, purtroppo,
non è possibile costruirla con questo andamento (se fosse
possibile converrebbe usare il metodo hillclimb). Inoltre,
perché i GA funzionino bene dovremmo trovare il modo per
costruire funzioni fitness che non abbiano troppi massimi locali
e che abbiano un massimo locale troppo isolato.
La regola generale per costruire la funzione fitness, è che essa
dovrebbe riflettere il valore reale del cromosoma in qualche
maniera. Come detto sopra, per molti problemi, la costruzione può
essere un passo ovvio, ad esempio in certi casi basta
calcolare il valore di ogni cromosoma. Ma il valore reale di un
cromosoma, non sempre è una quantità utile per guidarci nella
ricerca genetica. In problemi di ottimizzazione combinatoria, ci
sono molti vincoli. E molti punti nello spazio rappresentano
cromosomi non validi, e perciò hanno valore “reale”
zero.
Un esempio è la stesura di un orario scolastico. A un certo
numero di classi deve venire assegnato un certo numero di lezioni,
avendo un numero finito di aule e lettori. Molte assegnazioni
delle classi e dei lettori alle aule saranno violate, ad esempio
se un’aula e stata assegnata a due classi o un lettore è
stato messo in due posti contemporaneamente, o se a una classe
non sono state assegnate tutte le lezioni che dovrebbe svolgere.
Perché un GA sia efficace in questo caso, dobbiamo inventare una
funzione dove il fitness di un cromosoma è visto in funzione di
quanto è in grado di portarci verso un cromosoma valido.
Dobbiamo sapere dove si trovano i cromosomi validi per
assicurarci che ai punti vicini può essere assegnato un buon
valore di fitness. Ma se non sappiamo dove sono i cromosomi
validi, ciò non può essere fatto.
Cramer ha suggerito che se il naturale obiettivo di un problema
è tutto-o-niente, risultati migliori possono essere
ottenuti se inventiamo sotto-obiettivi significativi, e li
ricompensiamo. Nel problema dell’orario, per esempio,
potremmo dare un compenso a ogni classe a cui sono state
regolarmente assegnate tutte le lezioni.
Un altro approccio è quello di considerare una funzione penalità,
che rappresenta quanto i cromosomi sono inadeguati e costruisce
la funzione fitness come: (costante
– penalità).
Secondo alcuni è più utile considerare quanti vincoli sono
violati piuttosto che quanti sono soddisfatti. Una buona funzione
di penalità può essere costruita a partire dal costo di
completamento stimato, cioè il costo necessario (stimato) per
far diventare valido un cromosoma che non lo è.
La stima di funzioni approssimate è una tecnica che può qualche
volta essere usata per se la funzione fitness è troppo complessa
o lenta da valutare. Se può essere creata una funzione più
veloce che approssimativamente dà il valore della funzione
fitness “vera”, il GA può trovare, in un dato tempo di
CPU, un cromosoma migliore di quello che avrebbe trovato usando
la vera funzione fitness. Se per esempio la funzione semplificata
è 10 volte più veloce possono essere stimati 10 punti
approssimati invece di valutare un solo punto esattamente,
e questo è generalmente meglio, infatti un GA è abbastanza
robusto da convergere anche in presenza del “rumore” (noise)
introdotto dall’approssimazione. Questa tecnica è stata
usata per la registrazione di immagini mediche, dove volendo
allineare due immagini i risultati migliori sono stati ottenuti
testando solo un millesimo dei pixel.
Questa tecnica deve essere usata dove la funzione fitness è
stocastica. Per esempio, se il problema è trovare un insieme di
buone regole per un gioco, la funzione fitness deve essere
trovata usandole contro un avversario. Ma ogni partita sarà
diversa, così sarà possibile trovare solo un fitness
approssimato delle regole del gioco. Goldberg ha descritto anche
altre tecniche che usano per esempio una computazione
incrementale basata sul fitness dei genitori.
Problemi di Fitness Range
All’inizio di un’esecuzione, i valori per ciascun
gene dei diversi membri della popolazione sono casualmente
distribuiti. Conseguentemente, c’è una grande propagazione
di fitness individuali. Come l’algoritmo progredisce
particolari valori per ogni gene cominciano a predominare. Mentre
la popolazione converge, il range del fitness si riduce. La
variazione nel range del fitness spesso porta a problemi di
convergenza prematura o fine lenta.
Convergenza Prematura
Un classico problema con i GA è che i geni provenienti da
pochi individui con un fitness comparabilmente alto (ma non
ottimale) possono rapidamente dominare la popolazione, causando
la convergenza a un massimo locale. Una volta che la popolazione
converge, l’abilità del GA di continuare la ricerca per una
soluzione migliore è effettivamente eliminata: il crossover di
individui quasi identici può portare ben pochi miglioramenti.
Solo la mutazione rimane per poter esplorare nuove zone, e questo
semplicemente porta a una ricerca lenta e casuale.
Il teorema dello schema dice che dovremmo allocare prove
riproduttive (o opportunità) in proporzione al loro fitness
relativo. Ma quando lo facciamo si verifica una convergenza
prematura a causa del fatto che la popolazione non è infinita.
Per far lavorare bene il GA su una popolazione finita, dobbiamo
modificare la maniera con cui vengono scelti gli individui per la
riproduzione.
L’idea base è che dobbiamo controllare il numero di
opportunità che ogni individuo riceve in modo che non sia né
troppo basso né troppo alto. L’effetto è quello di
restringere il range del fitness che un qualsiasi individuo
“superfit” possa improvvisamente prevalere.
Fine lenta
Questo problema è opposto al precedente. Dopo molte
generazioni, la popolazione sarà convergente, ma non avrà
localizzato precisamente il massimo locale. Il fitness medio sarà
alto, ma ci sarà poca differenza tra la media e il miglior
individuo. Conseguentemente ci sarà un insufficiente gradiente
nella funzione fitness, per spingere il GA verso il massimo.
Le stesse tecniche usate per combattere la convergenza prematura
combattono anche questo problema. Lo fanno espandendo il range
effettivo del fitness nella popolazione. Come con la prematura
convergenza, il fitness scaling può portare a sovracompressione
(o sottoespansione) dovuta a un individuo “super poor”
(molto scadente).
Tecniche di Selezione dei Genitori
La selezione dei genitori è il compito di allocare opportunità
riproduttive a ciascun individuo. In principio, gli individui
sono copiati dalla popolazione in una “piscina di
accoppiamento” (mating pool), dove gli individui migliori
hanno molta probabilità di essere copiati più volte, mentre i
peggiori potrebbero non essere copiati affatto. Sotto un severo
schema di riproduzione, la dimensione della mating pool è uguale
a quella della popolazione. Dopo di ciò, coppie di individui
vengono tirati fuori dalla piscina e fatti accoppiare. Questo
viene ripetuto finché la piscina rimane vuota.
Il comportamento di un GA molto dipende da come gli individui
vengono scelti per andare nella mating pool. I modi di farlo
possono essere divisi in tre. Il più semplice di
questi è il “roulette wheel selection”, nel quale i
genitori sono selezionati in base al loro fitness: i migliori
cromosomi hanno maggiore probabilità di essere selezionati,
possiamo immaginare una roulette dove vengono piazzati tutti i
cromosomi, ognuno dei quali occupa uno spazio grande in
proporzione al suo fitness. Poi “si lancia la pallina”
e si seleziona il cromosoma, quindi i cromosomi con alto fitness
possono essere selezionati più volte. Possiamo ora scrivere un
algoritmo:
(1) S= somma del fitness di tutti i cromosomi
LOOP:
(2) r= numero a caso nell’intervallo (0,S)
(3) Vai attraverso la popolazione e somma i fitness da zero (somma=s);
se s>r fermati e restituisci il cromosoma dove sei.
In un altro metodo possiamo prendere il punteggio di fitness di
ciascun individuo, rilevato su una nuova scala, e si usa
questo valore rimappato come numero di copie che vanno nella
mating pool. Un altro metodo ancora produce un simile effetto, ma
senza passare attraverso il passo di calcolare una fitness
modificato. Possiamo chiamare questi metodi fitness rimappato
implicitamente e fitness rimappato esplicitamente.
Fitness Rimappato Esplicitamente
Per fare in modo che la mating pool abbia la stessa dimensione
della popolazione originale, la media del numero di prove
riproduttive allocate a ogni individuo deve essere uno. Se
il fitness di ogni individuo è rimappato dividendo per la media
del fitness della popolazione, questo effetto è ottenuto. Questo
schema di rimappamento alloca prove riproduttive in proporzione
al fitness grezzo, in accordo con la teoria ddi Holland.
Prima di discutere altri schemi di rimappamento, c’è un
aspetto pratico che va chiarito. Il fitness rimappato di ogni
individuo, in generale, non sarà un intero. Poiché solo un
numero intero di copie può essere piazzata nel mating pool,
dobbiamo convertire il numero in un intero in modo da non
introdurre deviazione. Una gran quantità di lavoro è stata
fatta per trovare il modo migliore per farlo.
Un metodo largamente usato è “stochastic universal sampling
without replacement” (campionamento stocastico universale
senza rimpiazzamento).
Un metodo migliore è “universal stocastic sampling” (campionamento
stocastico universale), un metodo elegante e teoricamente
perfetto.
E’ importante non confondere il metodo sampling con la
selezione dei genitori. Differenti metodi di selezione dei
genitori, saranno buoni per molte applicazioni, ma un buon
sampling è sempre buono, per tutti i metodi di selezione.
Come già detto, non vogliamo allocare prove riproduttive a
individui in maniera direttamente proporzionale al fitness grezzo.
Ecco alcuni metodi.
Fitness Scaling è un metodo molto usato: il massimo numero di
prove riproduttive allocato a un individuo è impostato a un
certo valore, tipicamente 2. Questo è ottenuto sottraendo un
numero appropriato a dal valore di fitness grezzo, poi dividendo
la media del valore di fitness aggiustato. Sottraendo un importo
fisso aumenta il rapporto massimo/media del fitness. Deve essere
posta attenzione per non generare fitness negativi.
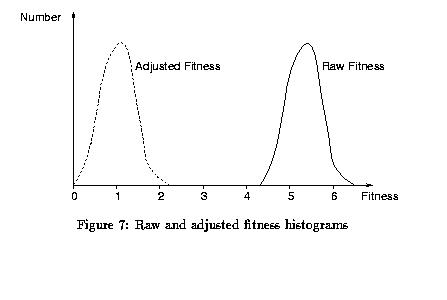
La figura 7 mostra un istogramma del fitness grezzo con una media
di 5.4, massimo 6.5 e ciò produce un rapporto massimo/media del
fitness di1.2, così che ci si aspetta che il maggior numero di
individui riceverà 1.2 prove di riproduzione. Per applicare il
fitness scaling (sarebbe meglio chiamarlo fitness shifting)
sottraiamo (2xmedia-massimo)= 4.3 da tutti i fitness. Questo da l’istogramma
del fitness aggiustato con media 1.1 massimo 2.2 e rapporto
massimo/media del fitness 2.
Il fitness scaling tende a comprimere il range all’inizio,
poi lentamente converge giù e aumenta la quantità di
esplorazioni.
Comunque, la presenza di un solo super fit (con fitness anche 10
volte superiore agli altri), può portare a sovracompressione. Se
la scala del fitness è compressa il rapporto massimo/media del
fitness è 2:1 allora resto della popolazione avrà fitness
abbastanza vicino a 1 . Sebbene abbiamo prevenuto la convergenza
prematura, abbiamo fatto questo a spese dell’effettiva
oscillazione fuori dalla funzione fitness. Come detto prima, se
la funzione fitness è troppo oscillante, il genetic drift
diventerà un problema, e la sovracompressione porterà non solo
a una performance più lenta, ma ci allontanerà dall’ottimo.
Fitness windowing è usato nel programma GENESIS di Grefenstette.
Questo funziona come il fitness scaling, eccetto che la somma da
sottrarre è scelta differentemente. Il minimo del fitness in
ogni generazione viene ricordato e viene sottratto il minimo
fitness osservato nelle precedenti n generazioni, dove di solito
n=10. Con questo schema la pressione di selezione (cioè il
rapporto massimo/media delle prove di riproduzione allocate) vaia
durante l’esecuzione, e anche tra problema e problema.
La presenza di un super-unfit può provocare sottoespansione,
mentre la presenza di un super-fit, prematura convergenza, perché
non c’è influenza nel grado di scala applicato.
Il problema con entrambi scaling e windowing è che il grado di
compressione dipende da un singolo, estremo individuo, sia esso
il migliore o il peggiore. Le performance peggioreranno se l’individuo
è eccezionalmente estremo.
Fitness Ranking è un altro metodo comune che evita di
appoggiarsi su un individuo estremo. Gli individui sono ordinati
a seconda del fitness grezzo, cioè il peggiore individuo avrà
fitness 1, il secondo peggiore 2 e il migliore N (numero di
cromosomi nella popolazione) e allora i valori di fitness
riproduttivo saranno assegnati in accordo al rango. Questo può
essere fatto linearmente o esponenzialmente e dà un risultato
simile al fitness scaling, in questo il rapporto massimo/media
del fitness è normalizzato a un particolare valore. Inoltre ci
assicura che il fitness rimappato di un individuo intermedio sarà
regolarmente propagato. A causa di questo l’effetto di uno o
due individui estremi sarà trascurabile, indipendentemente da
quanto piccolo o grande sia il valore del loro fitness in
rapporto al resto della popolazione, in questo modo i migliori
cromosomi non differiscono molto dagli altri e questo può
rallentare molto la convergenza. Il numero di prove riproduttive
allocate, per esempio, al quinto miglior individuo sarà
sempre lo stesso, qualunque sia il valore di fitness dei punti
sopra o sotto. L’effetto è che la sovracompressione cessa
di essere un problema.
Alcuni esperimenti dimostrano che il ranking è superiore al
fitness scaling.
Situazione prima del Ranking
Dopo il Ranking
Rimappamento Implicito del fitness
Questo metodo riempie la mating pool senza passare attraverso
livelli intermedi di rimappamento del fitness.
Tournament Selection è una di queste tecniche. Ci sono alcune
varianti, nella più semplice “selezione binario di torneo”,
coppie di individui sono prese a caso tra la popolazione.
Chiunque abbia un alto fitness viene copiato nella mating pool (
e insieme vengono sostituiti nella popolazione originale) e
questo è ripetuto finché la piscina non è piena. Tornei più
grandi possono essere usati, dove il migliore di n individui
scelti a caso è copiato nella mating pool, e questo ha l’effetto
di aumentare la pressione di selezione, perché gli individui
sotto la media difficilmente vinceranno i tornei, mentre i
migliori avranno ottime probabilità.
Un ulteriore generalizzazione è la selezione con torneo binario
statistico, dove i migliori individui vincono i tornei con
probabilità p dove 0.5<p<1. Usando valori più bassi
di p si diminuisce la pressione di selezione, perché gli
individui sotto la media sono in proporzione più avvantaggiati
nel vincere un torneo, mentre quelli sopra la media perdono
probabilità.
Aggiustando la probabilità di vincere o la dimensione del torneo,
la pressione di selezione può essere resa grande o piccola a
piacere.
Goldberg e Deb hanno confrontato quattro differenti schemi:
selezione proporzionale, fitness ranking, tournment selection e
steady state selection (vedi dopo) e hanno concluso che tramite
opportuni aggiustamenti dei parametri, tutti gli schemi (tranne
la selezione proporzionale), hanno performance simili, quindi non
c’è una tecnica migliore in assoluto.
Generation gaps e steady-state replacement
Il gap generazionale può essere definito come la percentuale
di popolazione che viene sostituita a ogni generazione. Molto
lavoro è stato fatto con gap 1 cioè ogni volta viene sostituita
l’intera generazione, ma un nuovo trend preferisce un
rimpiazzamento steady-state (stato stabile). Questo opera al
contrario, cioè solo pochi individui vengono sostituiti ogni
volta.
Questo può essere un migliore modello di quello che avviene in
natura, nelle specie con una breve vita, come alcuni insetti, i
genitori depongono le uova e muoiono prima di vedere i figli, ma
nelle specie con una vita più lunga figli e genitori convivono.
Questo permette ai genitori di crescere i figli e istruirli, ma
crea anche competizione tra loro.
In questo caso, non dobbiamo considerare solo come
individuare due genitori, ma dobbiamo anche selezionare degli
individui sfortunati perché muoiano e lascino spazio ai figli.
Ecco alcuni degli schemi possibili:
1. si selezionano i genitori secondo il fitness, e si
rimpiazza a caso
2. si selezionano i genitori a caso, e la selezione per il
rimpiazamento viene fatta considerando l’inverso del fitness
3. si selezionano i genitori e i rimpiazzandi secondo il criterio
fitness/ inverso del fitness.
Per esempio l’algoritmo di Whiley GENITOR, seleziona i
genitori secondo il loro rango di fitness e i figli rimpiazzano i
due peggiori membri della popolazione.
L’essenziale differenza tra un convenzionale, generazionale
rimpiazzamento in un GA e un steady-state GA, è che nel secondo
caso le statistiche della popolazione (ad esempio il fitness
medio) sono ricalcolate dopo ogni accoppiamento (questo è
computazionalmente più dispendioso se fatto incrementalmente), e
i nuovi figli sono subito pronti per la riproduzione. Un così
fatto GA ha l’opportunità di sfruttare un individuo
promettente non appena viene creato.
Comunque gli studi di Goldberg e Deb hanno trovato che i vantaggi
della tecnica steady-state sembrano essere correlati all’alto
tasso di crescita iniziale. Lo stesso effetto può essere
ottenuto, dicono, usando un fitness ranking esponenziale, o una
selezione con un torneo di grande taglia, e non hanno trovato
nessuna prova che il rimpiazzamento steady-state sia
fondamentalmente migliore del generazionale.